
My app is too slow
A few weeks ago, I used an internal Streamlit app to check the performance of a specific feature. But it took so long to load, that I often gave up before I actually got to use the app. So I checked the code. At first glance it looked all good. We were caching the results using st.cache_data. And the code itself wasn’t very complex. It was pulling data from a few tables in Snowflake, applying filters (some using Snowpark and some using Pandas) and displaying graphs and tables.
So why did it take so long to load the first time I visited it?
Profiling the app
Since the app used many queries, I first wanted to find which ones were slow.
We have a set of standard functions for querying and caching data from Snowflake, that look roughly like this:

I modified them so that, in addition to running the queries and caching the results, they’d also tell me how long each query took to run.
The final result looked like this:

Adding time() calls before and after the query and using st.write() to display the time difference helped me find the slow parts of the app. I could’ve used python -m cProfile streamlit_app.py to dig deeper, but it wasn't necessary in this case. Now I could start investigating.
Handling the slow query
I identified the slow parts of the query with Snowflake's Query Profiler. As you can see below, a specific Aggregate step took up a lot of time time. By clicking on it, I can learn more about what’s happening.

In this case, the slow query was performing two tasks that required significant processing:
- Retrieving data from a large table
- Performing complex transformations on the data
These transformations involved filtering the data based on multiple columns to obtain the latest rows and calculating statistics related to a Variant column. While the actual process was more intricate, this is a general overview of what was happening.
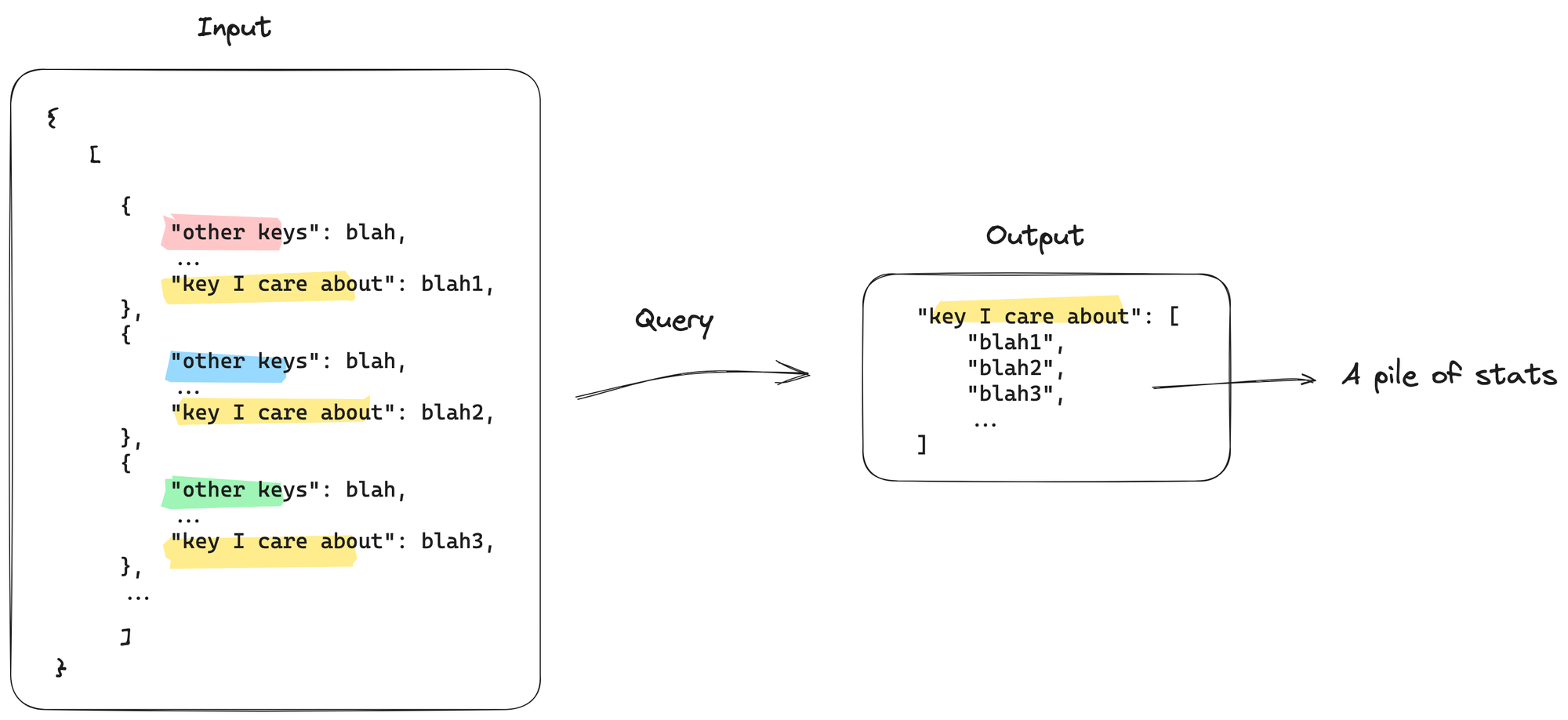
To speed up the query, I created a new model in dbt that:
- Filtered the source table to include only the latest values each day.
- Added a new column that pre-computed the list of values for the specific "key" of interest.
The process of flattening the data looked roughly like this:
with flattened_keys as (
select
id,
flattened.value:"KEY"::string as value
from
BASE_TABLE as BT,
lateral flatten(input => parse_json(p.COLUMN)) as flattened
where
flattened.value:"KEY" is not null
),
flattened_array as (
select
id,
array_agg(value) as value_array
from
flattened_keys
group by
id
),
new_table as (
select
f.value_array,
BT.*
from BASE_TABLE as BT
left join flattened_arrays as f
using (id)
)
select * from new_table
