
Hey, community! 👋
My name is Randy Pettus, and I'm a principal data scientist in Denver, Colorado. Before transitioning into the world of data science, I worked in finance and taught college finance courses, including one called "The Investment Strategies of Warren Buffett."
When Streamlit announced the 2023 Snowflake Streamlit Hackathon, I decided to create an app allowing users to explore Warren Buffett's world. I did it in less than a day, and it won second place! 🥈
In this post, I'll show you:
- How to create a Snowflake database, schema, and virtual warehouse
- How to load data into Snowflake using Snowpark Python and obtain the associated DDL statements
- How to create embeddings from DDL statements and load them into a vector database (FAISS)
- How to create embeddings from PDFs and load them into a vector database (Pinecone)
- How to perform questioning/answering on these docs using OpenAI and LangChain
- How to put it all together
What is Ask the Oracle of Omaha?
So, what is this app exactly, and what does it do?
The app offers various LLM functionalities, such as LLM-augmented retrieval from data in a Snowflake database and PDF documents. You can access financial statement information for multiple companies Buffet has invested in through a KPI view or by asking natural language questions. And you can query Buffet's shareholder letters going back to 1977.
Go ahead and try it:
As you can see, there are three main tabs:
- 💵 Financial statement natural language querying: Converts user questions into Snowflake SQL and returns DataFrame outputs. The approach uses semantic search on DDL statements stored in a vector database and uses LLM-generated SQL to query Snowflake directly.
- 📈 Financial data exploration: Users can examine financial statement information through KPI cards, charts, and so on, pulled from Snowflake.
- 📝 Shareholder letter natural language querying: This performs question and answering using retrieval augmented generation from Buffet's shareholder letters stored as PDFs dating back to 1977.
Before we dive into coding, let's take a quick high-level view of the app.
App overview
Here is how all the app components fit together:
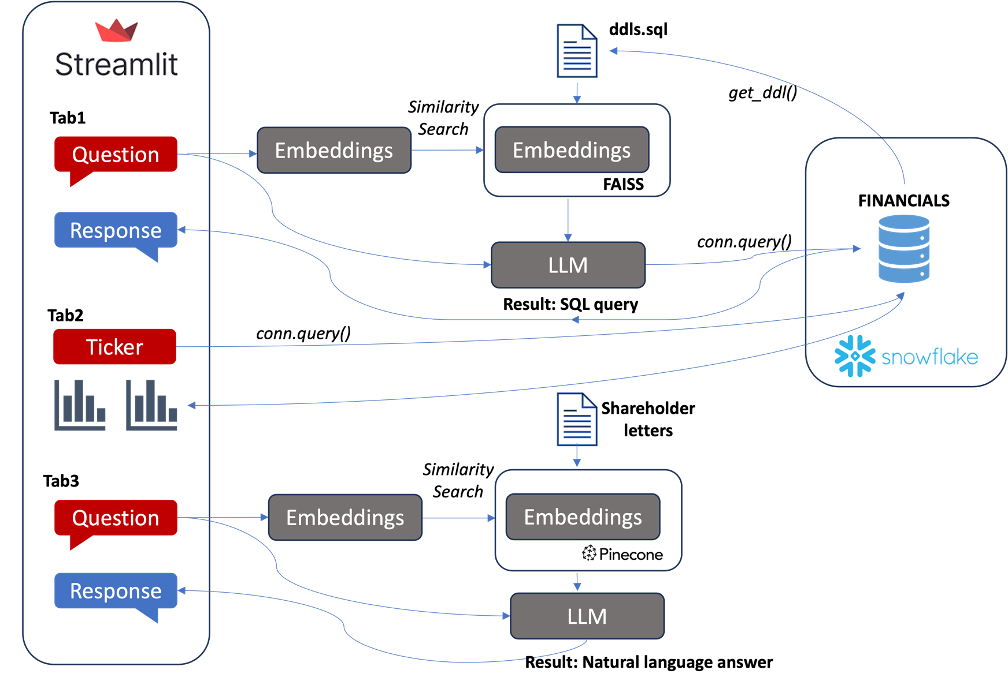
How to use the app
Here are a few examples that show how the app functions.
Say, you want to inquire about the financial performance of certain companies. In the first tab, type "Rank the companies in descending order based on their net income in 2022. Include the ticker and net income value."
