
Designing and scaling a Streamlit app can be a daunting task! As developers, we often face challenges like designing good UIs, debugging our apps quickly, and making them fast.
What if there was a tool to speed it all up?
This tool has a name, it is called GPT-4!
In this guide, we’ll be taking a look at:
- The evolution of ChatGPT, from its rise to understanding the trustworthiness of large language models.
- Lightning-fast app development with GPT-4, including prompt tips and notebook-to-Streamlit app conversion.
- Efficient debugging and codebase changes with GPT-4.
- App performance optimization with GPT-4, and without the stress!
Whether you’re a seasoned Streamlit developer or just getting started, this guide will help you leverage GPT-4 to build better apps, faster.
So grab a cup of coffee (or tea, or whatever your favorite beverage is) and let’s get started!
Some background
The rise of ChatGPT
In November 2022, OpenAI released ChatGPT, and it immediately took the world by storm!
For the first time, people could have meaningful conversations with an AI on any topic and use it for tasks spanning education, creative writing, legal research, personal tutoring, code creation, and more.
As of January 2023, it has over 100 million users, making it the fastest-growing platform ever.
But you might be wondering, how did early-day ChatGPT, powered by GPT-3.5, go at designing Streamlit apps?
It was actually far from perfect, often inaccurate, and required a hefty amount of manual fine-tuning to get the apps right.
GPT-4, the game changer

Released in March 2023, GPT-4 significantly improved short-term memory, parameters, and creativity, leading to far more accurate and creative responses than GPT-3.5.
Another notable perk: GPT-4 was trained on more recent data (up to January 2022) compared to GPT-3.5’s September 2021 cut-off.
So even though GPT-4 may not be aware of Streamlit’s latest feats such as Chat elements or st.experimental_connection(), its newer training data and the aforementioned improvements have really bolstered its ability to create great Streamlit apps.
What about trustworthiness in LLMs
Although GPT-4 has improved its reliability, like other LLMs, it can still produce misleading or fictional outputs known as hallucinations (here’s a good read about them).
These can be attributed to lack of recent data, biases in the training data, and unclear or ambiguous prompts.
