In my previous article, I explored how GPT-4 has transformed the way you can develop, debug, and optimize Streamlit apps.
With OpenAI’s latest advancements in multi-modality, imagine combining that power with visual understanding.
Now, you can use GPT-4 with Vision in your Streamlit apps to:
- Build Streamlit apps from sketches and static images.
- Help you refine your apps' user experience, including debugging and documentation.
- Overcome LLMs limitations and hallucinations.
In this article, I'll walk you through 8 practical use cases that exemplify new possibilities using GPT-4 with Vision!
A brief history of multi-modality in AI
Before we dive into various use cases, it's important to lay some conceptual foundations for multimodality, discuss pioneering models, and explore currently available multi-modal models.
Multi-modal LLMs are an AI systems trained on multiple types of data such as text, images, and audio, as opposed to traditional models that focus on a single modality.
The journey towards multi-modality has seen significant strides over the recent years, with various models paving the way:
- CLIP, the OG model introduced by OpenAI in 2021, emerged as a pioneering model capable of generalizing to multiple image classification tasks with zero and few-shot learning.
- Flamingo, released in 2022, was notable for its strong performance in generating open-ended responses in a multimodal domain.
- Salesforce's BLIP model was a framework for unified vision-language understanding and generation, enhancing performance across a range of vision-language tasks.
GPT-4 with Vision builds on pioneering models to advance the integration of visual and textual modalities. However, it's not the only multi-modal model vying for attention nowadays; Microsoft and Google are also gaining traction:
- Microsoft's LLaVA, using a pre-trained CLIP visual encoder, offers similar performance to GPT-4 despite a smaller dataset.
- Gemini is Google’s multimodal model, which stands out because it is fundamentally designed to be multimodal from the ground up.
Now, to the fun part!
7 practical use cases for GPT-4 Vision
1) You'll need a ChatGPT Plus subscription to access GPT-4 Vision.
2) If you’re new to Streamlit, follow the installation steps here.
1. Sketch your app and watch it come to life
… as my drawing skills are comparable to a cat chasing a laser pointer, I'll use Balsamiq to achieve that hand-drawn mockup feel.
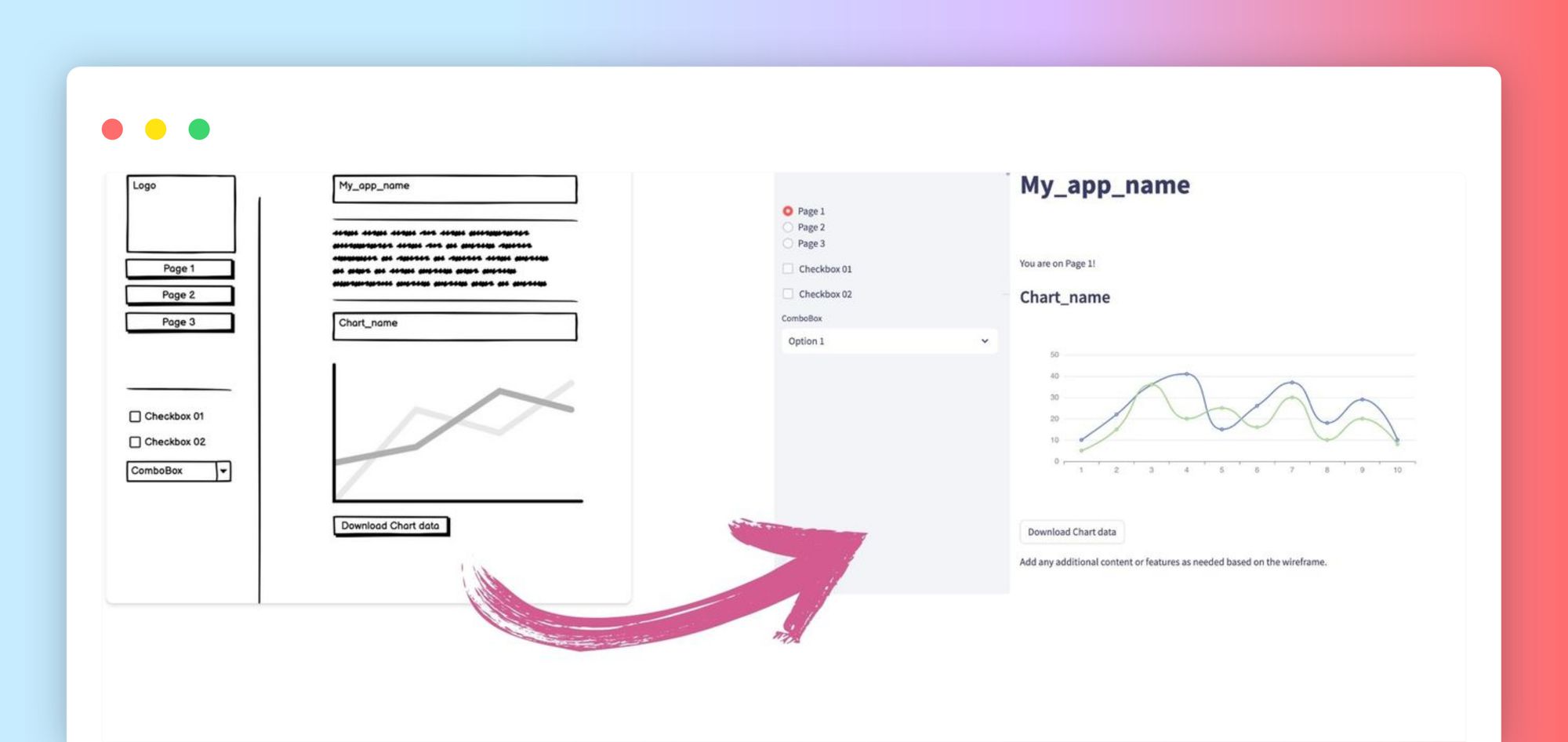
This mockup consists of a two-panel UI. The left panel includes a logo, three navigation links, two checkboxes, and a dropdown. The right panel showcases the app name, a text area, two line charts, and a "Download Chart data" button:
Paste this mock-up image into the ChatGPT interface:

Include the following prompt:
Create a Streamlit app from this mock-up. You will use the Echarts library.