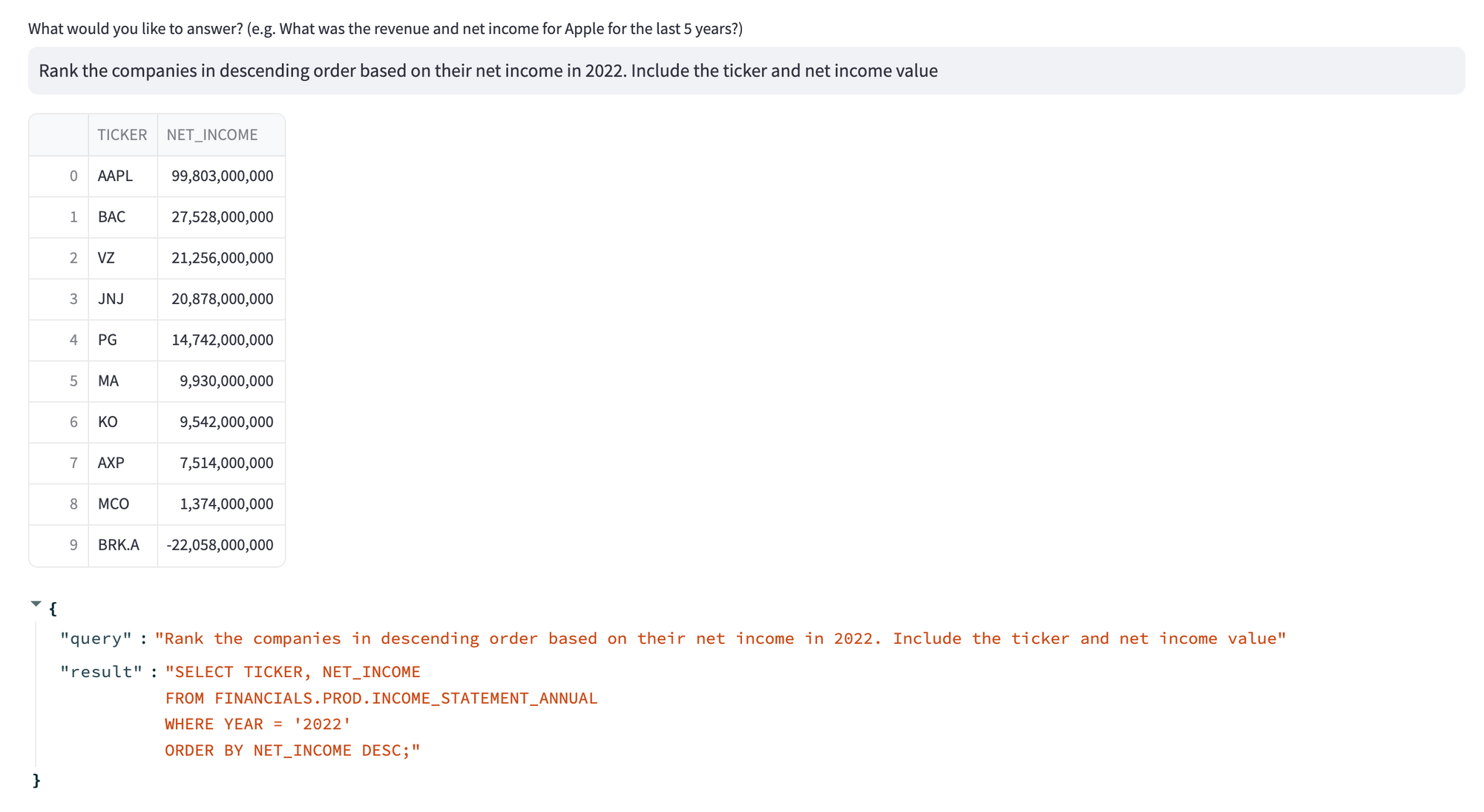
Great! You just got a DataFrame back from Snowflake with the correct results.
Now, say you want to explore the shareholder letters. Let's use this random 1984 letter:

Type in, "Where did Mrs. B receive her honorary doctorate, and what was her job role?"

Awesome! The app gave you the correct answer.
Let's move on to building it.