You can usually address them by refining your prompts iteratively until you achieve the desired results. Later we’ll cover prompting tips to reduce hallucinations. I’ll also explain how to improve data robustness via GPT-4’s Code Interpreter.
#1: Use GPT-4 for faster Streamlit app development
1.1 — GPT-4 as a starting point for any app
These days, I usually start with GPT-4 when designing any Streamlit app. I then iterate via the chat interface to quickly experiment with various prompt ideas.
Getting started is easy as 1, 2, 3:
- It starts with a good prompt!
Include an Altair bar chart and an Altair line chart. Include at least 2 numerical input sliders in the sidebar
- 1 slider for the Altair bar chart at the top of the app
- 1 slider for the Altair line chart at the bottom of the app
The app should allow Adrien to predict the rise of generative AI in the next 5 years. Will we reach singularity?
- Go to ChatGPT and select
GPT-4. You'll need a ChatGPT Plus subscription to access it. - Paste the prompt into the ChatGPT.
- Try the generated code on your local machine. If you’re new to Streamlit, follow the installation steps here.
Let’s check the Streamlit app generated by GPT-4 below:
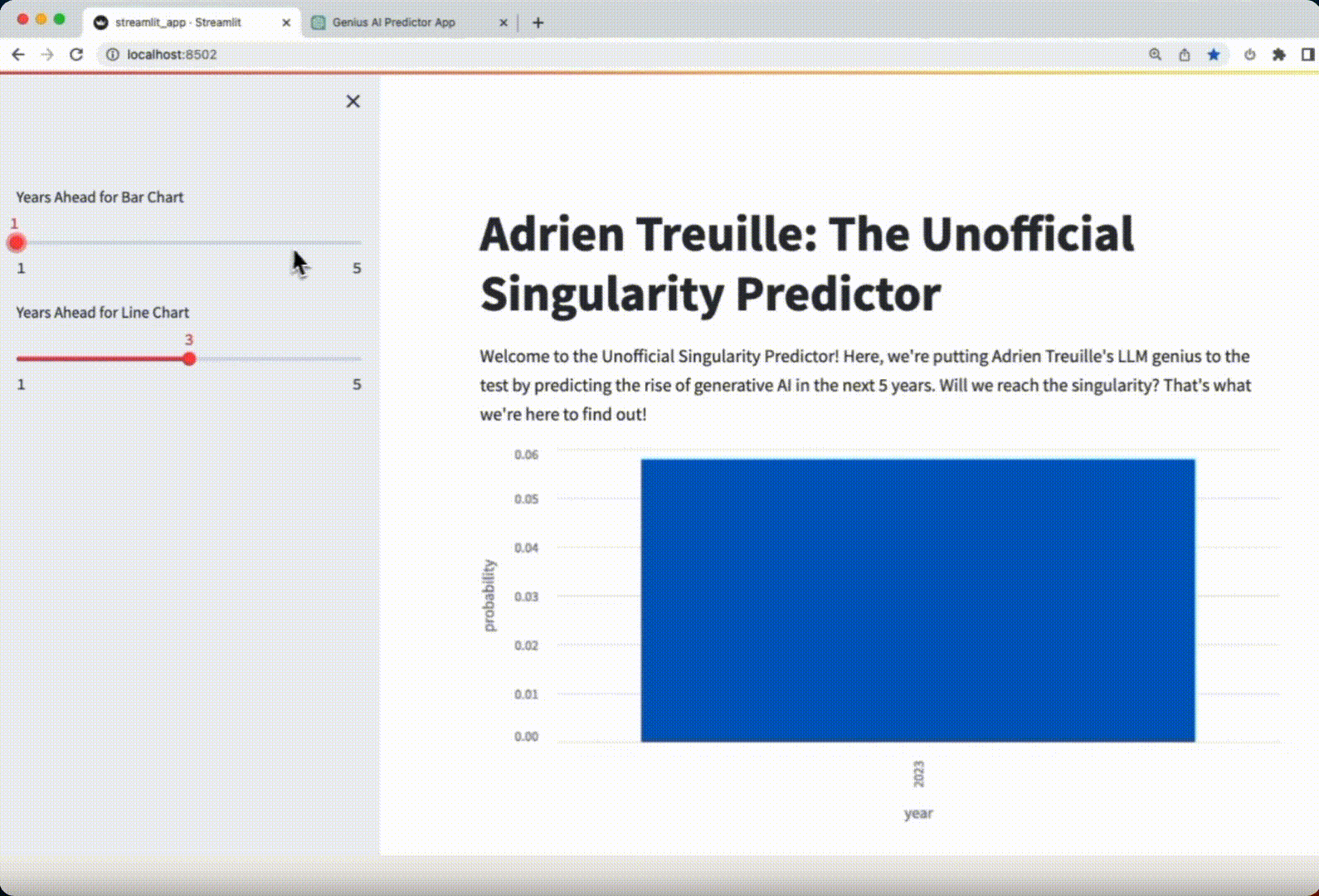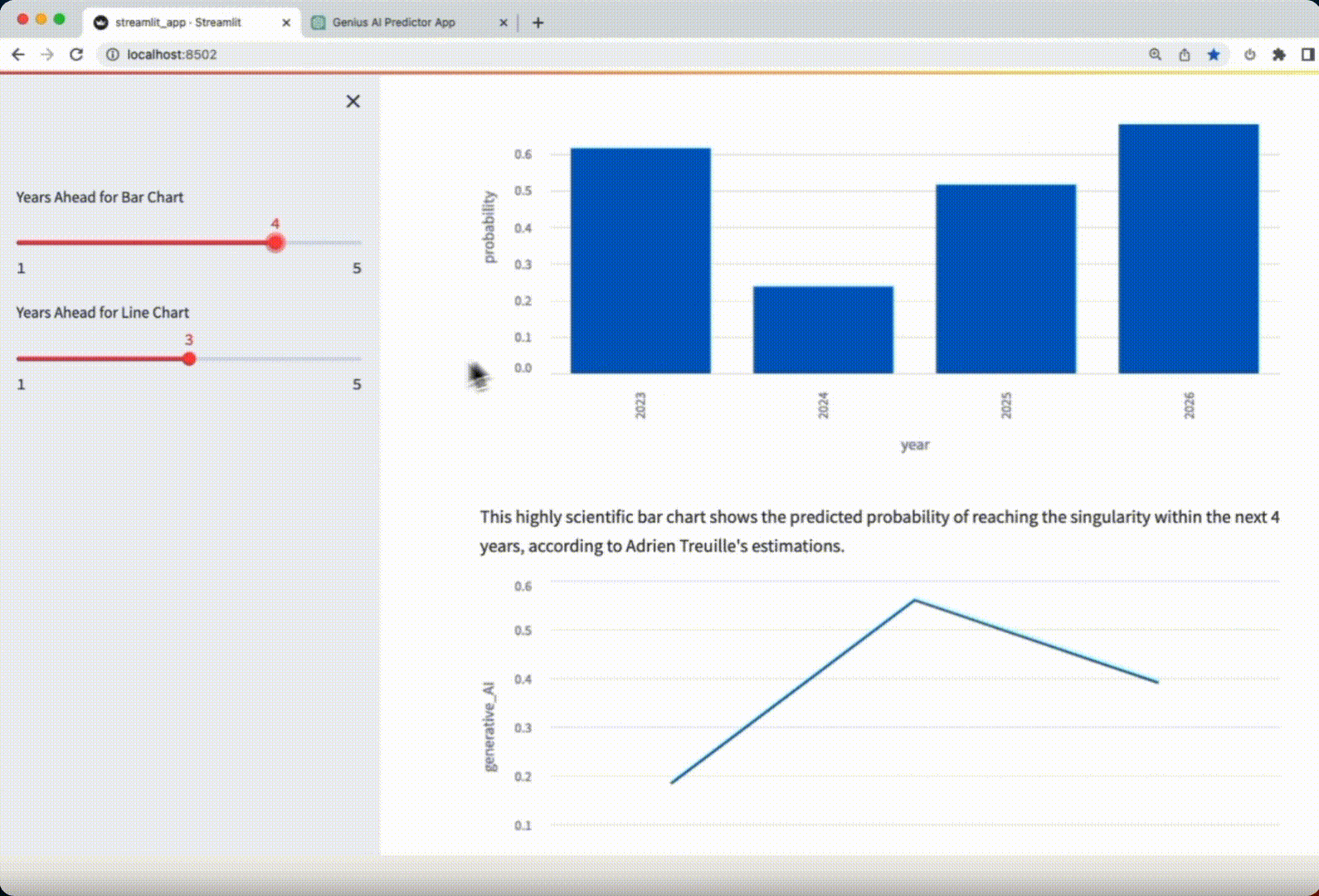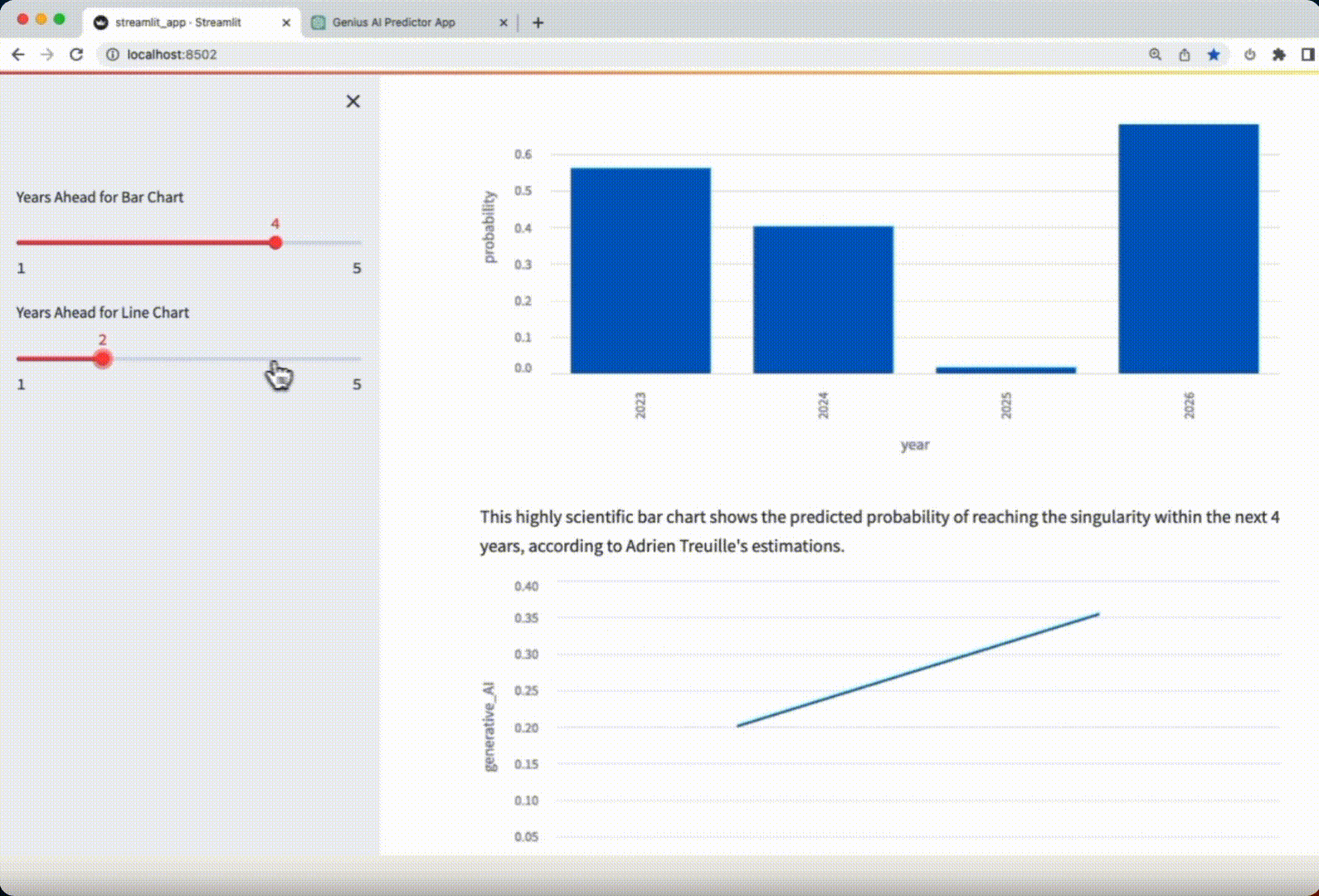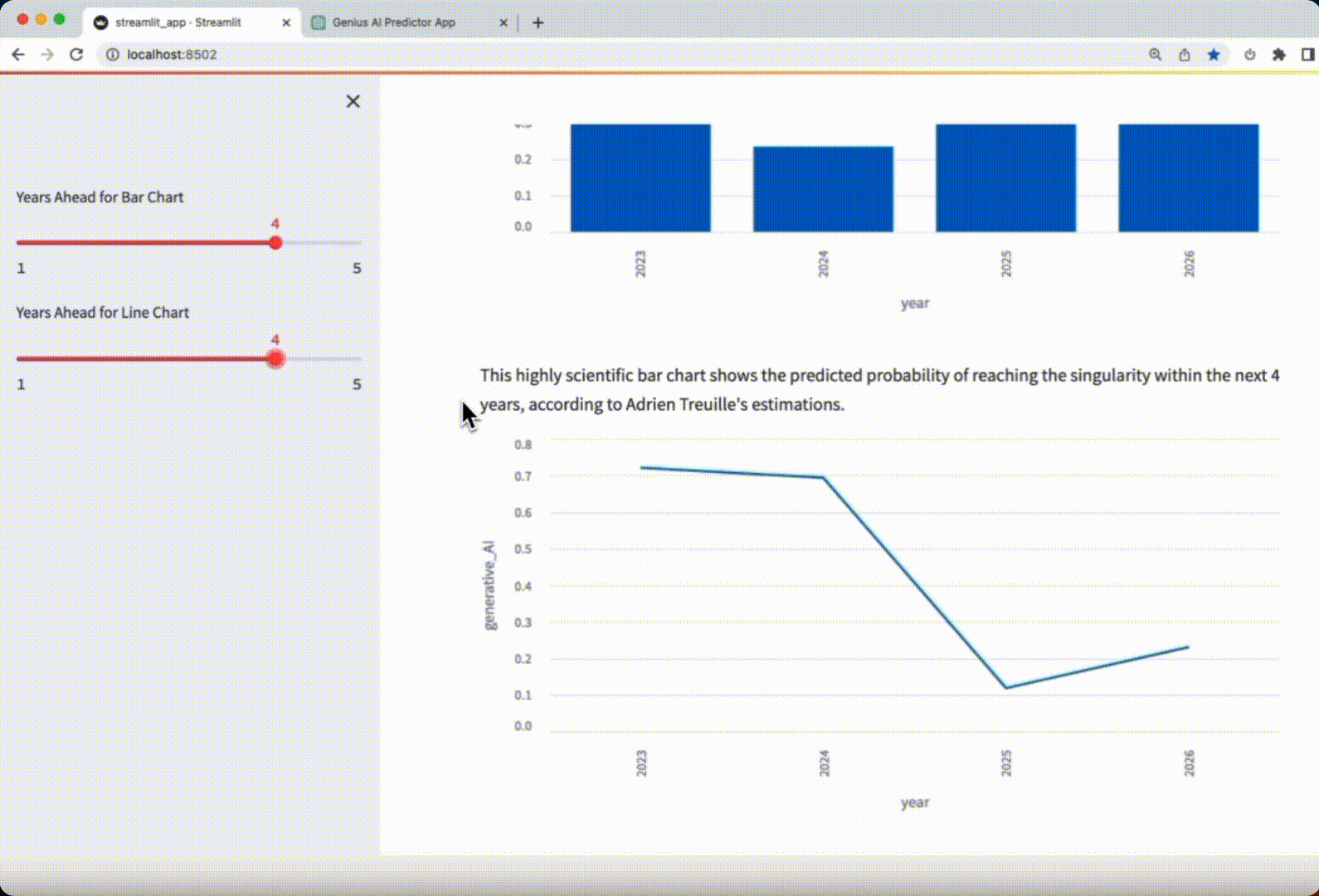
Verdict: the app is impeccable! Not a single change had to be made to make the app work.
1.2 — Prompting tips to streamline your app design
“Garbage in, Garbage out” applies well to prompting. The code quality greatly depends on the prompts you put in!
So what makes a good prompt for designing Streamlit apps?
In the prompt above, my instructions are clear. I specified the tone, context, app features, and added the charts and widgets I wanted to see.
Here are 5 prompting tips to help you get started:
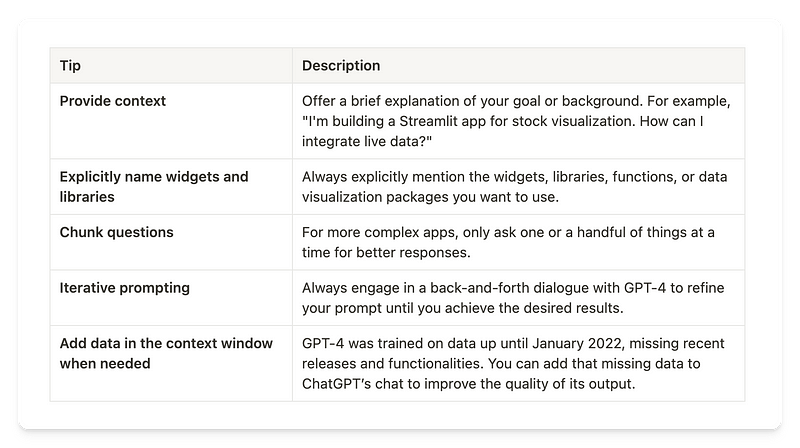
By following these simple guidelines, you should be able to get the desired results faster, reducing the need for back-and-forth conversations in the ChatGPT interface.
Now, let’s explore some more practical use cases!
1.3 — Convert Jupyter notebooks to Streamlit apps in minutes
If creating Streamlit apps from scratch is fun, converting your Jupyter notebooks into Streamlit apps is even funner!
