
PythonAstREPLTool which is vulnerable to arbitrary code execution. Use caution in deploying and sharing this app.Communicating with pandas DataFrames makes data analysis accessible to non-technical users. Using a chat-like interface, users can ask data-related questions, request insights, and navigate through data as if they were chatting with a friend.
Since the preferred method for engaging with chatbots is through a question-and-answer format, let’s make an app that seamlessly integrates with user queries.
But first, we’ll take a look at how it works.
App overview
Users can interact with pandas DataFrames by uploading CSV, Excel, or any other supported structured data files:
Tutorial
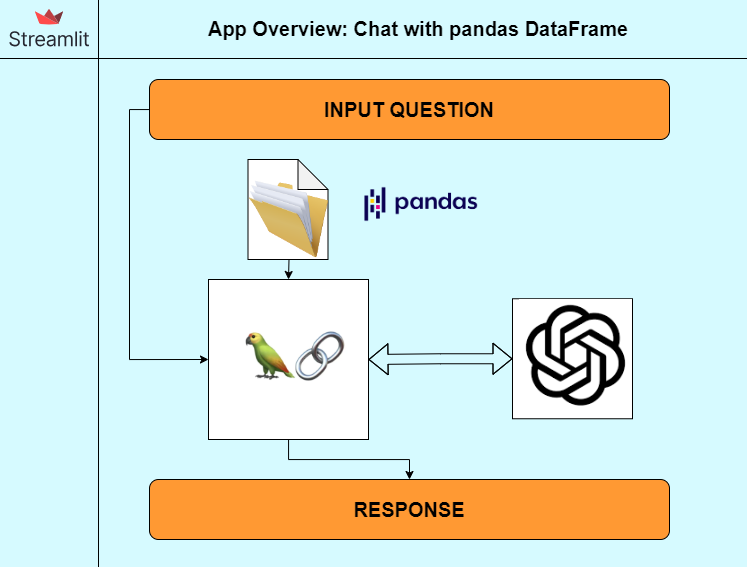
To start, make sure that you have the necessary key technologies installed, as well as a basic understanding of the application framework shown in the diagram below:
- Python, Streamlit, and Docker: Python and Docker are essential components for building and deploying the app. Having knowledge of building UI with Streamlit is a plus.
- Virtual Environment using Poetry: To create a virtual environment, install
[Poetry](<https://python-poetry.org/>). It simplifies dependency management and environment setup. - Project Dependencies: All the required dependencies for the project are specified in the
pyproject.tomlfile. They ensure that your app has access to the necessary libraries and tools to function properly. - OpenAI API Token: Get an OpenAI API token here.
1. Load data into pandas DataFrame
The first step is to load and persist user data into a pandas DataFrame. For smaller datasets, it is good practice to persist the data. Users can upload files with various extensions from the list above. The data is cached for 2 hours using @st.cache_data(ttl="2h") and destroyed after that time has elapsed to release resources.
file_formats = {
"csv": pd.read_csv,
"xls": pd.read_excel,
"xlsx": pd.read_excel,
"xlsm": pd.read_excel,
"xlsb": pd.read_excel,
}
@st.cache_data(ttl="2h")
def load_data(uploaded_file):
try:
ext = os.path.splitext(uploaded_file.name)[1][1:].lower()
except:
ext = uploaded_file.split(".")[-1]
if ext in file_formats:
return file_formats[ext](uploaded_file)
else:
st.error(f"Unsupported file format: {ext}")
return None
# Read the Pandas DataFrame
df = load_data(uploaded_file)
2. LangChain and OpenAI as an LLM engine
I have integrated LangChain's create_pandas_dataframe_agent to set up a pandas agent that interacts with df and the OpenAI API through the LLM model. This agent takes df, the ChatOpenAI model, and the user's question as arguments to generate a response. Under the hood, a Python code is generated based on the prompt and executed to summarize the data. The LLM model then converts the data into a conversational format for the final response.
For this example, I used the "gpt-3.5-turbo-0613" model, but users can choose GPT4 or any other model. Performance may vary depending on the model and dataset used.