Each data visualization library will have to be installed via
pip install into your virtual environment to work.Check the results:
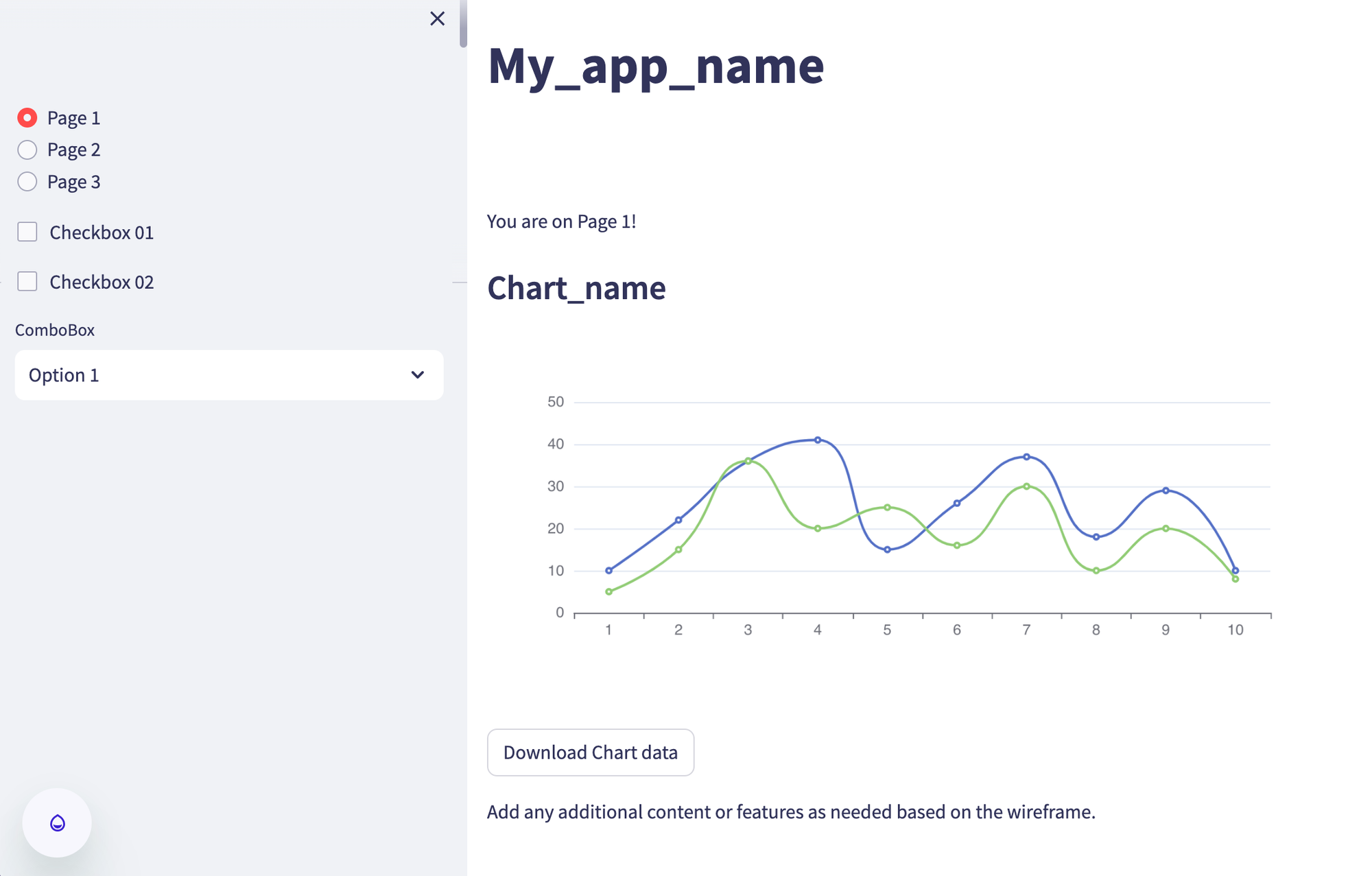
By simply uploading a mockup, Vision generated a fully functional Streamlit prototype: an app with a logo placeholder, navigation links, checkboxes, a combo box, some text, a chart, and a download button. 🙌
2. Turn any static chart into a dynamic data visualization
ChatGPT Vision doesn't just turn scribbles into fully functional Streamlit apps, it can also transform any static visual into a beautiful, interactive, dynamic data visualization.
Paste this screenshot of a Nightingale rose chart from the Echarts library:
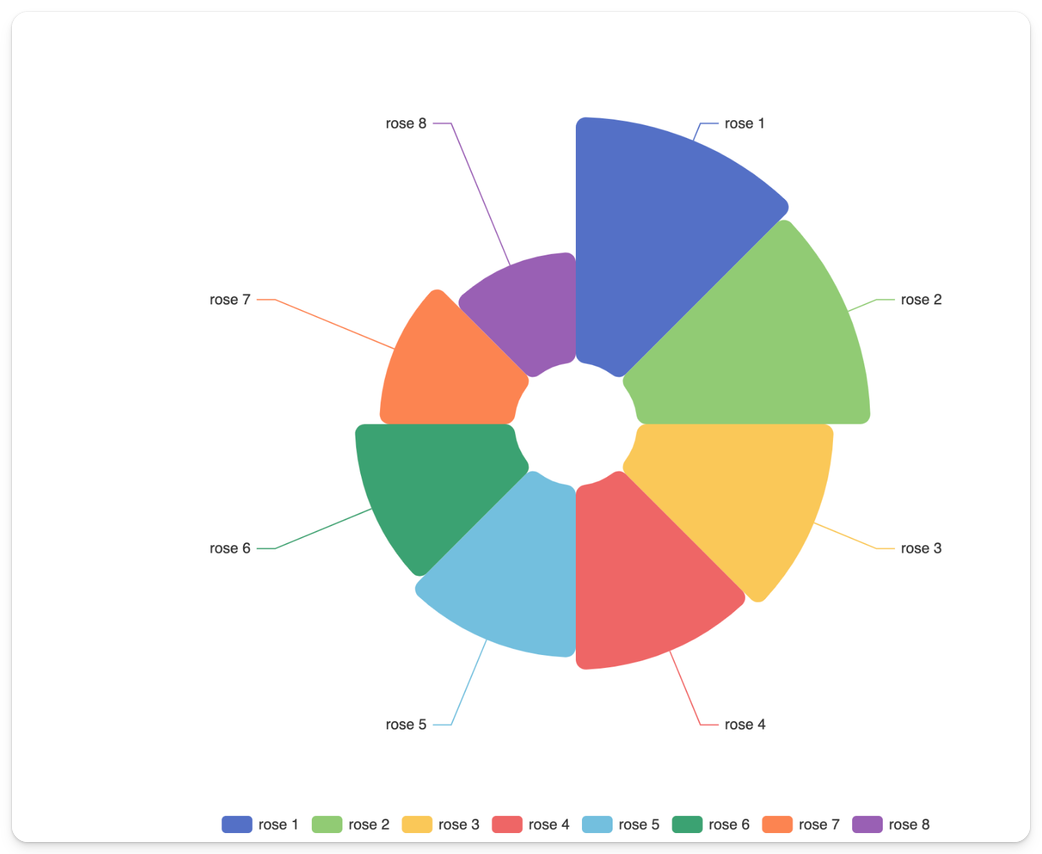
Include this prompt:
Create a nightingale/rose chart in Streamlit. The chart should be a dynamic ECharts chart, via the streamlit-echarts library. Each section should be toggleable. The color scheme of the chart should match the one in the image.