1. How to create a Snowflake database, schema, and virtual warehouse
1.1. Accounts
To start, you'll need a Snowflake account, an OpenAI account, and a Pinecone account. Go ahead and create them if you don't have them.
1.2. Python packages
Next, install the following Python packages:
# requirements.txt
altair
snowflake-connector-python
snowflake-sqlalchemy
snowflake-snowpark-python[pandas]==1.5.1
numpy
pandas
matplotlib
seaborn
openai
streamlit_chat
langchain==0.0.124
pinecone-client
sqlalchemy
faiss-cpu
1.3. Secrets management
To use your Snowflake credentials, create a .streamlit/secrets.toml file in the following format (read more here). The [connections.snowpark] section should be filled out with your Snowflake credentials. The setting client_session_keep_alive = true keeps the session active, which helps avoid connection timeout issues.
#.streamlit/secrets.toml
openai_key = "########"
pinecone_key = "########"
pinecone_env = "########"
sf_database = "FINANCIALS"
sf_schema = "PROD"
[connections.snowpark]
account = "########"
user = "########"
password = "########"
warehouse = "########"
database = "########"
schema = "########"
client_session_keep_alive = true
1.4. Data loading
Finally, enable the loading of financial statement data in Snowflake. After creating your Snowflake account, you must create a database, schema, and virtual warehouse. Snowflake uses the virtual warehouse to execute virtual warehousee on your data. You can run the following SQL commands in a UI worksheet (remember to include them in your secrets file).
create database FINANCIALS;
create schema PROD;
-- create an extra small warehouse
CREATE WAREHOUSE if not exists WH_XS_APP
with
WAREHOUSE_SIZE = XSMALL
AUTO_SUSPEND = 60
INITIALLY_SUSPENDED = TRUE
COMMENT = 'APPLICATION WAREHOUSE'
;
2. How to load data into Snowflake using Snowpark Python and obtain the associated DDL statements
Publicly traded companies file their financial statements—income, balance sheet, cash flow—with the Securities Exchange Commission (SEC). I sourced my data from SEC Edgar (see the CSV files in my repo). Consider it test data, as it might not be completely accurate. If you want a more reliable source, there are various services and APIs available for obtaining financial statement data, including Cybersyn on the Snowflake Marketplace.
In my repo, you'll see three folders under the .load/financials directory for each financial statement type and a .csv file for each company (ticker) within each folder.
With that in mind, create a stock_load.py file that does the following:
- Establishes a Snowflake Snowpark connection and session.
- Loops through each financial statement folder to load the CSV as a Pandas DataFrame.
- Uses the session.create_dataframe() and save_as_table() Snowpark functionality to create a Snowflake table for each financial statement while loading the data from the dataframes.
- Creates a DDL file to make embeddings for LLM interaction. This step loops through each created table and gets the DDL information from Snowflake. All DDL statements are consolidated into a single ddls.sql file.
# stock_load.py
import os
import glob
import numpy as np
import pandas as pd
import snowflake.connector
from snowflake.connector.pandas_tools import write_pandas
from snowflake.snowpark.session import Session
import streamlit as st
# snowpark connection
CONNECTION_PARAMETERS = {
"account": st.secrets['account'],
"user": st.secrets['user'],
"password": st.secrets['password'],
"database": st.secrets['database'],
"schema": st.secrets['schema'],
"warehouse": st.secrets['warehouse'],
}
# create session
session = Session.builder.configs(CONNECTION_PARAMETERS).create()
# create a list of the statements which should match the folder name
statements = ['INCOME_STATEMENT_ANNUAL','BALANCE_SHEET_ANNUAL',
'CASH_FLOW_STATEMENT_ANNUAL']
# Load data into snowflake by looping through the csv files
for statement in statements:
path = f'./load/financials/{statement.lower()}/'
files = glob.glob(os.path.join(path, "*.csv"))
df = pd.concat((pd.read_csv(f) for f in files))
print(statement)
# note that overwrite is used to start. If adding future data, move to append with upsert process
session.create_dataframe(df).write.mode('overwrite').save_as_table(statement)
# automatically get the ddl from the created tables
# create empty string that will be populated
ddl_string = ''
# run through the statements and get ddl
for statement in statements:
ddl_string += session.sql(f"select get_ddl('table', '{statement}')").collect()[0][0] + '\\n\\n'
ddl_file = open("ddls.sql", "w")
n = ddl_file.write(ddl_string)
ddl_file.close()
After running this, your FINANCIALS.PROD schema should contain populated tables:

You must also create a local ddls.sql file with "create table" commands for each table. This file is crucial in providing context for the LLM about the database structure, including the various tables, columns, and data types.