In this code, the input questions are captured using the st.session_state.messages object from the Streamlit UI, and the response is passed back to the UI for display:
from langchain.agents import AgentType
from langchain.agents import create_pandas_dataframe_agent
from langchain.callbacks import StreamlitCallbackHandler
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(
temperature=0, model="gpt-3.5-turbo-0613", openai_api_key=openai_api_key, streaming=True
)
pandas_df_agent = create_pandas_dataframe_agent(
llm,
df,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
handle_parsing_errors=True,
)
response = pandas_df_agent.run(st.session_state.messages, callbacks=[st_cb])
3. Use Streamlit for UI
I chose Streamlit UI for its simplicity and recently released chat features, such as st.chat_message("assistant"). It’s a lightweight and efficient method for building and sharing data apps.
import streamlit as st
import pandas as pd
import os
st.set_page_config(page_title="LangChain: Chat with Pandas DataFrame", page_icon="🦜")
st.title("🦜 LangChain: Chat with Pandas DataFrame")
uploaded_file = st.file_uploader(
"Upload a Data file",
type=list(file_formats.keys()),
help="Various File formats are Support",
on_change=clear_submit,
)
if uploaded_file:
df = load_data(uploaded_file)
The above code initializes the app and adds the Upload File Widget to the UI. You can upload data files using Streamlit's st.file_uploader component.
openai_api_key = st.sidebar.text_input("OpenAI API Key", type="password")
if "messages" not in st.session_state or st.sidebar.button("Clear conversation history"):
st.session_state["messages"] = [{"role": "assistant", "content": "How can I help you?"}]
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
if prompt := st.chat_input(placeholder="What is this data about?"):
st.session_state.messages.append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)
if not openai_api_key:
st.info("Please add your OpenAI API key to continue.")
st.stop()
llm = ChatOpenAI(
temperature=0, model="gpt-3.5-turbo-0613", openai_api_key=openai_api_key, streaming=True
)
pandas_df_agent = create_pandas_dataframe_agent(
llm,
df,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
handle_parsing_errors=True,
)
The user is prompted to provide their OpenAI API keys through a sidebar text widget. Use st.session_state to keep track of variables and chat history. The user's input query is obtained using st.chat_input(), which is then passed to pandas_df_agent as discussed in the previous section.
with st.chat_message("assistant"):
st_cb = StreamlitCallbackHandler(st.container(), expand_new_thoughts=False)
response = pandas_df_agent.run(st.session_state.messages, callbacks=[st_cb])
st.session_state.messages.append({"role": "assistant", "content": response})
st.write(response)
The code above interacts with the pandas_agent and captures its response—displayed and appended to the chat history.
4. Use Docker for deployment
After preparing and testing the app, deploy it on the Streamlit Community Cloud using the GitHub repository or on Google Cloud, Heroku, AWS, or Azure using a Docker configuration.
4.1. Clone the GitHub repository
git clone https://github.com/langchain-ai/streamlit-agent.git
4.2. Install requirements by creating a venv
>> poetry install
>> poetry shell
4.3. Run the app locally
$ streamlit run streamlit_agent/chat_pandas_df.py
4.4. Run the app using Docker
The project includes the Dockerfile and docker-compose.yml. To build and run a Docker image:
- Generate the image with
DOCKER_BUILDKIT
DOCKER_BUILDKIT=1 docker build --target=runtime . -t langchain-streamlit-agent:latest
- Run the Docker container directly
docker run -d --name langchain-streamlit-agent -p 8051:8051 langchain-streamlit-agent:latest
- Run the Docker container using docker-compose
Edit the Command in docker-compose with the target Streamlit app docker-compose up. To deploy Streamlit apps using Google Cloud, follow this guide.
Potential errors
If you choose to make a copy of and operate the application on your own computer or any online cloud system, you might come across the following problems:
- Preparing your personal environment and necessary components, since they are currently configured to utilize the most recent editions of LangChain & Streamlit.
- Due to our utilization of a mix of OpenAI & Langchain tools, there are instances where the model produces outcomes that aren't what we intended. In some cases, rephrasing your questions can help resolve this problem.
- When using Docker, it's important to have the latest version of Docker Desktop installed and sufficient storage space available for creating and running the image.
Wrapping up
You learned how to construct a generative AI application to talk with pandas DataFrames or CSV files by using LangChain's tools, and how to deploy and run your app locally or with Docker support.
Here are the key takeaways:
- You can seamlessly interact with business-specific data stored in Excel or CSV files, eliminating the need for complex setups or configurations.
- You can transform DataFrames into conversational entities, similar to human conversations.
- You can empower business users to pose relevant questions and engage with data, without requiring any prior knowledge of data processing or analysis.
Now you can bridge the gap between data-driven insights and effortless interaction, enhancing the accessibility and usability of your data for a wider range of users. Let me know if you have any questions in the comments below or contact me on GitHub, LinkedIn, Twitter, or email.
Happy Streamlit-ing! 🎈




Comments
Continue the conversation in our forums →