Copy the code into your editor, and voilà!
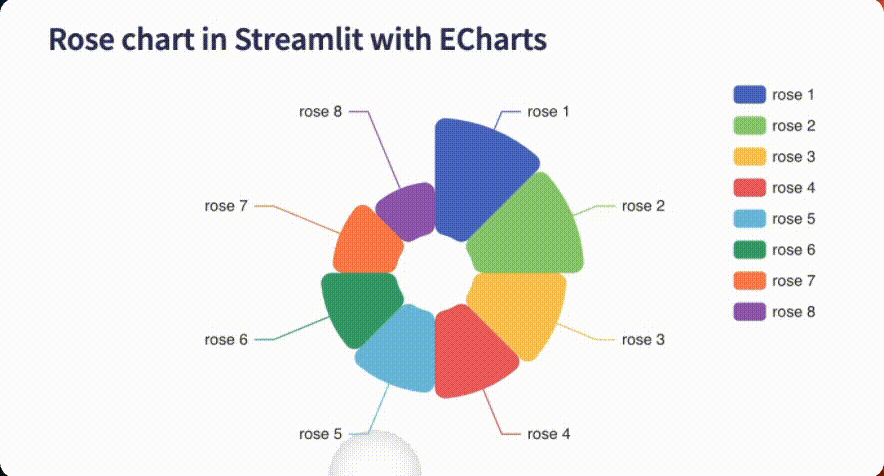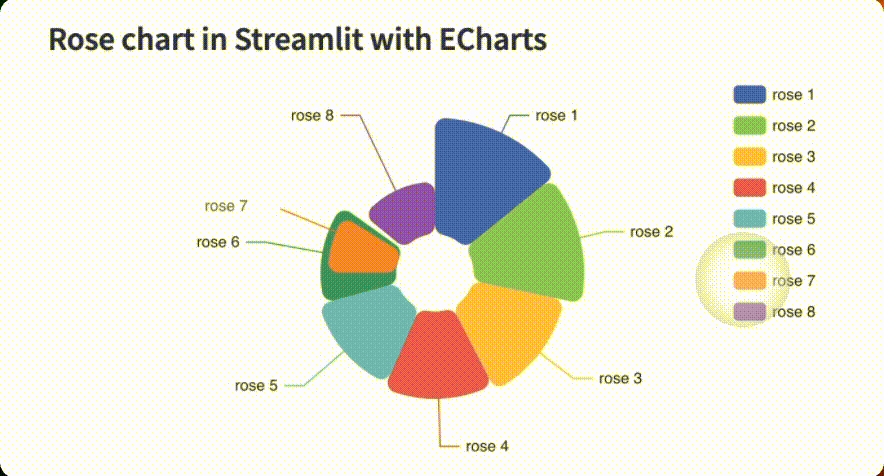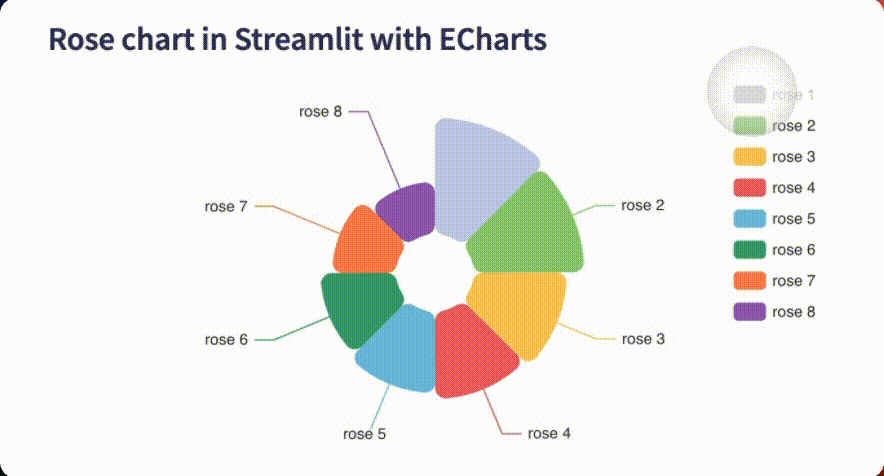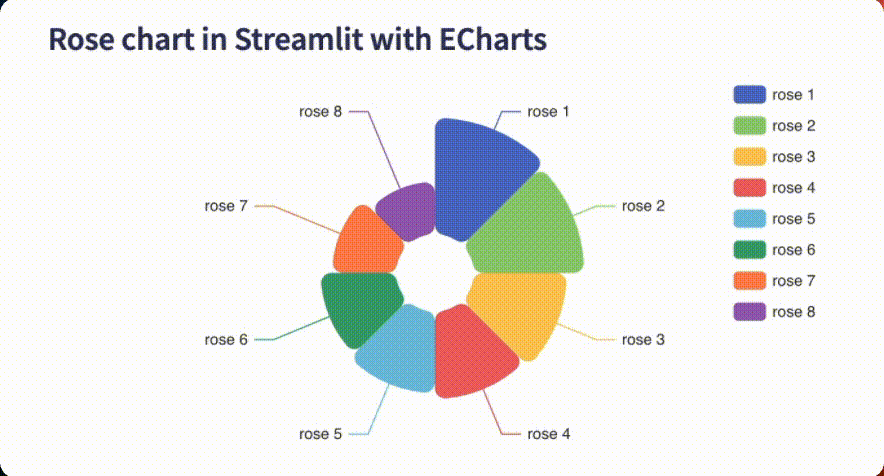
The app displays a dynamic rose chart in Streamlit, with legends, toggleable petals/sections, and a color palette that is a faithful replica of the original!
