
Streamlit makes it incredibly easy to turn your Python scripts into interactive web apps give you the opportunity to showcase your powerful GenAI apps. As your app moves from a cool proof-of-concept to production-ready, a few best practices can make a world of difference in terms of cost, performance, maintainability, and user trust.
This post will walk you through key strategies to build more robust, scalable, and responsible GenAI apps with Streamlit.
Let's dive in!
1. Structure your app for sanity and scalability
As your GenAI app grows, a good structure is your best friend. This especially holds for when you build and maintain several apps as having a consistent structure or framework helps you to quickly glide through app maintenance. A more modular approach is crucial for more complex apps.
Keep your main Streamlit app script (streamlit_app.py) clean and focused on the UI and workflow.
For everything else, such as LLM interaction logic, retrieval augmented generation (RAG) and agentic behavior, and prompt management consider using a utils/ directory.
- Create files like
utils/llm.pyto handle API calls, client setups, and error handling - Use
utils/prompt.pyfor storing and formatting your prompt templates.
A recommended project structure might look like this:
my_genai_app/
├── .streamlit/
│ └── config.toml # App configuration and styling
├── assets/ # Reusable UI assets (images, custom CSS, etc.)
├── utils/
│ └── llm.py # LLM utility functions
│ └── prompt.py # Prompt utility functions
├── README.md # Describes the repo and its usage
├── requirements.txt # Python dependencies
├── streamlit_app.py # Main Streamlit app logicAlternatively, instead of using a utils/ folder to house several utility script files, you could also create semantic folders that are named accordingly to reflect what the scripts are doing. For example, having a data/ folder for data ingestion scripts, an llm/ folder for LLM calls, etc.
2. Customize chat elements
Streamlit's chat elements, st.chat_message() and st.chat_input(), are fundamental for building conversational GenAI applications. Customizing these elements, particularly avatars, can significantly improve the user experience and branding of your chatbot.
The st.chat_message() function inserts a container for a single chat message into the app.
Setting the name parameter to "user", "assistant", "human", or "ai" unlocks preset styling and default avatars. Furthermore, any other strings can also be used for specifying custom roles.
# Name using AI
with st.chat_message("AI"):
st.write("How can I help you?")
# Name using user
with st.chat_message("user"):
st.write("What is Python?")
# Name using assistant
with st.chat_message("assistant"):
st.write("How can I help you?")
# Name using human
with st.chat_message("human"):
st.write("What is Streamlit?")

The avatar parameter allows the developer to specify a custom avatar image that is displayed in the chat message container. As shown in the example below, one can use emojis, materials icons, or even an image by specifying the "path/to/image.png".
# Avatar using emoji
with st.chat_message("assistant", avatar="🦖"):
st.write("How can I help you?")
# Avatar using materials icon
with st.chat_message("user", avatar=":material/thumb_up:"):
st.write("What is Python?")
# Avatar using an image
with st.chat_message("user", avatar="path/to/image.png"):
st.write("What is Streamlit?")
3. Display LLM outputs effectively
LLMs can output plain text, Markdown, JSON, and more. Streamlit has you covered:
st.json(): Great for displaying structured JSON output from an LLM in an interactive, collapsible format.st.markdown(): If your LLM outputs Markdown (many do for rich text like headings, lists, or code blocks),st.markdown()will render it beautifully.st.write_stream(): This is perfect for writing out text token-by-token from streaming responses.
# Generate response using your favorite LLM model
def response_generator():
# Code for response generation goes here
return response
# Display assistant response in chat message container
with st.chat_message("assistant"):
response = st.write_stream(response_generator())
4. Master prompt engineering in Streamlit
The quality of your prompts heavily influences your LLM's output. Streamlit's interactivity is perfect for this.
- Dynamic & context-aware prompts: Build prompts that incorporate user input from widgets (like
st.text_input()), chat history fromst.session_state, or data from uploaded files. This essentially allows you to dynamically generate prompts for RAG workflows. - Use prompt templates: Don't hardcode complex prompts. Use f-strings, or better yet, functions in your
utils/prompt.pyto create reusable prompt templates that you can fill with dynamic data. - Give yourself debugging tools: Use sidebar widgets (
st.selectbox()for model choice,st.slider()for temperature) to allow tweaking LLM parameters or even parts of the prompt. Streamlit's quick refresh cycle makes it easy to experiment and iterate on your prompts.