Here is a snippet of this output:
create or replace TABLE FINANCIALS.PROD.INCOME_STATEMENT_ANNUAL (
TICKER VARCHAR(16777216),
...
3. How to create embeddings from DDL statements and load them into a vector database (FAISS)
This step aims to provide an efficient means of translating a question into relevant Snowflake SQL code. My original solution, which relied on Langchain's SQLDatabase and SQLDatabaseChain functionality to interact directly with Snowflake, wasn't optimal. It kept pulling information schema from Snowflake, producing too much context for OpenAI inputs to generate SQL code. So it unnecessarily wasted OpenAI tokens and Snowflake credits (find the original solution here).
The create_ddl_embeddings.py script below uses Langchain's TextLoader() functionality to load the ddls.sql file. The text is split into characters and documents and converted into embeddings using OpenAIEmbeddings(). The embeddings are stored in FAISS, an open-source vector database.
Running this script produces two files: index.faiss and index.pkl, both located in the faiss_index folder (used later for the question and retrieval pipeline):
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
import streamlit as st
# load the ddl file
loader = TextLoader('load/ddls.sql')
data = loader.load()
# split the text
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20)
texts = text_splitter.split_documents(data)
# created embeddings from the sql document
embeddings = OpenAIEmbeddings(openai_api_key = st.secrets["openai_key"])
docsearch = FAISS.from_documents(texts, embeddings)
# save the faiss index
docsearch.save_local("faiss_index")
4. How to create embeddings from PDFs and load them into a vector database (Pinecone)
Let's move on to the shareholder letters (find them here or in my repo).
Your pinecone.io account offers a free index. To set up the prompts, get the Pinecone API key, the Pinecone environment variable, and the index name (remember to store these keys in your .secrets file).
Create the letter_load.py script, which produces embeddings from the various letters and loads them into Pinecone:
import os
from langchain.document_loaders import PyPDFLoader # for loading the pdf
from langchain.embeddings import OpenAIEmbeddings # for creating embeddings
from langchain.vectorstores import Pinecone # for the vectorization part
from langchain.text_splitter import TokenTextSplitter
import pinecone
import streamlit as st
# identify the various pdf files
pdfs = [file for file in os.listdir('./letters/') if 'pdf' in file]
# loops through each pdf in the letters directory
# and loops the content using langchains PyPDFLoader
page_list = []
for pdf in pdfs:
pdf_path = f"./letters/{pdf}"
loader = PyPDFLoader(pdf_path)
pages = loader.load()
page_list.append(pages)
flat_list = [item for sublist in page_list for item in sublist]
text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(flat_list)
# initialize pinecone
pinecone.init(
api_key=st.secrets['pinecone_key'],
environment=st.secrets['pinecone_env']
)
index_name = "buffett"
# note you should create an OPENAI_API_KEY env environment variable or use st.secrets
# create embeddings using OpenAI and load into Pinecone
embeddings = OpenAIEmbeddings(openai_api_key=st.secrets['openai_key'])
docsearch = Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name)
The script above loops through each letter and extracts text using Langchain's PyPDFLoader. The text is consolidated into a flattened list, and TokenTextSplitter chunks it. OpenAIEmbeddings is used again to create the embeddings, which are then loaded into Pinecone using langchain.vectorstores.Pinecone() and the page_content in each text split. Ideally, you'd use LangChain's DirectoryLoader for this, but package dependency issues cause delays. Running this script may take a few minutes, but once completed, you should see the index populated in Pinecone.
5. How to perform questioning/answering on these docs using OpenAI and LangChain
Create a new file called prompts.py, which uses LangChain and OpenAI to enable question and answer retrieval.
This script covers the following steps:
- Creating prompt templates to provide better guidance for the large language model. The FS_TEMPLATE offers specific instructions for the LLM to produce better Snowflake SQL results from the financial statements, including an example of a single-shot prompt.