GPT-4 can seamlessly automate most of the these conversion steps, such as:
- Replacing traditional Python syntax with their Streamlit counterparts.
- Remove Jupyter-specific imports and replace them with Streamlit-specific ones.
- Excluding Jupyter-specific components like cell magics (%%) and comments.
Below is a Jupyter notebook. I’m asking GPT-4 to convert it into a Streamlit app.
Jupyter notebook — before GPT-4 processing:
# [Cell 1]
import numpy as np
import matplotlib.pyplot as plt
# [Cell 2]
# Generate random data
data = np.random.randn(1000)
[Cell 2]
# Generate random data
data = np.random.randn(1000)
# [Cell 3]
# Cell magic for inline plots
%%matplotlib inline
# [Cell 4]
# User input for number of bins
bins = int(input("Enter number of bins for histogram: "))
# [Cell 5]
# Plot histogram
plt.hist(data, bins=bins)
plt.title("Random Data Histogram")
plt.xlabel("Value")
plt.ylabel("Frequency")
plt.show()Converted Streamlit app — after GPT-4 processing:
import streamlit as st
import numpy as np
import matplotlib.pyplot as plt
# Title for the Streamlit app
st.title("Random Data Histogram")
# Generate random data
data = np.random.randn(1000)
# User input for number of bins using Streamlit's slider
bins = st.slider("Choose number of bins for histogram", 10, 100, 50)
# Plot histogram
fig, ax = plt.subplots()
ax.hist(data, bins=bins)
ax.set_title("Random Data Histogram")
ax.set_xlabel("Value")
ax.set_ylabel("Frequency")
st.pyplot(fig)GPT-4 did it again!
- Python syntax has been converted to the equivalent Streamlit syntax.
- Jupyter-specific imports were replaced with Streamlit ones.
- Jupyter-specific components like cell magics and redundant comments were removed.
Onward to debugging apps with GPT-4!
#2: Lightning fast debugging + enhanced codebase management
2.1 — Swiftly analyze error log traces to identify issues
As a developer advocate, a big part of my job is about debugging Streamlit apps.
I build demos, submit pull requests, and spend time on forums assisting users in our community.
And while it’s crucial to always double-check the accuracy of its outputs, GPT-4 is still a tremendous tool to quickly scan through error logs and find the root causes of any bugs or issues.
Here’s a simple example.
Paste this cryptic error message from Streamlit’s error logs into ChatGPT’s interface and press send:
File “/home/adminuser/venv/lib/python3.9/site-packages/streamlit/runtime/scriptrunner/script_runner.py”, line 552, in _run_script
exec(code, module.dict)
File “/mount/src/stroke_probability/Stroke_Proba.py”, line 66, in
svm1, svm2, logit1, logit2, nbc1, nbc2, rf1, rf2, errGBR = loadAllModels(URL)
File “/home/adminuser/venv/lib/python3.9/site-packages/streamlit/runtime/caching/cache_utils.py”, line 211, in wrapper
return cached_func(*args, **kwargs)
File “/home/adminuser/venv/lib/python3.9/site-packages/streamlit/runtime/caching/cache_utils.py”, line 240, in call
return self._get_or_create_cached_value(args, kwargs)
File “/home/adminuser/venv/lib/python3.9/site-packages/streamlit/runtime/caching/cache_utils.py”, line 266, in _get_or_create_cached_value
return self._handle_cache_miss(cache, value_key, func_args, func_kwargs)
File “/home/adminuser/venv/lib/python3.9/site-packages/streamlit/runtime/caching/cache_utils.py”, line 320, in _handle_cache_miss
computed_value = self._info.func(*func_args, **func_kwargs)
File “/mount/src/stroke_probability/Stroke_Proba.py”, line 58, in loadAllModels
joblib.load(
File “/home/adminuser/venv/lib/python3.9/site-packages/joblib/numpy_pickle.py”, line 577, in load
obj = _unpickle(fobj)
File “/home/adminuser/venv/lib/python3.9/site-packages/joblib/numpy_pickle.py”, line 506, in _unpickle
obj = unpickler.load()
File “/usr/local/lib/python3.9/pickle.py”, line 1212, in load
dispatchkey[0]
GPT-4 will analyze the error trace and provide relevant recommendations in seconds:

Fast. Efficient. And not a single StackO or Google search in sight! Hallelujah!
But what if we need to go beyond simple error log trace debugging and review bugs and code changes not only for a single file but multiple files?
Let’s see how GPT-4 can help us.
2.2 — Overcoming the context window limitations
In LLM terminology, the context window refers to the maximum number of tokens (words or characters) that a language model can “see” at once when generating a response.
The GPT-4 model available in ChatGPT Plus has a context window limit of 8,192 tokens, which is twice what GPT-3.5 currently provides.
However, even with 8,192 tokens, it may not be sufficient to analyze most codebases.
Enter GPT-4’s Code Interpreter!