In the example below, you’ll see that you can insert widget values into the prompt variable in order to dynamically generate the prompt.
prompt = f"""
You are a helpful AI chat assistant.
Please use <context> tag to answer <question> tag.
<context>
{prompt_context}
</context>
<question>
{user_question}
</question>
Answer:
"""5. Handle API keys securely
It is advised not to hardcode API keys or other secrets directly in your scripts. Instead, use Streamlit’s built-in secrets handling with st.secrets.
Locally, create a TOML file at $CWD/.streamlit/secrets.toml (Note: be sure to add this file to your .gitignore! Otherwise the credentials may slip into the public repo).
Alternatively, when you deploy to Streamlit Community Cloud, you'll enter these secrets through the in-app Secrets management in TOML format. Subsequently you can access them in your code via st.secrets.
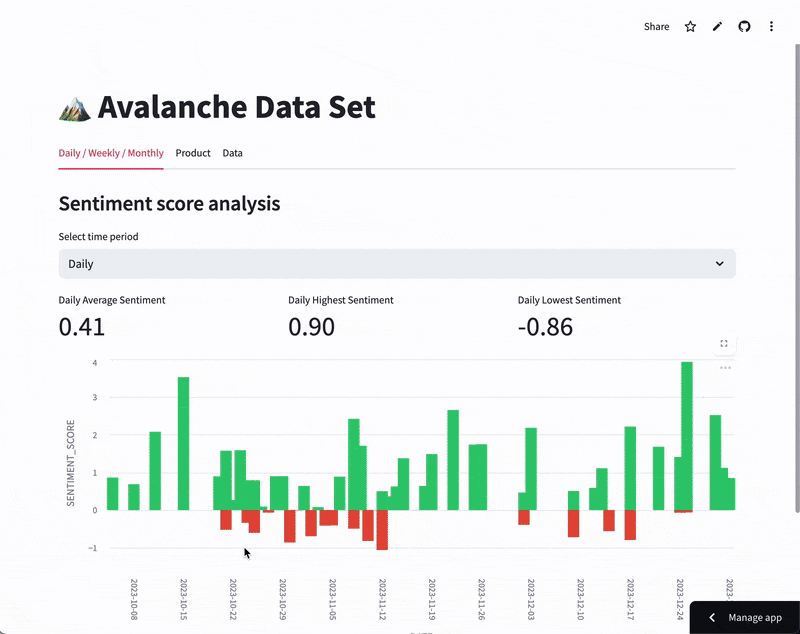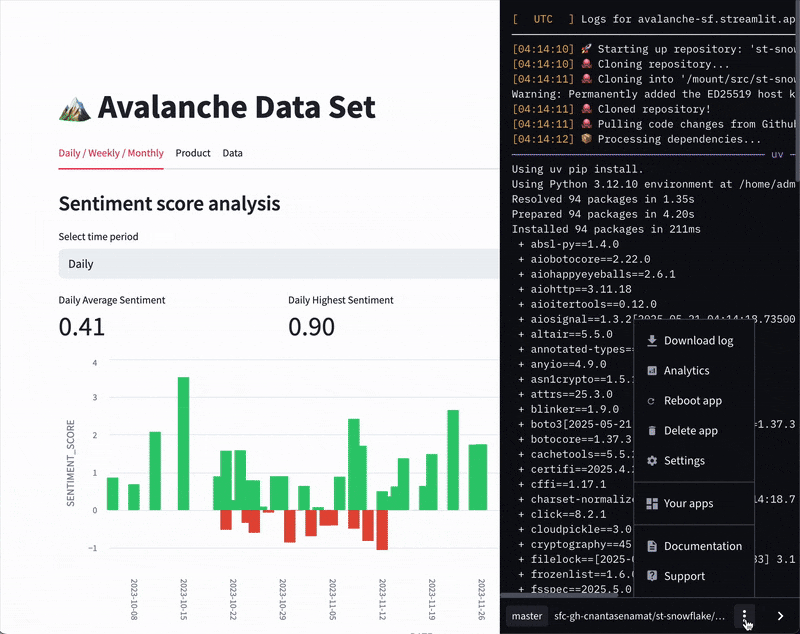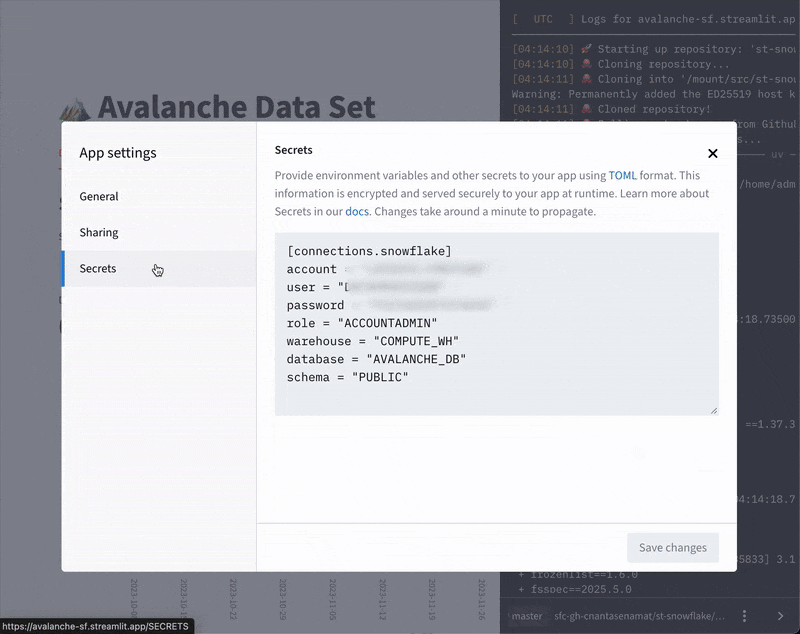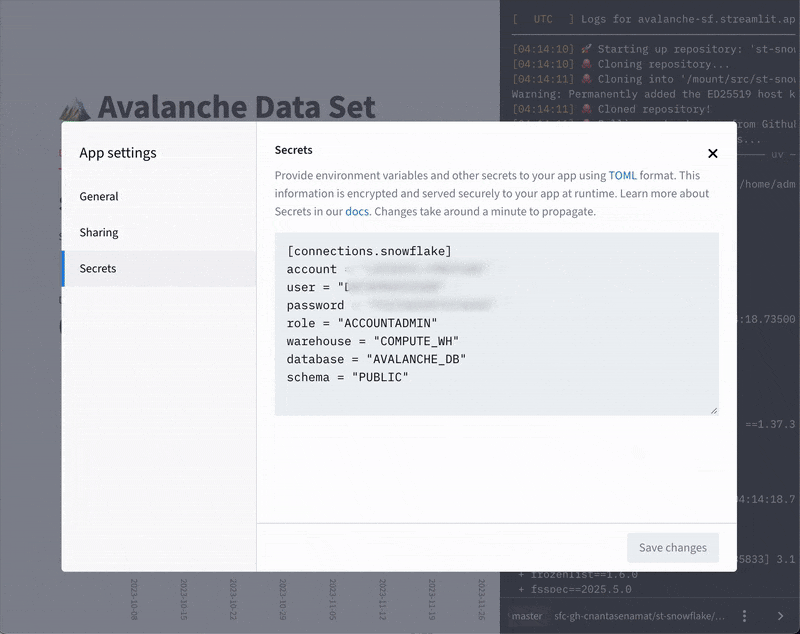
These stored secrets are available in-app as environment variables and can be accessed via st.secrets["key_name"].
6. Use st.session_state to maintain context
For LLM apps, especially conversational ones, maintaining context is crucial. st.session_state provides this "memory" by storing conversation history.
LLMs are typically stateless, processing each input independently. To create coherent conversations, st.session_state stores the message history between the user and LLM.
Here's the basic process:
- Initialization: Store an empty list (e.g.,
st.session_state.messages = []). - Message Storage: Append each user input and LLM output to the history in
st.session_state. - Contextual Input: Retrieve relevant history from
st.session_stateand include it in prompts to the LLM. - Displaying History: Use the stored history in
st.session_stateto show the conversation.