- Defining OpenAI parameters for the LLM.
- Identifying the vector databases for retrieval, including the FAISS stored embeddings (get_faiss) and Pinecone vector database (get_pinecone).
- Creating a question/answer chain using Langchain's RetrievalQA functionality. The fs_chain() and letter_chain() functions take questions as inputs for the financial statements and shareholder letters, respectively. These functions are designed to retrieve the k most similar embeddings to the question while providing a natural language response. For fs_chain(), the result is a SQL query command, which you'll use for querying financial statement data in Snowflake. For letter_chain(), the output will include a text response for the question.
import streamlit as st
import openai
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS, Pinecone
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
import pinecone
FS_TEMPLATE = """ You are an expert SQL developer querying about financials statements. You have to write sql code in a Snowflake database based on the following question.
display the sql code in the SQL code format (do not assume anything if the column is not available, do not make up code).
ALSO if you are asked to FIX the sql code, then look what was the error and try to fix that by searching the schema definition.
If you don't know the answer, provide what you think the sql should be. Only include the SQL command in the result.
The user will request for instance what is the last 5 years of net income for Johnson and Johnson. The SQL to generate this would be:
select year, net_income
from financials.prod.income_statement_annual
where ticker = 'JNJ'
order by year desc
limit 5;
Questions about income statement fields should query financials.prod.income_statement_annual
Questions about balance sheet fields (assets, liabilities, etc.) should query financials.prod.balance_sheet_annual
Questions about cash flow fields (operating cash, investing activities, etc.) should query financials.prod.cash_flow_statement_annual
The financial figure column names include underscores _, so if a user asks for free cash flow, make sure this is converted to FREE_CASH_FLOW.
Some figures may have slightly different terminology, so find the best match to the question. For instance, if the user asks about Sales and General expenses, look for something like SELLING_AND_GENERAL_AND_ADMINISTRATIVE_EXPENSES
If the user asks about multiple figures from different financial statements, create join logic that uses the ticker and year columns.
The user may use a company name so convert that to a ticker.
Question: {question}
Context: {context}
SQL: ```sql ``` \\n
"""
FS_PROMPT = PromptTemplate(input_variables=["question", "context"], template=FS_TEMPLATE, )
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0.1,
max_tokens=1000,
openai_api_key=st.secrets["openai_key"]
)
def get_faiss():
"""
get the loaded FAISS embeddings
"""
embeddings = OpenAIEmbeddings(openai_api_key=st.secrets["openai_key"])
return FAISS.load_local("faiss_index", embeddings)
def get_pinecone():
"""
get the pinecone embeddings
"""
pinecone.init(
api_key=st.secrets['pinecone_key'],
environment=st.secrets['pinecone_env']
)
index_name = "buffett"
embeddings = OpenAIEmbeddings(openai_api_key=st.secrets["openai_key"])
return Pinecone.from_existing_index(index_name,embeddings)
def fs_chain(question):
"""
returns a question answer chain for faiss vectordb
"""
docsearch = get_faiss()
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=docsearch.as_retriever(),
chain_type_kwargs={"prompt": FS_PROMPT})
return qa_chain({"query": question})
def letter_chain(question):
"""returns a question answer chain for pinecone vectordb"""
docsearch = get_pinecone()
retreiver = docsearch.as_retriever(#
#search_type="similarity", #"similarity", "mmr"
search_kwargs={"k":3}
)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=retreiver,
chain_type="stuff", #"stuff", "map_reduce","refine", "map_rerank"
return_source_documents=True,
#chain_type_kwargs={"prompt": LETTER_PROMPT}
)
return qa_chain({"query": question})
You'll see in the letter_chain() function that additional retrieval parameters are included. Due to the size of the letters, it is important to ensure a balance of getting enough coverage while not going over any token limitations with OpenAI to retrieve this case's three most similar embeddings and set the 'k' value to 3 in the search_kwargs arguments.
6. How to put it all together
Now that you can perform question and answering using the prompts.py file, it's time to create the main app file: buffett_app.py.