3. Convert tabular data from images into fully editable tables
ChatGPT Vision is also incredibly useful when you need to extract data from a table that is not copyable nor downloadable.
In this example, we will ask Vision to make this image of tabular data fully editable using Streamlit’s data editor.
Paste this image of a ReactJS table into ChatGPT:
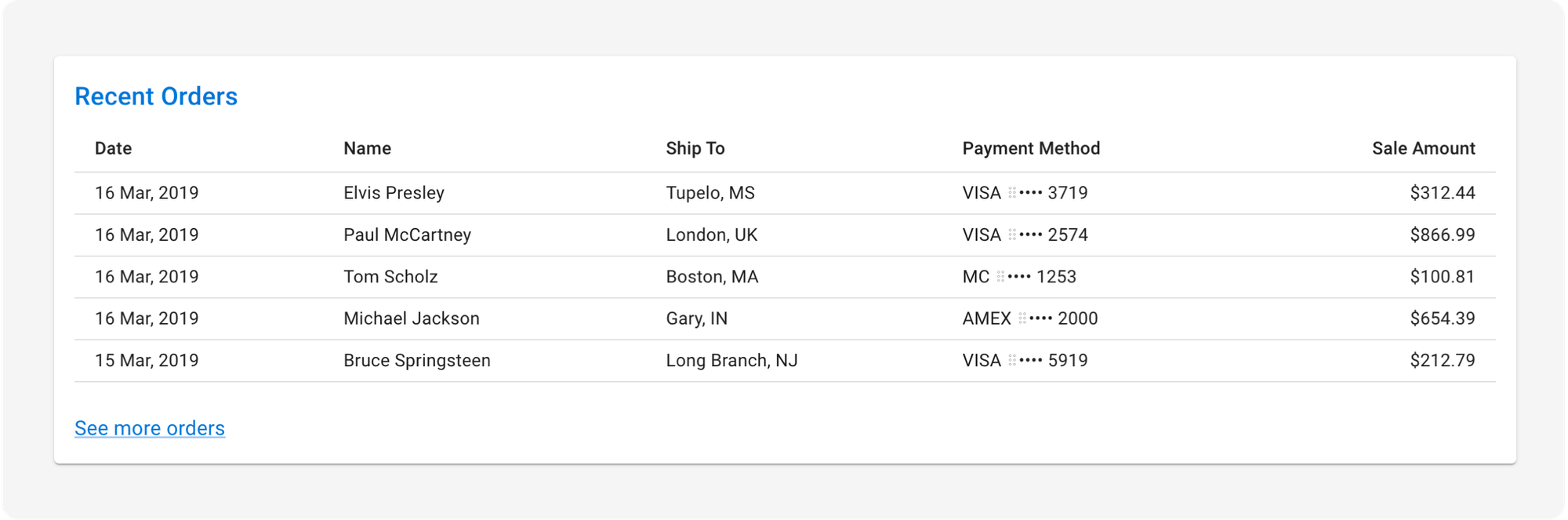
Include this prompt:
Code this table in Streamlit. We want the tabular data fully editable via Streamlit’s data editor.
Paste the code into your editor and review the results:
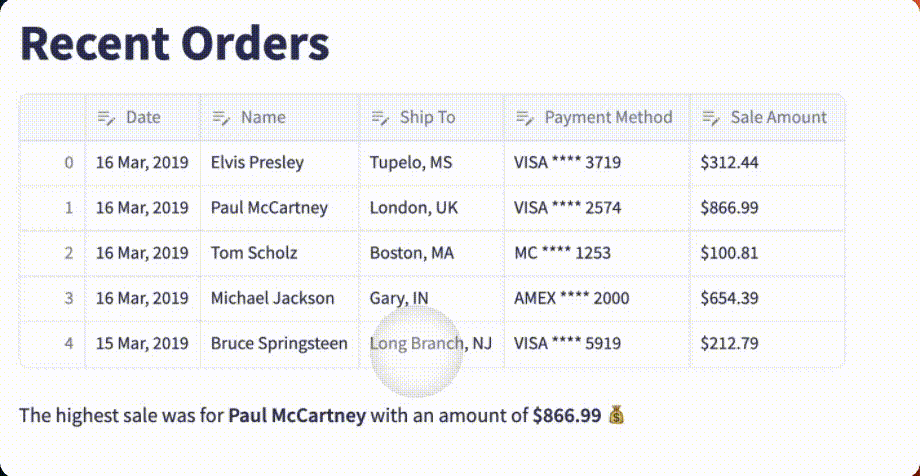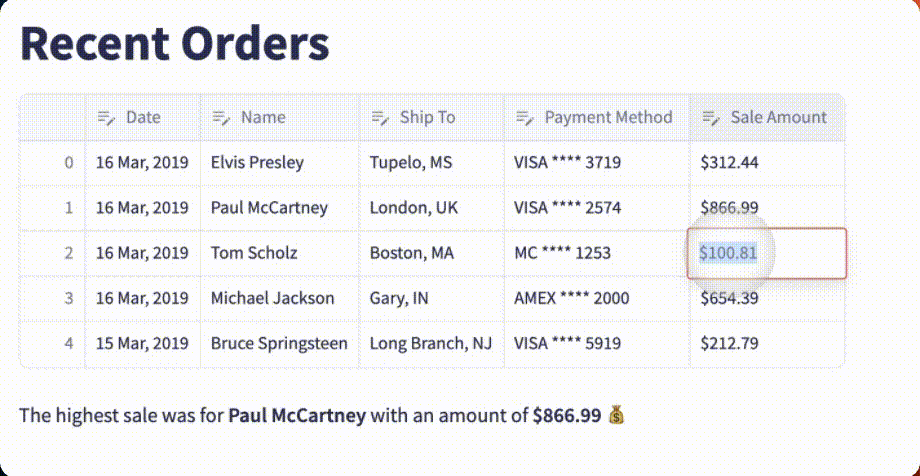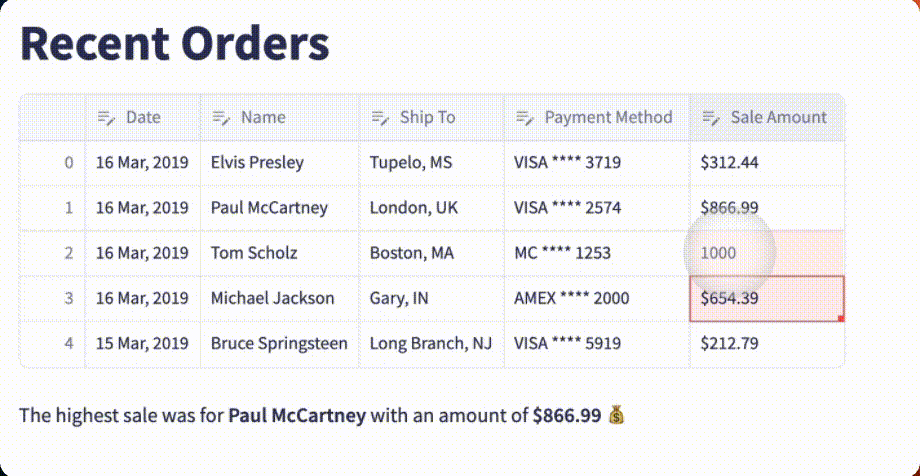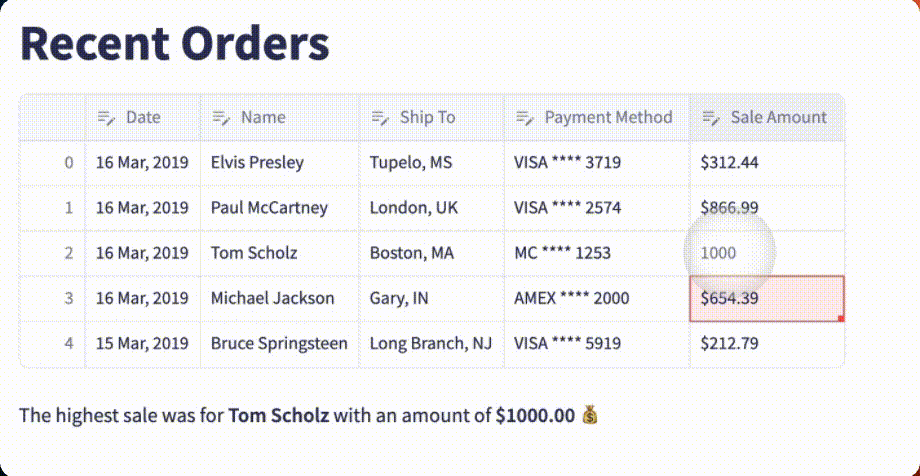
GPT-4 Vision crushed it!