Streamlit's callback functions update the st.session_state in response to user interactions with widgets. For instance, widgets like st.button(), st.text_input(), and st.selectbox() trigger callbacks (using the on_click or on_change parameter) that it uses to modify st.session_state. This, in turn, updates the conversation history or other app states dynamically.
To clear the conversation history, you can delete the key in st.session_state where the history is stored or assign an empty list to that key. This can also be done within a callback function as triggered by a button. An example of this is shown below:
def clear_chat_history():
st.session_state.messages = [] # Clear the message history
st.button("Clear History", on_click=clear_chat_history)Using st.session_state and callbacks in LLM apps enables the following:
- Coherent conversations: LLM responses become more relevant.
- Contextual awareness: The LLM understands conversation history.
- Complex interactions: Follow-up questions and clarifications are possible.
- Personalization: LLM responses can be tailored to user history.
- Dynamic updates: Apps respond to user input in real-time.
- Interactive control: Users can influence the LLM's behavior (e.g., provide context, specify LLM model parameter, etc.)
- State management: Store user preferences and app settings.
In short, st.session_state provides LLM apps "memory," and callbacks allow users to interact with and modify that memory, leading to more sophisticated and interactive apps. Without these capabilities, interaction with the LLM app would be a mere one-off, input-output submission.
7. Implement rate-limiting to keep API costs under control
Generative AI models, especially those accessed via APIs, can get expensive quickly if usage is not monitored.
Let’s say an app that you released over the weekend became very popular and has gone viral. As a result, the app may rack up a significant sum of money due to high API consumption. Implementing rate limits is a solution to keep this in check.
Rate-limiting can be tackled via 2 approaches: (1) client-side and/or (2) server-side.
Client-side rate-limiting
Okay, let's supercharge your GenAI app's performance and keep your users happy! Directly managing how often your app calls external APIs is a savvy move for both your budget and user experience; we can think of client-side request limits as your first line of defense.
Think of it like this: you can give each user a "request allowance" for those external services. One neat trick is to use st.session_state to monitor external API pings within a timeframe – say, five requests per minute. If they go over, a friendly st.warning() can let them know to pause. For smoother control, try a token bucket system with st.session_state where users get "API call tokens" that will enable them access to external APIs that would replenish over time.
Server-side rate-limiting
Here's another powerful tip for keeping API costs firmly in check, on top of your client-side strategies: specify hard dollar limits for your API usage. You can set maximums like $5 daily, $20 weekly, or $50 monthly. Why is this so great? It shields your API token from unexpected charges if your app suddenly takes off, accumulating high usage and costs. It's a straightforward way to prevent unexpected bills from skyrocketing!
8. Use caching to improve performance and save cost
Streamlit's caching is a powerhouse for optimization! For external API calls, you can dramatically reduce how often you hit those external services for the same information.
@st.cache_data is your go-to! Slap it on functions that fetch data from external APIs. This caches the responses, so if the same request is made, your app serves the cached data lightning fast, slashing your actual external API call volume and associated costs. Remember to set a ttl (time-to-live) if that external data might change frequently.
If your application performs computationally intensive local tasks (e.g., like loading large LLM models from Hugging Face directly into its operating environment), this process represents a significant computational load that demands substantial local resources. For these kinds of resource-intensive local initializations, @st.cache_resource may be a lifesaver. It ensures that hefty objects like your LLM are loaded into memory only once – when the app starts or when their configuration changes, not on every single user interaction or script rerun. This dramatically speeds up your app's responsiveness when using these local models.
Both Streamlit caching decorators, @st.cache_data and @st.cache_resource, are vital for optimizing application performance. @st.cache_data is crucial for efficiently managing functions that return data—such as dataframe transformations, database query results, or ML inference outputs — and is particularly effective in conserving external API quotas and reducing costs by caching fetched data. @st.cache_resource excels at optimizing the initialization and reuse of computationally expensive global resources, like database connections or large machine learning models, ensuring they are loaded only once and shared across sessions.
9. Keep your app snappy with asynchronous operations
Nobody likes a frozen UI! Long-running LLM API calls may cause the app to become unresponsive. To ensure a responsive app, let's explore how to provide users with timely updates during long waits and how to leverage asyncio for asynchronous execution.
