Remember how cool it was playing with an AI image generator for the first time? Those twenty million fingers and nightmare spaghetti-eating images were more than just amusing, they inadvertently revealed that oops! AI models are only as smart as we are. Like us, they also struggle to draw hands.

AI models have quickly become more sophisticated, but now there are so many of them. And – again – like us, some models are better at certain tasks than others. Take text generation, for example. Even though Llama, Gemma, and Mistral are all LLMs, some of them are better at generating code while others are better at brainstorming, coding, or creative writing. They offer different advantages depending on the prompt, so it may make sense to include more than one model in your AI application.
But how do you integrate all these models into your app without duplicating code? How do you make your use of AI more modular and therefore easier to maintain and scale? That’s where an API can offer a standardized set of instructions for communicating across different technologies.
In this blog post, we’ll take a look at how to use Replicate with Streamlit to create an app that allows you to configure and prompt different LLMs with a single API call. And don’t worry – when I say “app,” I don’t mean having to spin up a whole Flask server or tediously configure your routes or worry about CSS. Streamlit’s got that covered for you 😉
Read on to learn:
- What Replicate is
- What Streamlit is
- How to build a demo Replicate chatbot Streamlit app
- And best practices for using Replicate
Don’t feel like reading? Here are some other ways to explore this demo:
- Find the code in the Streamlit Cookbook repo here
- Watch a video walkthrough with Streamlit senior developer advocate, Chanin Nantasenamat, and Replicate founding designer, Zeke Sikelianos, here
- Check out a deployed version of the app here or see the embedded app below (click to view it in full frame):
What is Replicate?
Replicate is a platform that enables developers to deploy, fine tune, and access open source AI models via a CLI, API, or SDK. The platform makes it easy to programmatically integrate AI capabilities into software applications.
Available models on Replicate
- Text: Models like Llama 3 can generate coherent and contextually relevant text based on input prompts.
- Image: Models like stable diffusion can generate high-quality images from text prompts.
- Speech: Models like whisper can convert speech to text while models like xtts-v2 can generate natural-sounding speech.
- Video: Models like animate-diff or variants of stable diffusion like videocrafter can generate and/or edit videos from text and image prompts, respectively.
When used together, Replicate allows you to develop multimodal apps that can accept input and generate output in various formats whether it be text, image, speech, or video.
What is Streamlit?
Streamlit is an open-source Python framework to build highly interactive apps – in only a few lines of code. Streamlit integrates with all the latest tools in generative AI, such as any LLM, vector database, or various AI frameworks like LangChain, LlamaIndex, or Weights & Biases. Streamlit’s chat elements make it especially easy to interact with AI so you can build chatbots that “talk to your data.”
Combined with a platform like Replicate, Streamlit allows you to create generative AI applications without any of the app design overhead.
To learn more about Streamlit, check out the 101 guide.
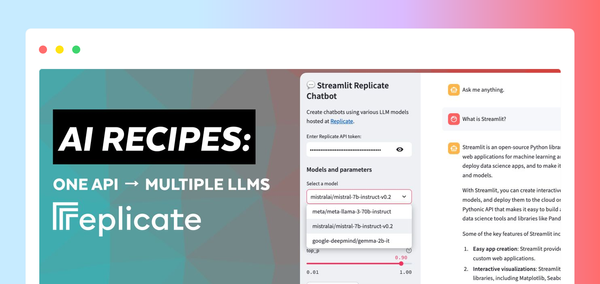
Try the app recipe: Replicate + Streamlit
But don’t take my word for it. Try out the app yourself or watch a video walk through and see what you think.
In this demo, you’ll spin up a Streamlit chatbot app with Replicate. The app uses a single API to access three different LLMs and adjust parameters such as temperature and top-p. These parameters influence the randomness and diversity of the AI-generated text, as well as the method by which tokens are selected.
Temperature controls how the model selects tokens. A lower temperature makes the model more conservative, favoring common and “safe” words. Conversely, a higher temperature encourages the model to take more risks by selecting less probable tokens, resulting in more creative outputs.
What is top-p?
Also known as “nucleus sampling” — is another method for adjusting randomness. It works by considering a broader set of tokens as the top-p value increases. A higher top-p value leads to a more diverse range of tokens being sampled, producing more varied outputs.
Prerequisites
- Python version >=3.8, !=3.9.7
- A Replicate API key
(Please note that a payment method is required to access features beyond the free trial limits.)
Environment setup
Local setup
- Clone the Cookbook repo:
git clonehttps://github.com/streamlit/cookbook.git - From the Cookbook root directory, change directory into the Replicate recipe:
cd recipes/replicate - Add your Replicate API key to the
.streamlit/secrets_template.tomlfile - Update the filename from
secrets_template.tomltosecrets.toml:mv .streamlit/secrets_template.toml .streamlit/secrets.toml
(To learn more about secrets handling in Streamlit, refer to the documentation here.) - Create a virtual environment:
python -m venv replicatevenv - Activate the virtual environment:
source replicatevenv/bin/activate - Install the dependencies:
pip install -r requirements.txt
GitHub Codespaces setup
- From the Cookbook repo on GitHub, create a new codespace by selecting the
Codespacesoption from theCodebutton - Once the codespace has been generated, add your Replicate API key to the
recipes/replicate/.streamlit/secrets_template.tomlfile - Update the filename from `secrets_template.toml` to
secrets.toml
(To learn more about secrets handling in Streamlit, refer to the documentation here.) - From the Cookbook root directory, change directory into the Replicate recipe:
cd recipes/replicate - Install the dependencies:
pip install -r requirements.txt