The table is fully functional with the correct headers, each row is flawlessly reproduced, and the data is fully editable. As an added bonus, ChatGPT includes a function to find the highest sale amount and display the associated order!
4. Enhance your app's UX with tailored recommendations
GPT-4 Vision can also help you improve your app's UX and ease the design process for multi-page apps.
Paste a screenshot of complex dashboard app into ChatGPT.
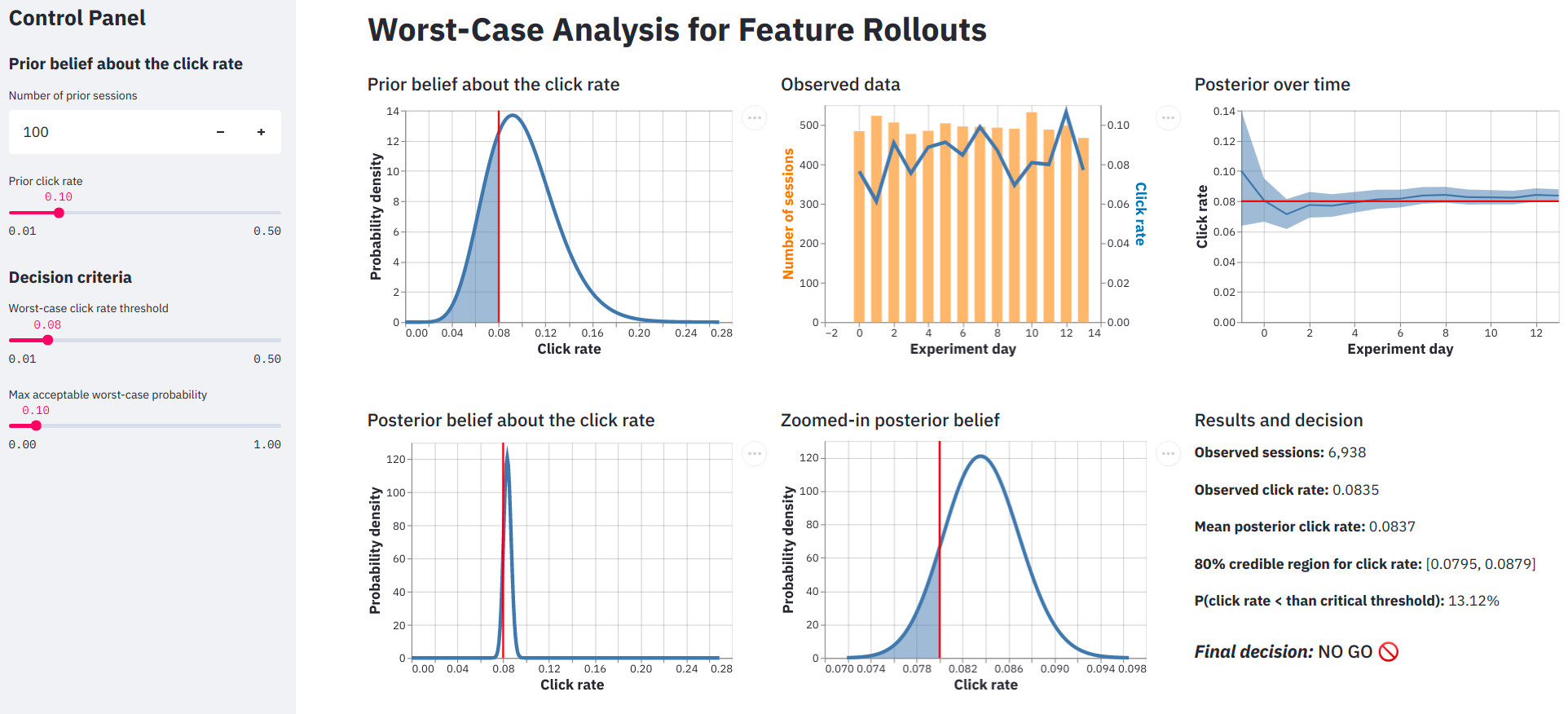
Include this prompt:
Provide 8 suggestions to enhance the usability of this Streamlit app.
ChatGPT's recommendations are pretty spot on!
- Group related controls into visually distinct sections.
- Standardize the UI's color scheme.
- Implement interactive tooltips on various sections and controls.
- Increase the font size of axis labels and graph titles.