Let users know you're working on It
While your app is performing lengthy calculations or tasks with long waits, it always helps to provide feedback during the wait (see the Docs on Display progress and status):
st.spinner("Thinking..."): Use this as a context manager to show a message and a spinner while a block of code executes.st.progress(0): If you can quantify progress, use a progress bar and update it (e.g.,my_bar.progress(percent_complete)).st.status("Working on it..."): This container can display messages that you update as a multi-step task progresses.
Here's an example:
import time
import streamlit as st
with st.status("Downloading data...", expanded=True) as status:
st.write("Searching for data...")
time.sleep(2)
st.write("Found URL.")
time.sleep(1)
st.write("Downloading data...")
time.sleep(1)
status.update(
label="Download complete!", state="complete", expanded=False
)
st.button("Rerun")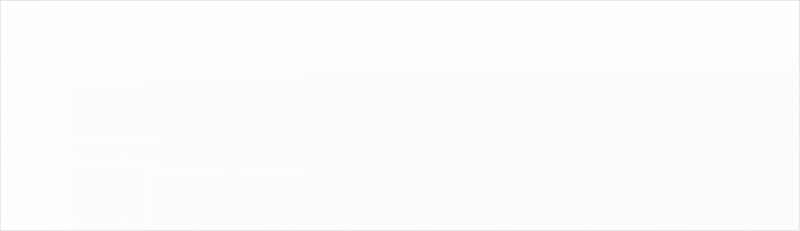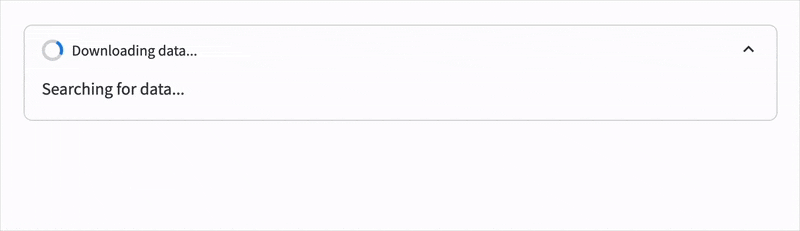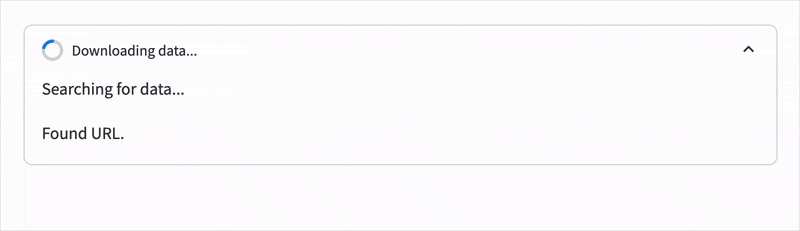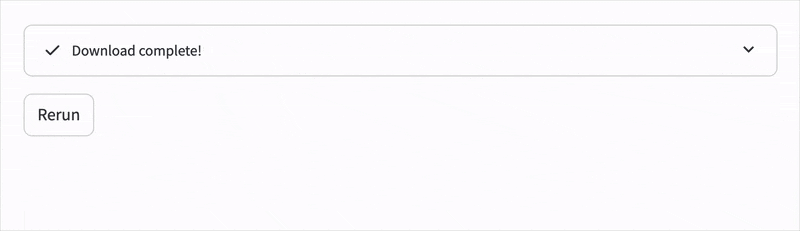
st.toast("Done!"): For quick, non-blocking notifications, like when a background task finishes.
Let’s now take a look at implementing asynchronous operations.
Use asyncio for non-blocking LLM calls
Python's asyncio library, with its async/await syntax, lets your app handle long I/O operations (like API calls) without freezing up the main thread. This is key for a smooth user experience.
- Basic async calls: Define your API call functions with async def. Inside, use await when calling your LLM provider's async client (e.g., AsyncOpenAI), which you can see in action in this AsyncOpenAI code snippet. From your main Streamlit script (which runs synchronously), you'll use
asyncio.run()to execute your async function. - Stream responses for a better feel: For tasks like chat, streaming the LLM's response (showing words as they're generated) makes your app feel much faster instead of waiting for the entire response to generate. As many LLM libraries provide an asynchronous generator for streaming, you can use
st.write_stream()to deliver the stream of text to the app as it is being generated.