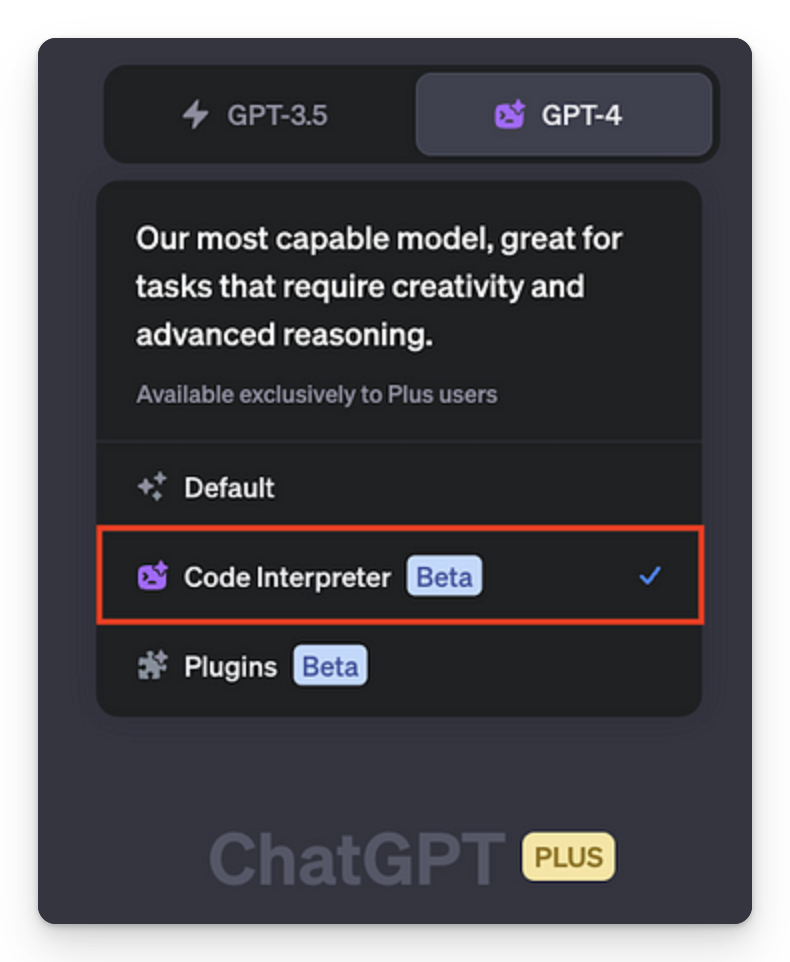
GPT-4’s Code Interpreter lets you upload files in various formats (zip, txt, pdf, doc, excel, and more) and securely run code or analyze data right in the ChatGPT interface!
It also runs separately from the chat in a sandboxed environment, enabling analysis of large codebases without that context window constraint.
So let’s go ahead and give it a try in the section below — you’ll be amazed at what it can do!
2.3 — Reshape any code, anywhere in your codebase
Let’s use one of my Streamlit apps as an example.
I created the CodeLlama Playground app to showcase the capabilities of Meta’s new CodeLlama model. You can get the repo here.
DeepInfra, the company hosting the CodeLlama model, has recently introduced Mistral 7-B, a new open-source LLM that competes with CodeLlama in terms of performance.
I want to update my Streamlit app with the new Mistral algorithm. Let’s see how GPT-4 can help us.
- Head to the GitHub repo and download it by clicking on
Download ZIP.
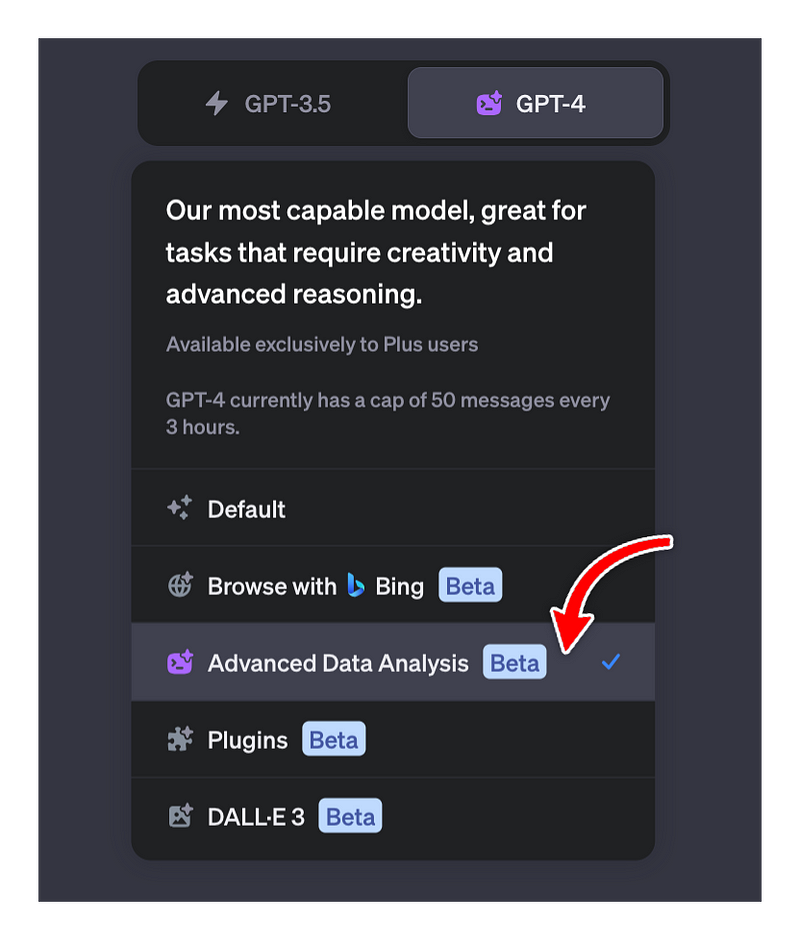
- Open a ChatGPT session and choose the ‘Advanced Data Analysis’ option to enable GPT-4’s Code Interpreter.