- Highlight the final decision output with a colored background.
- Incorporate a feedback mechanism.
- Include a legend for multi-color or line graphs.
- Ensure consistent spacing and alignment between graphs and sections.
5. Conquer LLM hallucinations
There's no doubt that GPT-4 is a significant improvement over its predecessors.
Like all LLMs, it can produce misleading or fictional outputs, known as hallucinations. This can be due to biases in the training data, unclear prompts, or the fact that GPT-4 may not include the most up-to-date data.
This is when Retrieval Augmented Generation (or RAG) comes into play. RAG is a technique that improves chatbots by incorporating external data, ensuring more relevant and up-to-date responses.
For example, GPT-4 is not aware of Streamlit's new colorful headers, as they were not available when it was trained.
We'll start by pasting a screenshot of the new st.header() documentation, which includes our new API parameter for coloring headers:
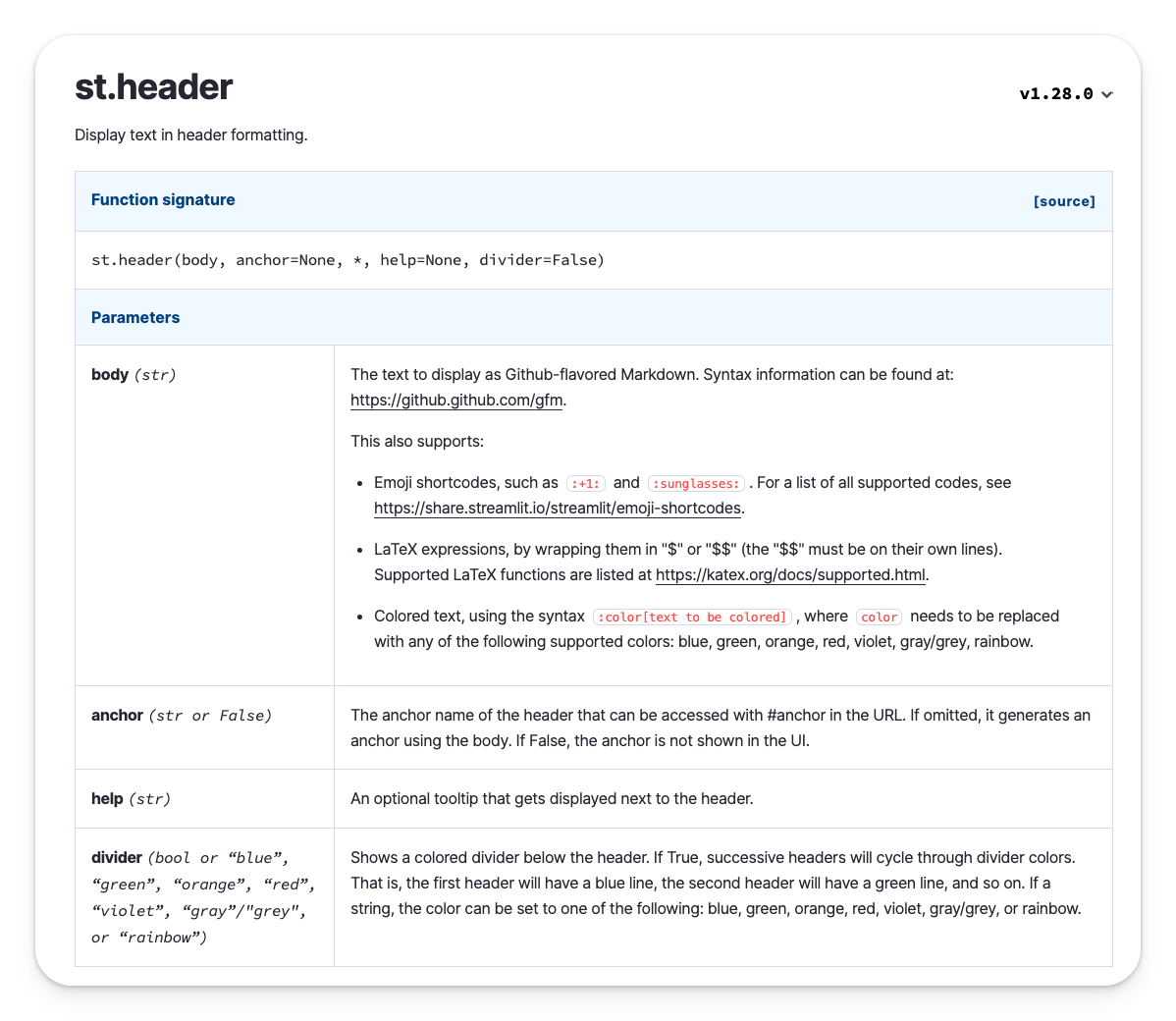
Include this prompt:
Build a Streamlit app featuring variousst.header()in different colors, using the newdividerargument.Include a brief humorous data science pun for each header.Add a corresponding emoji to each header.
Let's look at the results:

6. Debug any app, even when textual logs are missing
As a developer advocate for Streamlit, I spend a big part of my time on forums helping our community users debug their Streamlit apps.
While GPT-4 is an incredibly effective tool for quickly reviewing error logs to find the source of a bug, sometimes, users cannot provide error log traces for various reasons:
- The log trace may contain private data that cannot be shared
- The user may not be able to access the log trace at a specific time.