Run a text generation model with Replicate
- Create a file in the
recipes/replicatedirectory calledreplicate_hello_world.py - Add the following code to the file:
import replicate import toml import os # Read the secrets from the secrets.toml file with open(".streamlit/secrets.toml", "r") as f: secrets = toml.load(f) # Create an environment variable for the Replicate API token os.environ['REPLICATE_API_TOKEN'] = secrets["REPLICATE_API_TOKEN"] # Run a model for event in replicate.stream("meta/meta-llama-3-8b", input={"prompt": "What is Streamlit?"},): print(str(event), end="") - Run the script:
python replicate_hello_world.py
You should see a print out of the text generated by the model.
To learn more about Replicate models and how they work, you can refer to their documentation here. At its core, a Replicate “model” refers to a trained, packaged, and published software program that accepts inputs and returns outputs.
In this particular case, the model is meta/meta-llama-3-8b and the input is "prompt": "What is Streamlit?". When you run the script, a call is made to the Replicate endpoint and the printed text is the output returned from the model via Replicate.
Run the demo Replicate Streamlit chatbot app
To run the demo app, use the Streamlit CLI from the recipes/replicate directory: streamlit run streamlit_app.py.
Running this command deploys the app to a port on localhost. When you access this location, you should see a Streamlit app running.

You can use this app to prompt different LLMs via Replicate and produce generative text according to the configurations you provide.
A common API for multiple LLM models
Using Replicate means you can prompt multiple open source LLMs with one API which helps simplify AI integration into modern software flows.
This is accomplished in the following block of code:
for event in replicate.stream(
model,
input={
"prompt": prompt_str,
"prompt_template": r"{prompt}",
"temperature": temperature,
"top_p": top_p,
},
):
yield str(event)The model, temperature, and top p configurations are provided by the user via Streamlit’s input widgets. Streamlit’s chat elements make it easy to integrate chatbot features in your app. The best part is you don’t need to know JavaScript or CSS to implement and style these components – Streamlit provides all of that right out of the box.
Replicate best practices
Use the best model for the prompt
Replicate provides an API endpoint to search for public models. You can also explore featured models and use cases on their website. This makes it easy to find the right model for your specific needs.
Different models have different performance characteristics. Use the appropriate model based on your needs for accuracy and speed.
Improve performance with webhooks, streaming, and image URLs
Replicate's output data is only available for an hour. Use webhooks to save the data to your own storage. You can also set up webhooks to handle asynchronous responses from models. This is crucial for building scalable applications.
Leverage streaming when possible. Some models support streaming, allowing you to get partial results as they are being generated. This is ideal for real-time applications.
Using image URLs provides improved performance over the use of uploaded images encoded by base 64.
Unlock the potential of AI with Streamlit
With Streamlit, months and months of app design work are streamlined to just a few lines of Python. It’s the perfect framework for showing off your latest AI inventions.
Get up and running fast with other AI recipes in the Streamlit Cookbook. (And don’t forget to show us what you’re building in the forum!)
Happy Streamlit-ing! 🎈
Comments
Continue the conversation in our forums →