- Upload the repo.
- Add this prompt:
import openai
Configure OpenAI client to use our endpoint
openai.api_key = “<YOUR DEEPINFRA TOKEN: deepctl auth token>” openai.api_base = “https://api.deepinfra.com/v1/openai"
chat_completion = openai.ChatCompletion.create( model=”mistralai/Mistral-7B-Instruct-v0.1", messages=[{“role”: “user”, “content”: “Hello”}], )
print(chat_completion.choices[0].message.content)`
I want the Mistral model to be selectable from a radio menu in the app’s sidebar, along with other models
- GPT-4 will scan the entire codebase, analyze the files, integrate the Mistral model into the Streamlit app, and make the necessary modifications throughout the repo.
- Once that’s done, ask ChatGPT for permission to download the edited repo.
- Replace your local repo with the updated one and check the app.
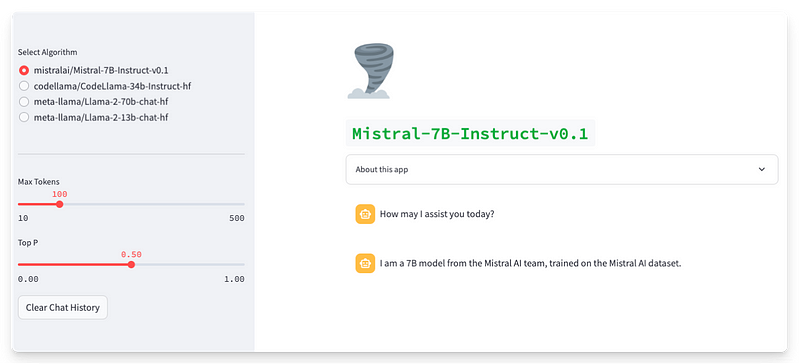
The app is working well! The Mistral 7b can be selected from the radio selector in the top left section, along with other Llama models. I added the cyclone emoji manually, but the rest of the content was generated by GPT-4.
The entire process, from prompting to updating the app, was done in less than 2 minutes. Impressive!
#3: From sluggish to speedy, use GPT-4 to improve your app performance
3.1 — Automatically diagnose performance issues
Web apps need to be fast. A fast web app keep users happy and coming back for more.
Below I have created an app with suboptimal coding, causing performance issues:
import streamlit as st
import pandas as pd
import sqlalchemy as db
import requests
import tensorflow as tf
price = st.number_input("House Price", min_value=100000, max_value=10000000, step=100000)
def load_data():
return pd.read_csv('large_dataset.csv')
data = load_data()
used_columns = ['Column1', 'Column2', 'Column3']
data = data[used_columns]
def download_model():
url = "<https://example.com/large-model.h5>"
response = requests.get(url)
with open('large-model.h5', 'wb') as f:
f.write(response.content)
download_model()
model = tf.keras.models.load_model('large-model.h5')
def load_efficient_data():
return pd.read_parquet('efficient_data.parquet')
efficient_data = load_efficient_data()
database_uri = 'sqlite:///example.db'
engine = db.create_engine(database_uri)
query = "SELECT * FROM large_table WHERE condition = true"
db_data = pd.read_sql_query(query, con=engine)If you paste this code into ChatGPT and ask for performance improvements — GPT-4 can identify areas for improvement in seconds!
Here’s a breakdown of how GPT-4 would address each issue:
Recommendation 01: Add caching
The load_data function is called without caching, causing it to read the CSV file from the disk every time it's called, impacting performance. To mitigate this, use @st.cache to cache function results, reducing the need for recomputing data with each interaction.
Pre (no caching):
def load_data():
return pd.read_csv('precalculated_data.csv')
data = load_data()Post (with caching):
@st.cache(ttl=24*60*60) # Cache the data with a time-to-live of 24 hours
def load_data():
return pd.read_csv('precalculated_data.csv')
data = load_data()Recommendation 02: Avoid downloading large, static models
The download_model function downloads the large model file every time the app is run. This can impact the app's performance, especially if the model file is very large. To avoid this, store the model on the production machine or use Git LFS to manage large files in your repository.
Pre (without efficient model management):
import requests
import tensorflow as tf
def download_model():
url = "<https://example.com/large-model.h5>"
response = requests.get(url)
with open('large-model.h5', 'wb') as f:
f.write(response.content)
download_model() # This will download the model every time the app runs
model = tf.keras.models.load_model('large-model.h5')
Post (with efficient model management):
import tensorflow as tf
import os
model_path = 'models/large-model.h5'
if not os.path.exists(model_path):
# Code to download the model
import requests
url = "<https://example.com/large-model.h5>"
response = requests.get(url)
os.makedirs(os.path.dirname(model_path), exist_ok=True)
with open(model_path, 'wb') as f:
f.write(response.content)
model = tf.keras.models.load_model(model_path)Recommendation 03: Use efficient binary-serialized formats
Reading data from a CSV file can be slow, especially for large datasets. You should use efficient binary-serialized formats like Apache Parquet or Apache Arrow for storing and reading large datasets.