We may only be given a screenshot of the error callout from the Streamlit front-end, such as the one below:
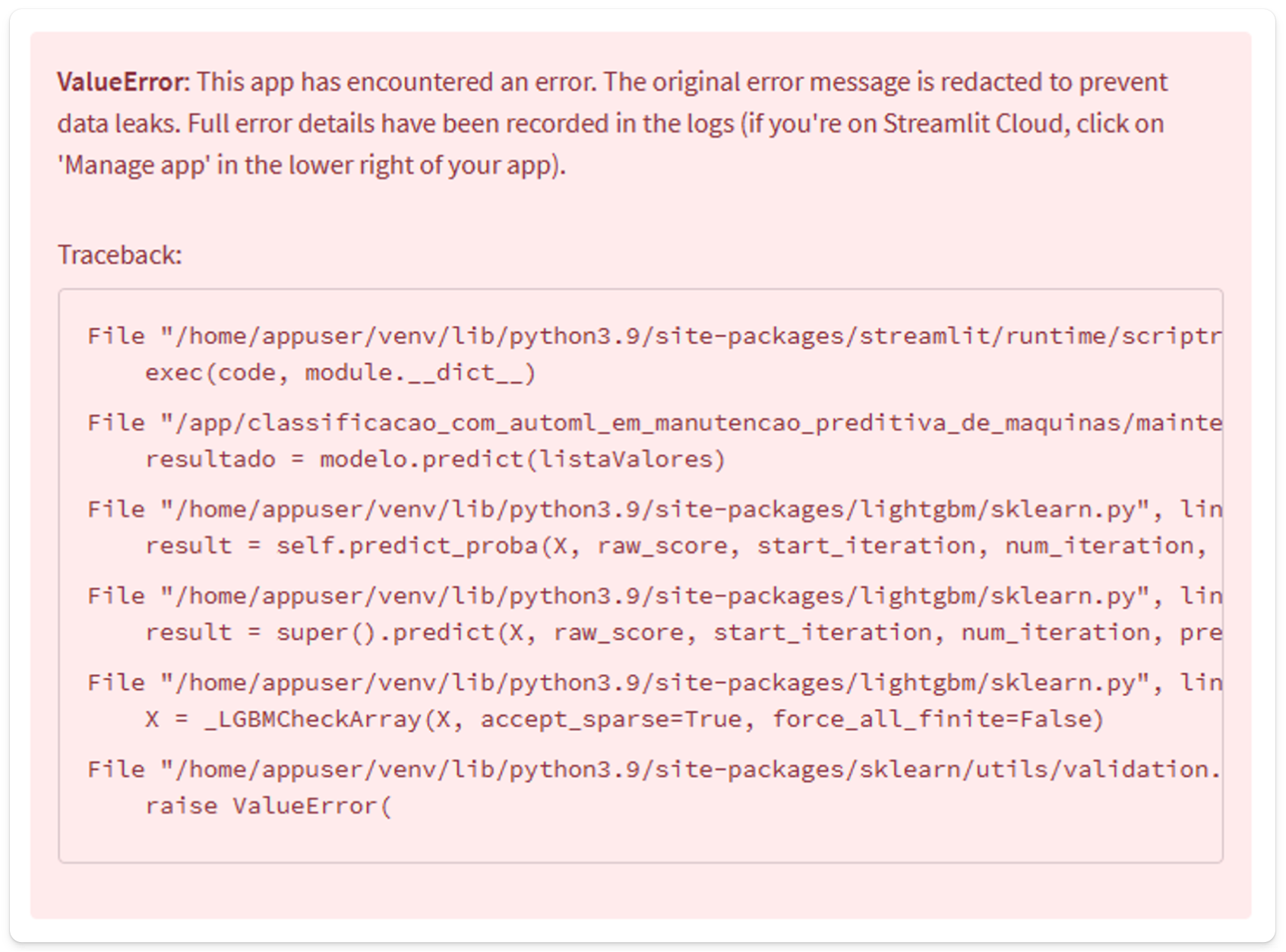
This can make it difficult to debug the issue, as we do not have access to the full log trace.
Fear not! ChatGPT Vision can still assist you by providing useful debugging hints, by extracting relevant information from the screenshot.
Paste the above image with the following prompt:
Give me a clue on the error.
Let’s review ChatGPT's answer:

Verdict ✅
Even though ChatGPT Vision only had access to a partly displayed screenshot of the error and did not have the full textual log trace, it was still able to infer the full error and retrieve the correct answer.
7. Document your apps fast
Once you build your web app, it needs clear documentation to help users get started, understand its features, and learn how to use it. Writing documentation can be time-consuming, but ChatGPT Vision can help streamline the process.
Simply provide a snapshot of your app, and ChatGPT Vision will generate tailored descriptive content that you can use in a document, README, social post, or anywhere else you need it. This not only saves time, but it also ensures that all of the visual details of your app are captured and explained.
Paste a screenshot of my CodeLlama Playground app:
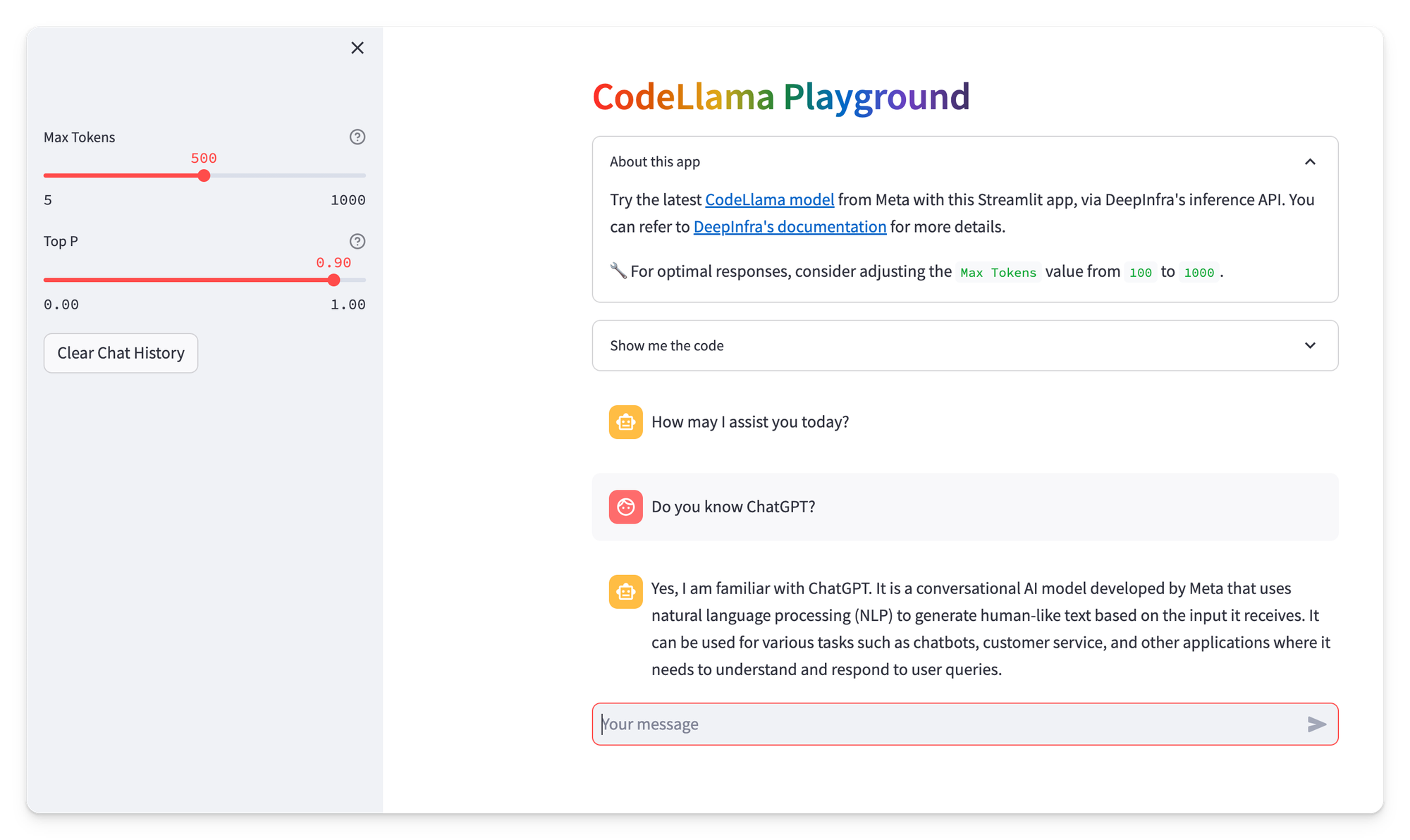
Add this prompt:
Analyze the image I've uploaded, which displays my CodeLlama Playground app. Create a README about it, in Markdown syntax. Add a prerequisite on how to install Streamlit (either locally or on Streamlit Community Cloud).
