
So, you want to build a reliable chatbot using LLMs based on custom data sources?
Models like GPT are excellent at answering general questions from public data sources but aren't perfect. Accuracy takes a nose dive when you need to access domain expertise, recent data, or proprietary data sources.
Enhancing your LLM with custom data sources can feel overwhelming, especially when data is distributed across multiple (and siloed) applications, formats, and data stores.
This is where LlamaIndex comes in.
LlamaIndex is a flexible framework that enables LLM applications to ingest, structure, access, and retrieve private data sources. The end result is that your model's responses will be more relevant and context-specific. Together with Streamlit, LlamaIndex empowers you to quickly create LLM-enabled apps enriched by your data. In fact, the LlamaIndex team used Streamlit to prototype and run experiments early in their journey, including their initial proofs of concept!
In this post, we'll show you how to build a chatbot using LlamaIndex to augment GPT-3.5 with Streamlit documentation in four simple steps:
- Configure app secrets
- Install dependencies
- Build the app
- Deploy the app!
What is LlamaIndex?
Before we get started, let's walk through the basics of LlamaIndex.
Behind the scenes, LlamaIndex enriches your model with custom data sources through Retrieval Augmented Generation (RAG).
Overly simplified, this process generally consists of two stages:
- An indexing stage. LlamaIndex prepares the knowledge base by ingesting data and converting it into Documents. It parses metadata from those documents (text, relationships, and so on) into nodes and creates queryable indices from these chunks into the Knowledge Base.
- A querying stage. Relevant context is retrieved from the knowledge base to assist the model in responding to queries. The querying stage ensures the model can access data not included in its original training data.
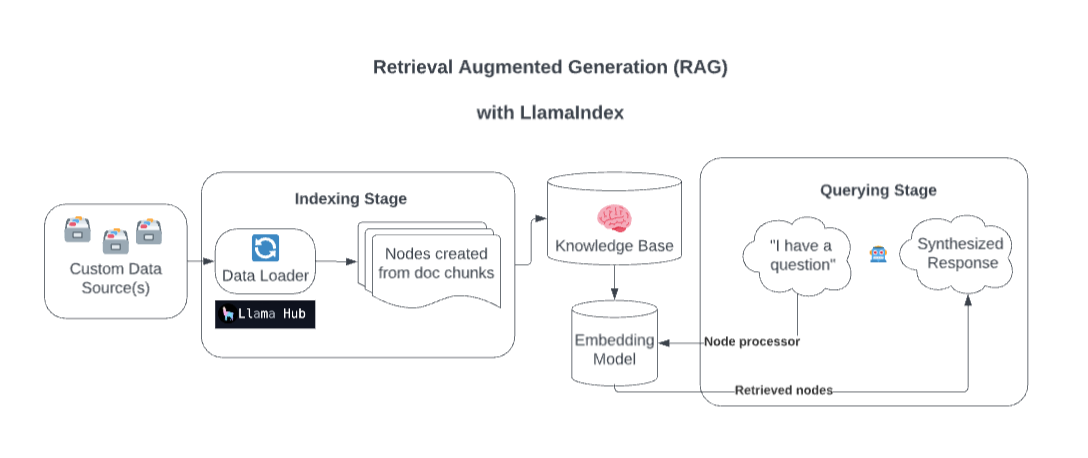
No matter what your LLM data stack looks like, LlamaIndex and LlamaHub likely already have an integration, and new integrations are added daily. Integrations with LLM providers, vector stores, data loaders, evaluation providers, and agent tools are already built.
LlamaIndex's Chat Engines pair nicely with Streamlit's chat elements, making building a contextually relevant chatbot fast and easy.
Let's unpack how to build one.
How to build a custom chatbot using LlamaIndex
In 43 lines of code, this app will:
- Use LlamaIndex to load and index data. Specifically, we're using the markdown files that make up Streamlit's documentation (you can sub in your data if you want).