10. See what your GenAI model is doing with observability
GenAI models can sometimes feel like "black boxes." Observability tools help you understand their behavior, debug issues, and ensure quality. This is not just about fixing bugs; it's about understanding why your model said what it said, which is crucial for iteration and building trust.
TruLens
TruLens is an open-source tool that's great for evaluating and tracking your LLM apps.
- Get started: Install Trulens (
pip install trulens), initialize a TruSession, and then wrap your LLM apps (like a LangChain agent or LlamaIndex RAG engine) with a Trulens recorder (e.g., TruLlama or TruChain). This lets TruLens log inputs, outputs, and all those important intermediate steps. The Streamlit cookbook also has a demo showing TruLens in action in this TruLens recipe. - Embed Insights in Streamlit: Trulens offers Streamlit components you can pop right into your app for real-time feedback :
- Use
trulens_leaderboard()to show a summary of feedback results and costs across different app versions. - With
trulens_feedback(record=your_record_object), you can display clickable feedback scores (like relevance or sentiment) for specific interactions. - And
trulens_trace(record=your_record_object)gives you a detailed execution trace for debugging.
- Use
- Dive Deeper with the Dashboard: For a more comprehensive view,
run_dashboard()launches a full TruLens dashboard, which is a Streamlit app itself!
LangSmith
LangSmith, from the creators of LangChain, is another excellent platform for LLM observability.
- Get started: Install Langsmith (
pip install langsmith) - Trace URL: A super useful trick is to display direct links to LangSmith traces in your Streamlit UI. When an LLM interaction happens, use LangChain's
tracing_v2_enabledcontext manager to capture the run. Then, get the trace URL usingcb.get_run_url()(wherecbis the callback handler) and show it in-app. This makes debugging so much faster! See this example. - The LangSmith cookbook has more examples, including how to add user feedback buttons to your Streamlit app that log back to LangSmith.
Other open-source observability tools
Beyond TruLens and LangSmith, consider other open-source tools like Helicone for LLM observability and Logfire that also offer features like Pydantic integration and auto-instrumentation via OpenTelemetry.
Observability isn't just for debugging code; it's a cornerstone of responsible AI development. You can programmatically evaluate your app for fairness and bias by checking if it treats different groups equitably. You can gain transparency by examining individual traces and evaluation results, offering insights into the model's operations. Observability tools can also help with security and privacy by detecting PII leakage or harmful language in outputs. Furthermore, including a broad set of evaluators allows for holistic evaluation, covering aspects like groundedness (is the answer based on provided context?), relevance, and safety, thereby helping you build more trustworthy apps.
Conclusion
Building effective GenAI apps with Streamlit requires a thoughtful approach that goes beyond simply connecting to LLM models.
In this article, we've explored 10 best practices for building robust, scalable, and responsible GenAI apps with Streamlit:
Robust 💪
- Use
st.session_statefor context: Employst.session_stateand callbacks to manage conversation history and state, enabling coherent, interactive LLM apps. - Master prompt engineering: Create dynamic, context-aware prompts using Streamlit's interactive widgets and utilize prompt templates.
- Display LLM outputs effectively: Use
st.json(),st.markdown(), andst.write_stream()to present various output formats clearly. - Customize chat elements: Enhance user experience and branding by tailoring
st.chat_message()with custom avatars.
Scalable 📈
- Structure your app logically: Organize code into utility modules for better maintainability and scalability.
- Utilize caching: Improve performance and reduce costs by caching external API responses with
@st.cache_dataand heavy local resources with@st.cache_resource. - Keep your app snappy: Prevent UI freezes during long-running tasks using asyncio and progress updates with elements like
st.spinner(),st.progress(),st.status(), andst.toast().
Responsible 🛡️
- Employ observability tools: Gain insights into GenAI application model behavior, debug issues, and ensure quality using tools like Trulens and LangSmith.
- Handle API keys securely: Utilize
st.secretsto manage sensitive credentials and avoid hardcoding them in your scripts. - Implement rate-limiting: Control API costs and prevent abuse through client-side and server-side strategies.
By embracing these best practices, you can move beyond impressive proof-of-concepts to production-ready LLM apps.
Happy Streamlit-ing! 👑




Comments
Continue the conversation in our forums →