Pre (without Parquet):
def load_data():
return pd.read_csv('large_dataset.csv') # Reading data from a CSV file
data = load_data()Post (with Parquet):
def load_efficient_data():
return pd.read_parquet('large_dataset.parquet') # Reading data from a Parquet file
efficient_data = load_efficient_data()
Yet again, in merely a few seconds, GPT-4 was able to propose these significant performance enhancements, a remarkable feat indeed!
Since these changes were made in one file, let’s spice things up a bit and test GPT-4’s ability to diagnose similar performance issues on a larger codebase.
3.2 — Diagnosing caching issues in large codebases
One of the best ways to speed up your Streamlit app is to leverage caching methods. Put simply, these methods optimize performance by eliminating redundant recalculations.
Streamlit offers two caching mechanisms, @st.cache_data and @st.cache_resource:
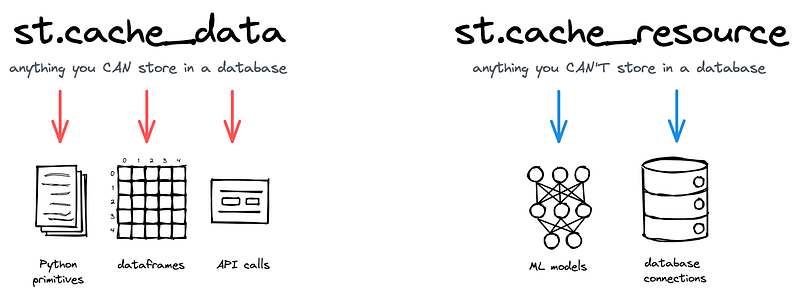
@st.cache_datais ideal for functions that return data types such as DataFrames and arrays. It addresses mutation and concurrency issues via serialization.@st.cache_resourceis tailored for caching global resources, for instance, ML models or database connections.
Adding caching methods to functions in a single Python file is ususally straightforward, but it can be tricky to figure out which functions to cache and which caching method to choose when you’re working with multiple files and a larger codebase.
GPT-4’s Code Interpreter to the rescue, yet again!
I’ve created a demo app with multiple Python functions, spread across different files. You can download it here.
/my_streamlit_app/
|– data/
| |– large_dataset.csv
|-- models/
| |-- heavy_model.pkl
|-- src/
| |-- data_loader.py
| |-- model_loader.py
| |-- predictor.py
| |-- transformer.py
| |-- analyser.py
| |-- forecast.py
|-- streamlit_app.py
|-- requirements.txt
Some of these functions either involve heavy I/O or compute tasks and currently lack caching. As a result, the app is loading slowly and each operation is sluggish.
We want the Code Interpreter to inspect the entire codebase and do the following:
- Identify the functions that would benefit from caching.
- Suggest the best caching method based on what each function does.
- Implement those changes for us.
Here’s the process:
- Upload the repo to ChatGPT.
- Add this prompt:
Identify functions in the codebase that would benefit from caching.
Recommend appropriate caching techniques, either @st.cache_data or @st.cache_resource decorators.
Create a markdown table with the following columns:
- Column 1: file name where we need the caching methods.
- Column 2: function name to add the cache to.
- Column 3: recommended caching methods.
- Column 4: reason for using that cache method.
- Visit this URL and copy the body text from each page. This will help GPT-4 learn about our newest caching methods that were not available during its training. It will improve the quality of ChatGPT’s answers.
- Press
send message. - Check GPT-4’s output:

- Ask ChatGPT to implement these changes and give us a downloadable copy of the edited repo.
Hooray! GPT-4 has not only provided us with a clear recommendation sheet that we can share with our peers and colleagues, but it has also implemented all of those changes for us across the entire codebase. The code is now ready to be copied into your local or deployed environment!
Isn’t that amazing?
Wrapping up
We’ve covered a lot in this guide!
After a preamble to ChatGPT, GPT-4, and LLM trustworthiness, we provided prompting tips for various use cases of GPT-4 in app design and debugging.
We have then gone beyond single-file analysis and discussed ways to automatically refactor your apps, codebase, and optimize performance at scale, all made possible with GPT-4’s Code Interpreter.
Keep in mind that we’ve barely scratched the surface of what’s possible with GPT-4 in this post. We have yet to explore ChatGPT’s plugin ecosystem, its browsing or vision capabilities! (Psst... I will cover great use cases leveraging ChatGPT Vision in Part 2!).
As a final word, I would encourage you to think outside the box and embrace creativity in your prompts, you may just be blown away by the convos that will follow!
Please share your comments, use cases and tips below. Also, keep an eye on my Twitter/X feed, where I regularly share cool LLM use cases!
Happy Streamlit-ing! 🎈




Comments
Continue the conversation in our forums →