- Create a chat UI with Streamlit's
st.chat_inputandst.chat_messagemethods - Store and update the chatbot's message history using the session state
- Augment GPT-3.5 with the loaded, indexed data through LlamaIndex's chat engine interface so that the model provides relevant responses based on Streamlit's recent documentation
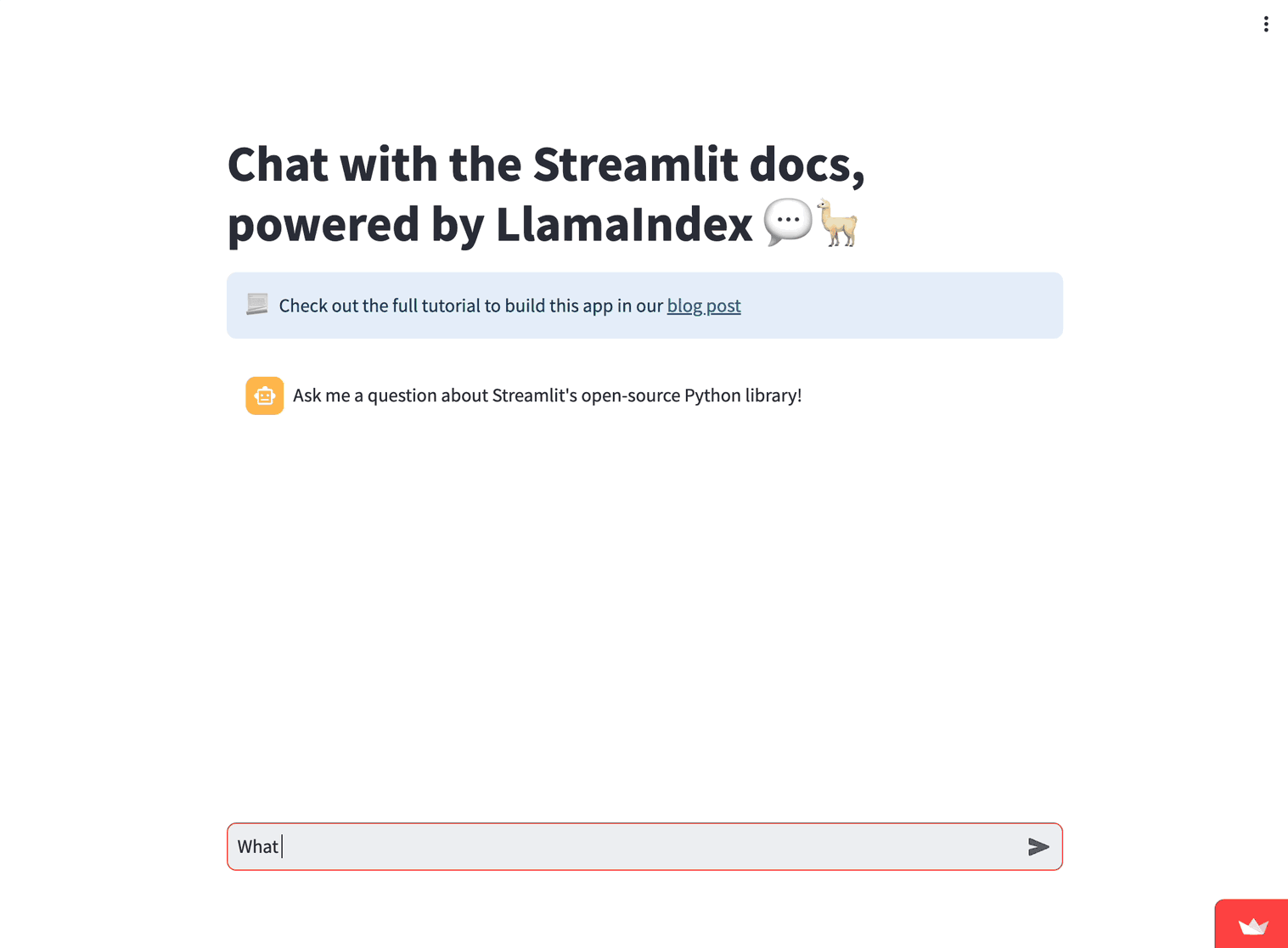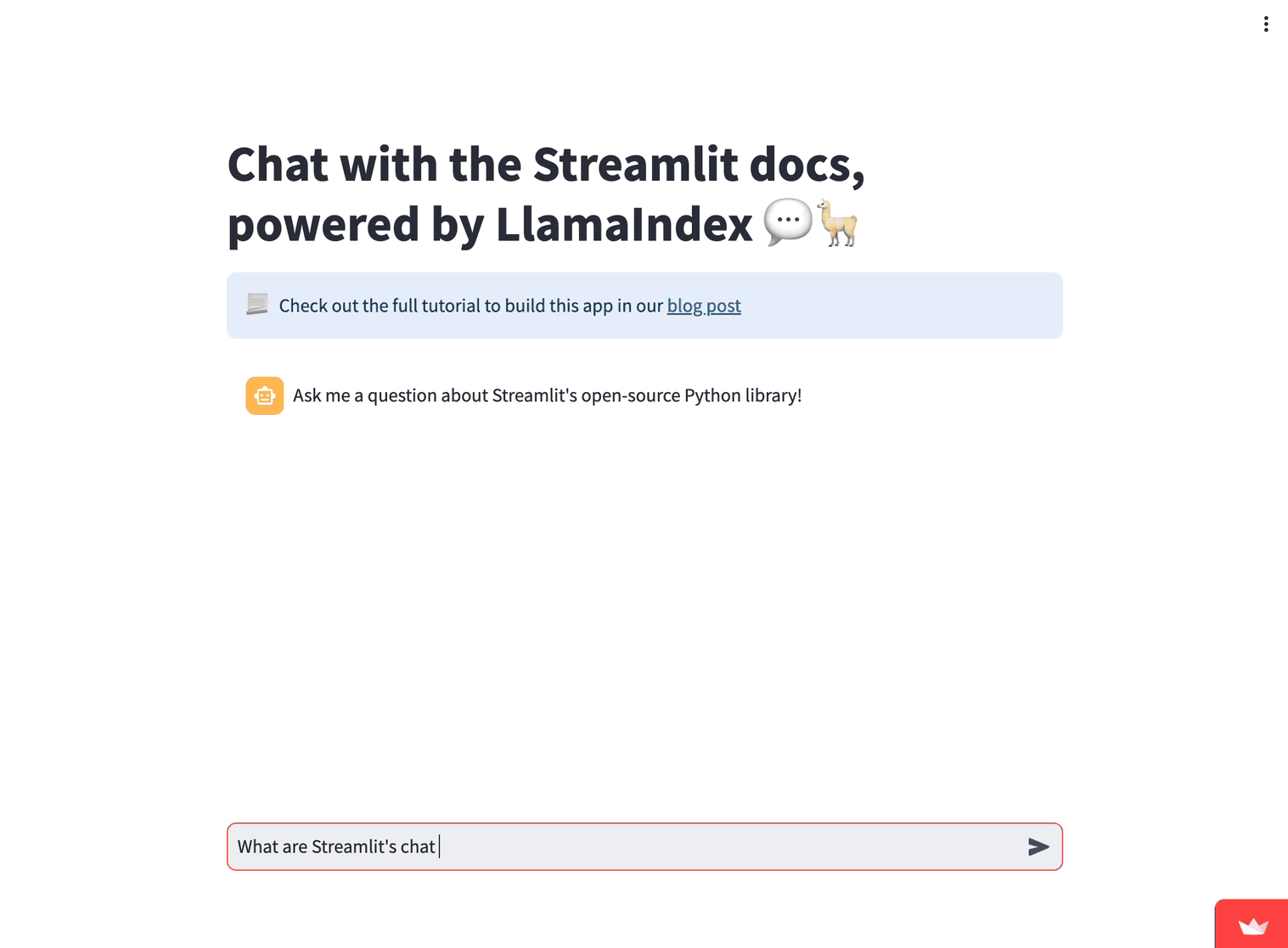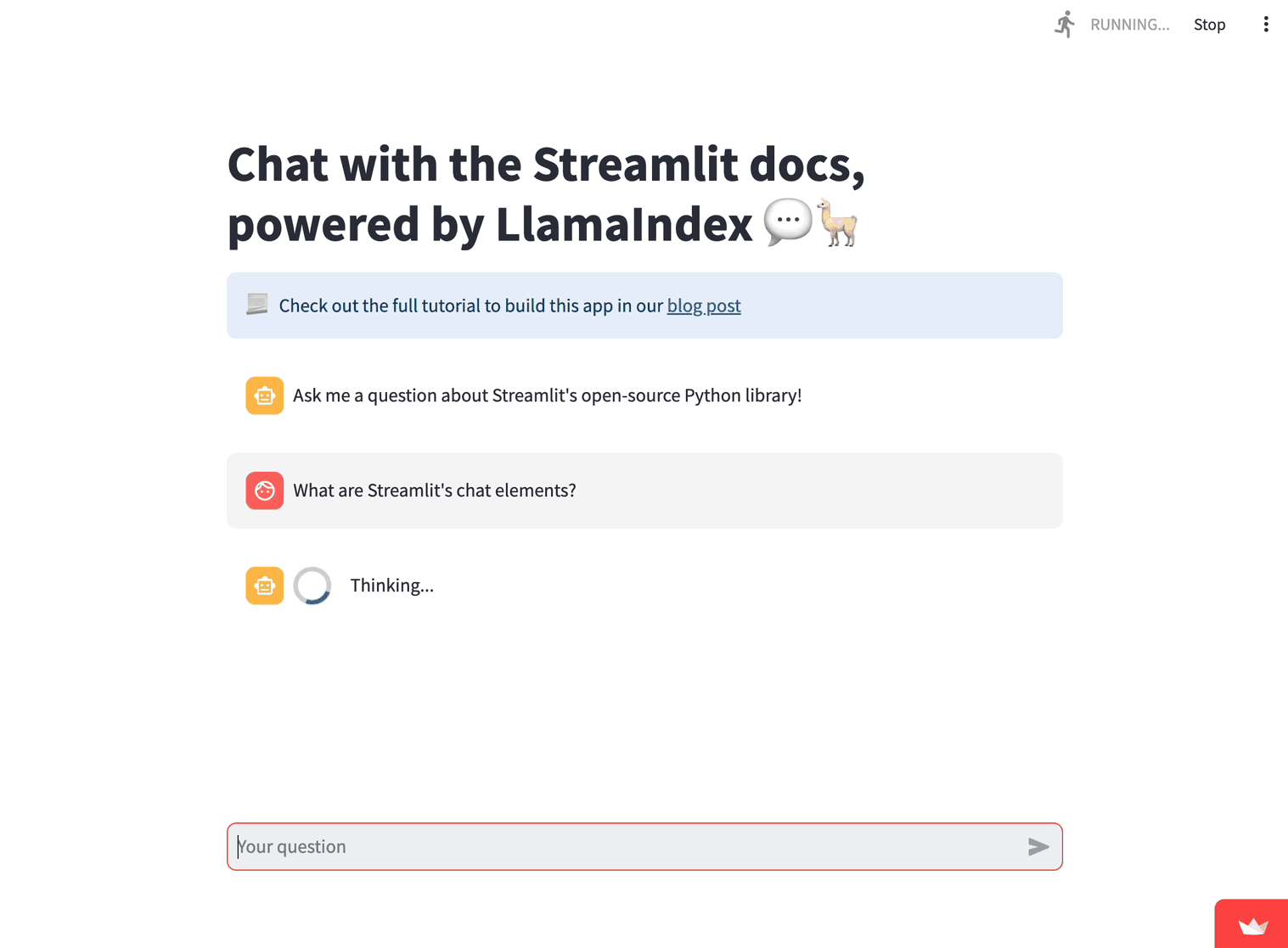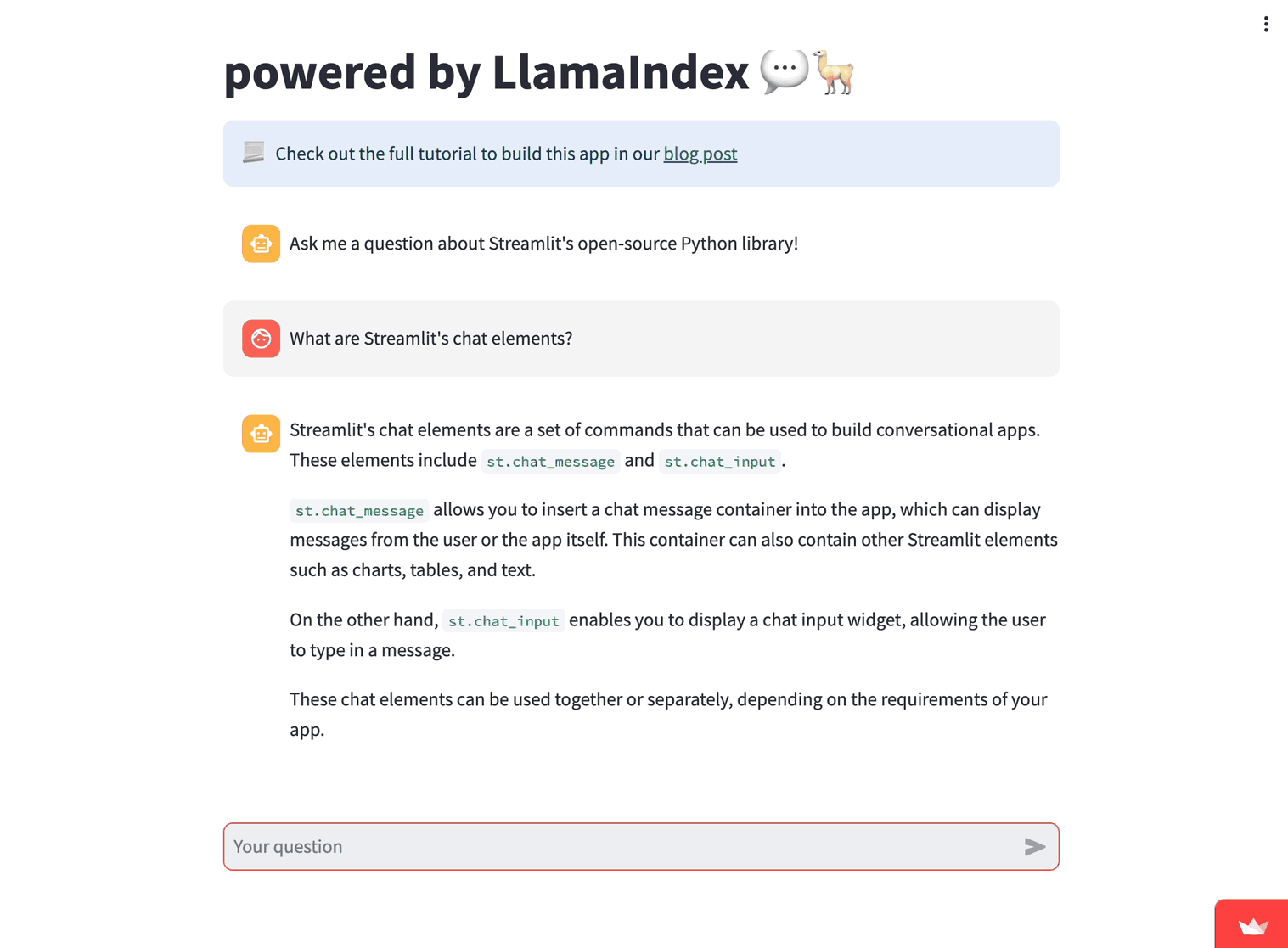
Try the app for yourself:
1. Configure app secrets
This app will use GPT-3.5, so you'll also need an OpenAI API key. Follow our instructions here if you don't already have one.