1) Display all pages in a multi-page app
2) Aid the inference by including any additional descriptive elements (in image or text) if the app's layout lacks sufficient detail.
Let's look at the generated README from markdown:
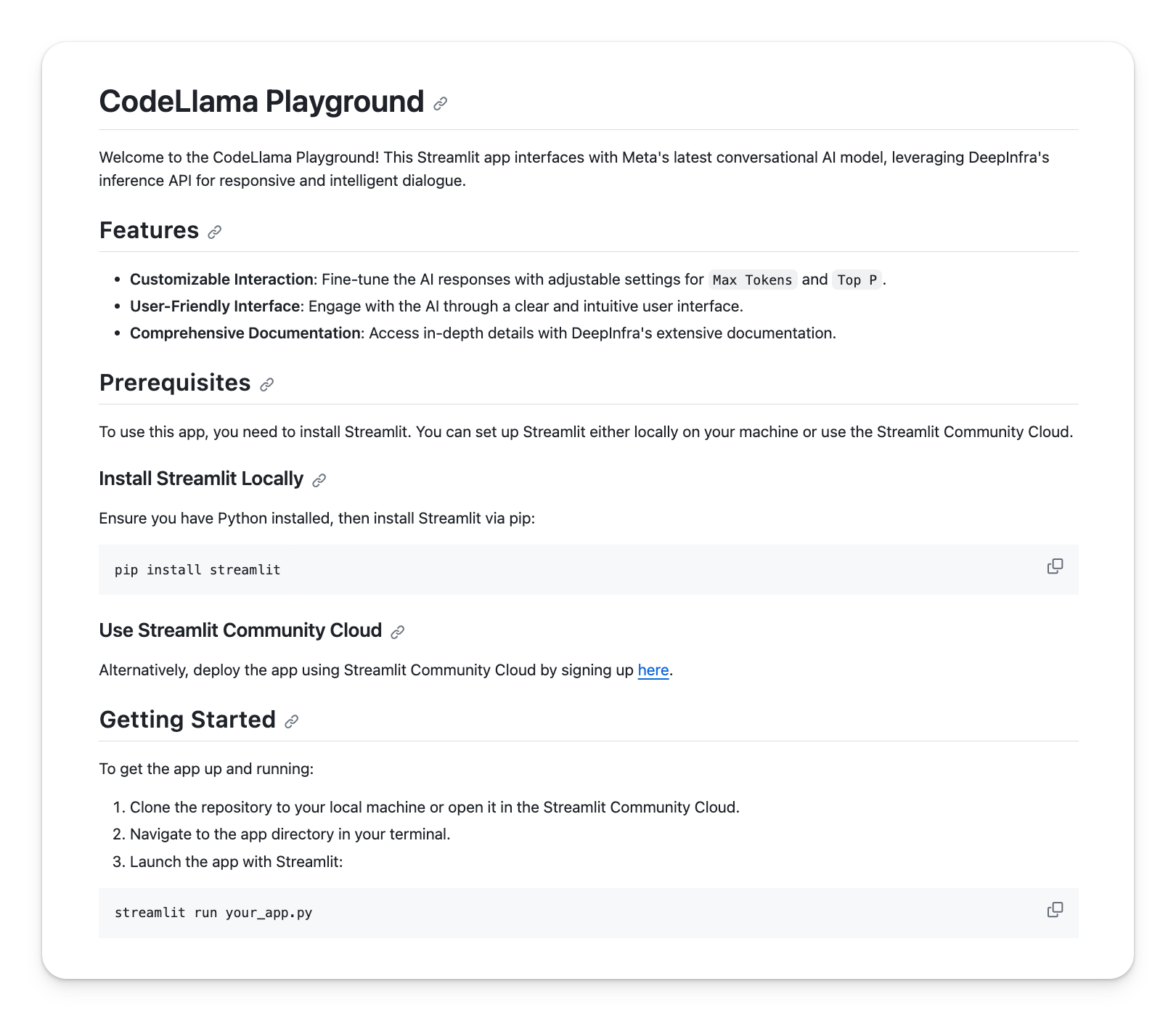
In a matter of seconds, by merely examining the app's UI, ChatGPT Vision generated a ready-to-use README for my CodeLlama Playground app. It accurately listed its features, provided installation instructions for Streamlit both locally and via the Cloud, and offered a quick start guide to launch the app. 🤯
What will you build with GPT-4 Vision?
The OpenAI Vision API also opens up new possibilities and creative combinations. At the time of this writing, GPT-4 with vision is currently only available to developers with access to GPT-4 via the gpt-4-vision-preview.
Until it becomes available world-wide, check out the art of the possible with some creations from the Streamlit community:
- Try out UI Auditor, from Streamlit community member, Kartik. Upload a screenshot of your app's UI, and GPT will tell you how to improve it 🤖
- In this app tease from our Streamlit Creator, Avra, you can upload screenshots (in this case, from scientific publications) to get spot-on analyses.
- Peter Wang, another Streamlit Creator, built a image-to-text-to-speech app to commentate a League of Legends game!
Let your imagination run wild with your prompts, and share what you discover in the comments below!
Also, keep an eye on my Twitter/X feed, where I regularly share cool LLM use cases.




Comments
Continue the conversation in our forums →