Once I had the model and it was populated with data, I switched my app to pull from the new table, and I simplified the query that was performing computations by using this well-prepared table.
The app's query before:
with transformed as (
select
id,
count(flattened.value:KEY) AS num_values,
count(distinct flattened.value:KEY) AS num_unique_values
from BASE_TABLE,
lateral flatten(BASE_TABLE.COLUMN) as flattened
group by id
{extra_filters}
)
select
transformed.num_values,
transformed.num_unique_values
BASE_TABLE.*,
from BASE_TABLE
inner join transformed
using(id)
The query after:
select
*,
array_size(value_array) as num_values,
array_size(array_distinct(value_array)) as num_unique_values,
from new_table
{extra_filters}
The result? The new query was 100 times faster than the old one! This improved the app’s usability and expanded the range of analyses that we could easily perform in a reasonable amount of time.
What’s the general pattern?
If your Streamlit app is slow, try moving the slowest parts outside of the app—like into a pre-processed table with dbt.
Will this fix my slow app?
Perhaps! It depends on the specific problem. Here are a few scenarios and the approaches you might take to resolve them:
- My app is query-driven and the first run is very slow. Try pre-computing the table you will need outside of your app like I did above.
- My app is slow every time I run it. Are you using
st.cache_dataorst.cache_resourceto prevent rerunning slow processes? For more information, read the Streamlit documentation on caching. - My app pulls data from a CSV, not from a database. Consider performing a similar process to what I did with my data. Get the raw data, execute queries to process it, and save the pre-processed file for use in your app. For faster loading, use a Parquet file format instead of CSV.
- My app is slow for a different reason. Try figuring out which part is the slowest, and if you can find a way to do the slowest part of the work outside of your app itself. For example, if your app trains a machine learning model, try moving the model training outside of the app itself, save the model once it’s trained, and then use the pre-trained model to make predictions within your app.
Wrapping up
If your Streamlit app is too slow, consider adding profiling to identify the slow parts, especially data queries. We sped up our apps by offloading resource-intensive tasks to dbt and optimizing the problematic query. By moving heavy workloads outside the app, you can create a faster and more user-friendly experience.
If you have any questions, please post them in the comments below or contact me on Twitter.
Happy app-fixing! 🛠️



Comments
Continue the conversation in our forums →