Create a secrets.toml file with the following contents.
- If you're using Git, be sure to add the name of this file to your
.gitignoreso you don't accidentally expose your API key. - If you plan to deploy this app on Streamlit Community Cloud, the following contents should be added to your app's secrets via the Community Cloud modal.
openai_key = "<your OpenAI API key here>"
2. Install dependencies
2.1. Local development
If you're working on your local machine, install dependencies using pip:
pip install streamlit openai llama-index nltk
2.2. Cloud development
If you're planning to deploy this app on Streamlit Community Cloud, create a requirements.txt file with the following contents:
streamlit
openai
llama-index
nltk
3. Build the app
The full app is only 43 lines of code. Let's break down each section.
3.1. Import libraries
Required Python libraries for this app: streamlit, llama_index, openai, and nltk.
import streamlit as st
from llama_index import VectorStoreIndex, ServiceContext, Document
from llama_index.llms import OpenAI
import openai
from llama_index import SimpleDirectoryReader
3.2. Initialize message history
- Set your OpenAI API key from the app's secrets.
- Add a heading for your app.
- Use session state to keep track of your chatbot's message history.
- Initialize the value of
st.session_state.messagesto include the chatbot's starting message, such as, "Ask me a question about Streamlit's open-source Python library!"
openai.api_key = st.secrets.openai_key
st.header("Chat with the Streamlit docs 💬 📚")
if "messages" not in st.session_state.keys(): # Initialize the chat message history
st.session_state.messages = [
{"role": "assistant", "content": "Ask me a question about Streamlit's open-source Python library!"}
]
3.3. Load and index data
Store your Knowledge Base files in a folder called data within the app. But before you begin…
Download the markdown files for Streamlit's documentation from the data demo app's GitHub repository folder. Add the data folder to the root level of your app. Alternatively, add your data.