First, import the appropriate packages and set the Streamlit page layout to "wide." Then define some variables, including your Snowflake database, schema, and the various tickers used. Then, establish the Snowflake Snowpark connection using experimental_connection().
import snowflake.connector
import numpy as np
import pandas as pd
import streamlit as st
import altair as alt
import prompts
st.set_page_config(layout="wide")
# Variables
sf_db = st.secrets["database"]
sf_schema = st.secrets["schema"]
tick_list = ['BRK.A','AAPL','PG','JNJ','MA','MCO','VZ','KO','AXP', 'BAC']
fin_statement_list = ['income_statement','balance_sheet','cash_flow_statement']
year_cutoff = 20 # year cutoff for financial statement plotting
# establish snowpark connection
conn = st.experimental_connection("snowpark")
Next, create some helper functions to keep things cleaner:
- pull_financials pulls a financial statement from Snowflake for a specified ticker.
- kpi_recent populates the KPI cards based on the most recent periods for a selected metric.
- plot_financials plots Altair bar charts from a DataFrame.
@st.cache_data()
def pull_financials(database, schema, statement, ticker):
"""
query to pull financial data from snowflake based on database, schema, statemen and ticker
"""
df = conn.query(f"select * from {database}.{schema}.{statement} where ticker = '{ticker}' order by year desc")
df.columns = [col.lower() for col in df.columns]
return df
# metrics for kpi cards
@st.cache_data()
def kpi_recent(df, metric, periods=2, unit=1000000000):
"""
filters a financial statement dataframe down to the most recent periods
df is the financial statement. Metric is the column to be used.
"""
return df.sort_values('year',ascending=False).head(periods)[metric]/unit
def plot_financials(df, x, y, x_cutoff, title):
""""
helper to plot the altair financial charts
"""
return st.altair_chart(alt.Chart(df.head(x_cutoff)).mark_bar().encode(
x=x,
y=y
).properties(title=title)
)
Create a Streamlit sidebar to display relevant information about the app for the user.
Here is an overview of the app's functionality:
with st.sidebar:
st.markdown("""
# Ask the Oracle of Omaha: Using LLMs... :moneybag:
This app enables exploration into the World...
""")
Use Streamlit tabs to break up different sections of the app.
tab1
tab1 provides users with the ability to request financial statement information from Snowflake. The user's question is captured in the str_input variable. Use this input in your prompts.fs_chain() function, which performs similarity matching on the user's question's embedding to find the most relevant SQL DDL embeddings. OpenAI then produces a query text with Snowflake syntax, using this as context. The text is stored in the output['result'], which you pass as an argument to conn.query() to have Snowflake execute the query.
Here is the second attempt (if the first one fails):
# create tabs
tab1, tab2, tab3 = st.tabs([
"Financial Statement Natural Language Querying :dollar:",
"Financial Data Exploration :chart_with_upwards_trend:",
"Shareholder Letter Natural Language Querying :memo:"]
)
with tab1:
st.markdown("""
# Natural Language Financials Querying :dollar:
### Leverage LLMs to translate natural language questions
...
""")
str_input = st.text_input(label='What would you like to answer? (e.g. What was the revenue and net income for Apple for the last 5 years?)')
if str_input:
with st.spinner('Looking up your question in Snowflake now...'):
try:
output = prompts.fs_chain(str_input)
try:
# if the output doesn't work we will try one additional attempt to fix it
query_result = conn.query(output['result'])
if len(query_result) > 1:
st.write(query_result)
st.write(output)
except:
st.write("The first attempt didn't pull what you were needing. Trying again...")
output = prompts.fs_chain(f'You need to fix the code. If the question is complex, consider using one or more CTE. Also, examine the DDL statements and try to correct this question/query: {output}')
st.write(conn.query(output['result']))
st.write(output)
except:
st.write("Please try to improve your prompt or provide feedback on the error encountered")
tab2
tab2 displays financial information for a selected ticker (sel_ticker), which users choose via a Streamlit selectbox. The pull_financials() function retrieves the relevant financial statements from Snowflake for the selected ticker.
To improve readability, use two columns to display four financial metrics. I chose to show net income, net income ratio (profit margin), free cash flow, and debt-to-equity ratio, but you can display any metrics you want. The metrics include the most recent year's value and the change from the previous year as the displayed "delta." Under each metric, the plot_financials() function shows the metric value by year.
Finally, the user can select a financial statement to view the complete data:
with tab2:
st.markdown("""
# Financial Data Exploration :chart_with_upwards_trend:
View financial statement data...