Define a function called load_data(), which will:
- Use LlamaIndex’s
SimpleDirectoryReaderto passLlamaIndex's the folder where you’ve stored your data (in this case, it’s calleddataand sits at the base level of your repository). SimpleDirectoryReaderwill select the appropriate file reader based on the extensions of the files in that directory (.mdfiles for this example) and will load all files recursively from that directory when we callreader.load_data().- Construct an instance of LlamaIndex’s
ServiceContext, whichLlamaIndex'stion of resources used during a RAG pipeline's indexing and querying stages. ServiceContextallows us to adjust settings such as the LLM and embedding model used.- Use LlamaIndex’s
VectorStoreIndexto creaLlamaIndex'sorySimpleVectorStore, which will structure your data in a way that helps your model quickly retrieve context from your data. Learn more about LlamaIndex’sIndiceshere. This function returns theVectorStoreIndexobject.
This function is wrapped in Streamlit’s caching decorator st.cache_resource to minimize the number of times the data is loaded and indexed.
Finally, call the load_data function, designating its returned VectorStoreIndex object to be called index.
@st.cache_resource(show_spinner=False)
def load_data():
with st.spinner(text="Loading and indexing the Streamlit docs – hang tight! This should take 1-2 minutes."):
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
docs = reader.load_data()
service_context = ServiceContext.from_defaults(llm=OpenAI(model="gpt-3.5-turbo", temperature=0.5, system_prompt="You are an expert on the Streamlit Python library and your job is to answer technical questions. Assume that all questions are related to the Streamlit Python library. Keep your answers technical and based on facts – do not hallucinate features."))
index = VectorStoreIndex.from_documents(docs, service_context=service_context)
return index
index = load_data()
3.4. Create the chat engine
LlamaIndex offers several different modes of chat engines. It can be helpful to test each mode with questions specific to your knowledge base and use case, comparing the response generated by the model in each mode.
LlamaIndex has four different chat engines:
- Condense question engine: Always queries the knowledge base. Can have trouble with meta questions like “What did I previously ask you?”
- Context chat engin": Always queries the knowledge base and uses retrieved text from the knowledge base as context for following queries. The retrieved context from previous queries can take up much of the available context for the current query.
- ReAct agent: Chooses whether to query the knowledge base or not. Its performance is more dependent on the quality of the LLM. You may need to coerce the chat engine to correctly choose whether to query the knowledge base.
- OpenAI agent: Chooses whether to query the knowledge base or not—similar to ReAct agent mode, but uses OpenAI’s built-in fuOpenAI'salling capabilities.
This example uses the condense question mode because it always queries the knowledge base (files from the Streamlit docs) when generating a response. This mode is optimal because you want the model to keep its answers specific to the features mentioned in Streamlit’s documentation.
chat_engine = index.as_chat_engine(chat_mode="condense_question", verbose=True)
3.5. Prompt for user input and display message history
- Use Streamlit’s
st.chat_inputfeature Streamlit'she user to enter a question. - Once the user has entered input, add that input to the message history by appending it
st.session_state.messages. - Show the message history of the chatbot by iterating through the content associated with the “messages” key in the session state and displaying each message using
st.chat_message.
if prompt := st.chat_input("Your question"): # Prompt for user input and save to chat history
st.session_state.messages.append({"role": "user", "content": prompt})
for message in st.session_state.messages: # Display the prior chat messages
with st.chat_message(message["role"]):
st.write(message["content"])
3.6. Pass query to chat engine and display response
If the last message in the message history is not from the chatbot, pass the message content to the chat engine via chat_engine.chat(), write the response to the UI using st.write and st.chat_message, and add the chat engine’s response to the message history.
# If last message is not from assistant, generate a new response
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = chat_engine.chat(prompt)
st.write(response.response)
message = {"role": "assistant", "content": response.response}
st.session_state.messages.append(message) # Add response to message history
4. Deploy the app!
After building the app, deploy it on Streamlit Community Cloud:
- Create a GitHub repository.
- Navigate to Streamlit Community Cloud, click
New app, and pick the appropriate repository, branch, and file path. - Hit
Deploy.
LlamaIndex helps prevent hallucinations
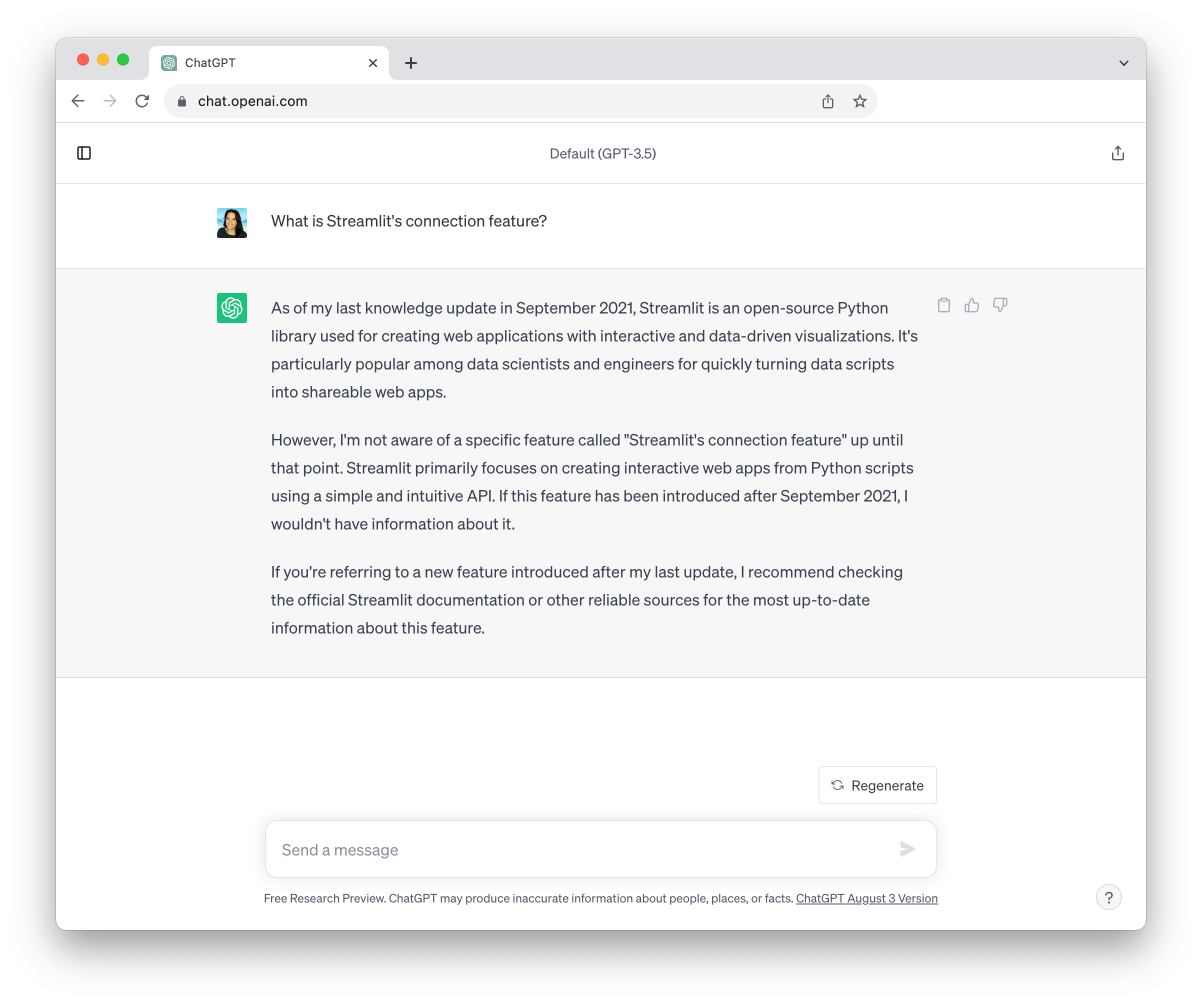
Now that you’ve built a Streamlit docs chatbot using up-to-date markdown files, how do these results compare the results to ChatGPT? GPT-3.5 and 4 have only been trained on data up to September 2021. They’re missing three years of new releases! Augmenting your LLM with LlamaIndex ensures higher accuracy of the response.
What is Streamlit’s experimental connection feature?