""")
sel_tick = st.selectbox("Select a ticker to view", tick_list)
# pull the financial statements
# This whole section could be more efficient...
inc_st = pull_financials(sf_db, sf_schema, 'income_statement_annual', sel_tick)
bal_st = pull_financials(sf_db, sf_schema, 'balance_sheet_annual', sel_tick)
bal_st['debt_to_equity'] = bal_st['total_debt'].div(bal_st['total_equity'])
cf_st = pull_financials(sf_db, sf_schema, 'cash_flow_statement_annual', sel_tick)
col1, col2 = st.columns((1,1))
with col1:
# Net Income metric
net_inc = kpi_recent(inc_st, 'net_income')
st.metric('Net Income',
f'${net_inc[0]}B',
delta=round(net_inc[0]-net_inc[1],2),
delta_color="normal",
help=None,
label_visibility="visible")
plot_financials(inc_st, 'year', 'net_income', year_cutoff, 'Net Income')
# netincome ratio
net_inc_ratio = kpi_recent(inc_st, 'net_income_ratio', periods=2, unit=1)
st.metric('Net Profit Margin',
f'{round(net_inc_ratio[0]*100,2)}%',
delta=round(net_inc_ratio[0]-net_inc_ratio[1],2),
delta_color="normal",
help=None,
label_visibility="visible")
plot_financials(inc_st, 'year', 'net_income_ratio', year_cutoff, 'Net Profit Margin')
with col2:
# free cashflow
fcf = kpi_recent(cf_st, 'free_cash_flow' )
st.metric('Free Cashflow',
f'${fcf[0]}B',
delta=round(fcf[0]-fcf[1],2),
delta_color="normal",
help=None,
label_visibility="visible")
plot_financials(cf_st, 'year', 'free_cash_flow', year_cutoff, 'Free Cash Flow')
# debt to equity
debt_ratio = kpi_recent(bal_st, 'debt_to_equity', periods=2, unit=1)
st.metric('Debt to Equity',
f'{round(debt_ratio[0],2)}',
delta=round(debt_ratio[0]-debt_ratio[1],2),
delta_color="normal",
help=None,
label_visibility="visible")
plot_financials(bal_st, 'year', 'debt_to_equity', year_cutoff, 'Debt to Equity')
# enable a financial statment to be selected and viewed
sel_statement = st.selectbox("Select a statement to view", fin_statement_list)
fin_statement_dict = {'income_statement': inc_st,
'balance_sheet': bal_st,
'cash_flow_statement':cf_st}
st.dataframe(fin_statement_dict[sel_statement])
tab3
tab3 lets users ask questions about Buffet's shareholder letters. To do this, collect the user's question in the query variable and use the prompts.letter_chain() function. It performs a similarity search with the vectors stored in Pinecone. Using the three most similar embeddings, the OpenAI LLM call produces an answer, if applicable, in the context. The result of this process is a dictionary that contains both the "result" and "source_documents," which are then displayed for the user:
with tab3:
st.markdown("""
# Shareholder Letter Natural Language Querying :memo:
### Ask questions from all of...
These letters are much anticipated...
"""
)
query = st.text_input("What would you like to ask Warren Buffett?")
if len(query)>1:
with st.spinner('Looking through lots of Shareholder letters now...'):
try:
st.caption(":blue[Warren's response] :sunglasses:")
#st.write(prompts.letter_qa(query))
result = prompts.letter_chain(query)
st.write(result['result'])
st.caption(":blue[Source Documents Used] :📄:")
st.write(result['source_documents'])
except:
st.write("Please try to improve your question")
Wrapping up
Thank you for sticking with me until the end! I covered much ground, showing how LLMs can generate meaningful SQL queries and responses from databases like Snowflake. LLMs can also ask questions from various documents and produce meaningful results. The toolsets available for working with LLMs are expanding rapidly, and Streamlit is the perfect tool for demonstrating all of this in one app. Of course, you can improve it by using st.chat and LangChain. Still, it's impressive what you can do in a day!
If you have any questions, please post them in the comments below or contact me on LinkedIn, Twitter, Medium, or GitHub.
Happy Streamlit-ing! 🎈




Comments
Continue the conversation in our forums →