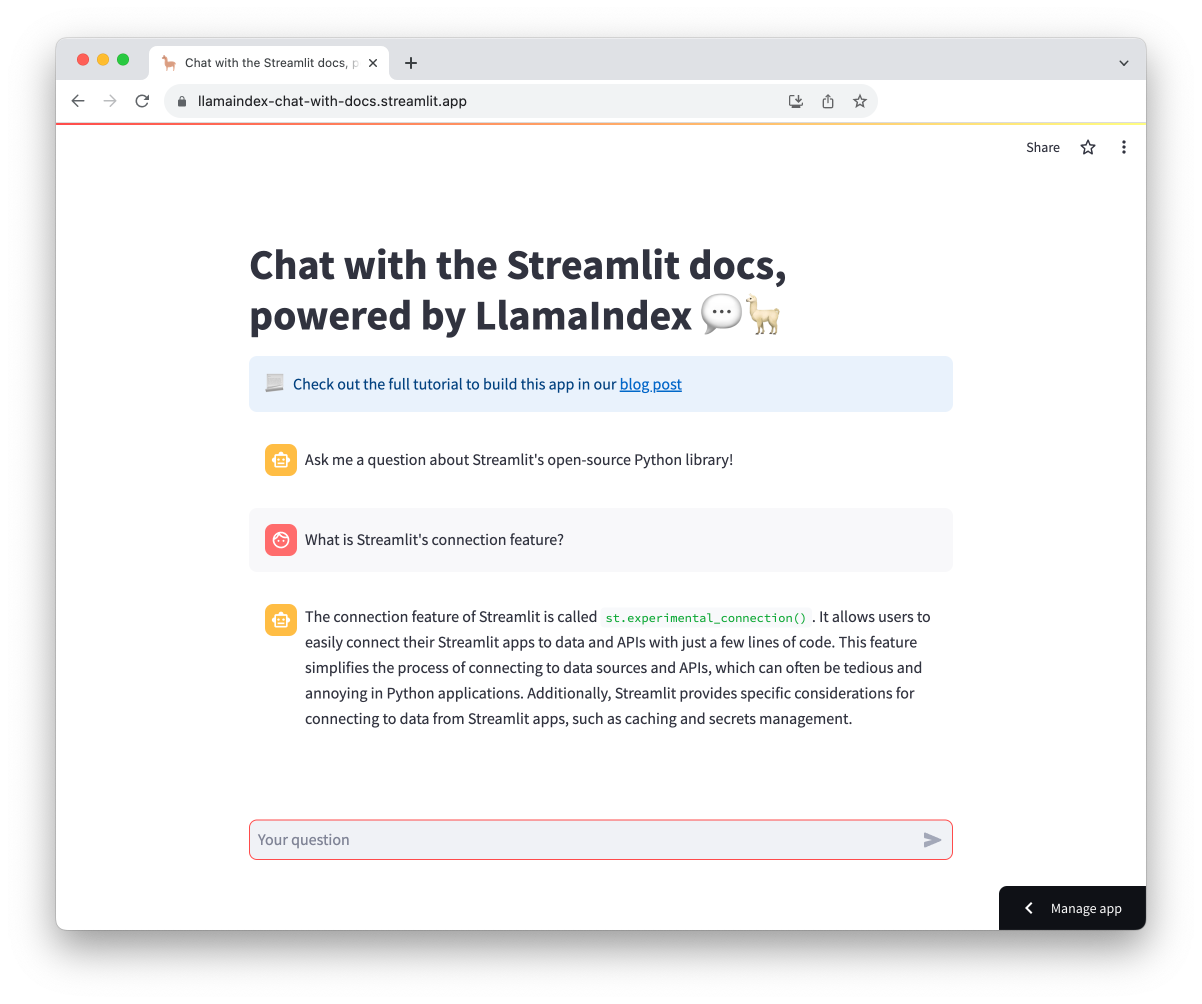


Wrapping up
You learned how the LlamaIndex framework can create RAG pipelines and supplement a model with your data.
You also built a chatbot app that uses LlamaIndex to augment GPT-3.5 in 43 lines of code. The Streamlit documentation can be substituted for any custom data source. The result is an app that yields far more accurate and up-to-date answers to questions about the Streamlit open-source Python library compared to ChatGPT or using GPT alone.
Check out our LLM gallery for inspiration to build even more LLM-powered apps, and share your questions in the comments.
Happy Streamlit-ing! 🎈




Comments
Continue the conversation in our forums →