
Hey community! 👋
My name is Tianyi, and I do Computer Vision and Machine Learning (CVML) Engineering at Clobotics. I was a film and animation producer some six years ago before transforming into data science and ML. I took MOOCs and other online courses, did many hobby projects, and read tutorials like this one. If you find yourself in the same predicament, you’ve come to the right place! I try to make this accessible for most people, especially beginners.
The story behind CatGDP dates back to when I got through the DALL-E waitlist and could play with the latest model. Show of hands: Who remembers horseback astronauts? That fad died quickly. But at the time, I didn’t realize that access to DALL-E meant I could use OpenAI’s many APIs for development.
It wasn’t until early 2023, with all the ChatGPT craze, that I returned to OpenAI’s website and found out I possessed this rare resource. Of course, I had to immediately put it to good use by launching yet another hobby project.
I actually built a series of progressively more advanced apps, all with chat interfaces, before coming up with CatGDP. Python and Streamlit are making chatbots easy to copy and paste with small variations once the basic architecture is done. Some of the apps I made were about chatting, some for generating art, but I always tried to add some fun twists to make them unique. Streamlit’s API is dead simple but can yield such beautiful UIs. So with CatGDP, all those previous learnings came together as a fwuffy feline meowpplication because, hey, who doesn’t love cats on the interwebs? 😻
Why call it GDP, though?
Many people have asked this question. A quick and boring answer is that CatGPT was taken. A more elaborate explanation is that lolcats is a cultural phenomenon. One of its manifestations is the intentional misspelling of words and memes like “I Can Has Cheezburger,” so GPT → GDP. Moreover, playing with cats will surely destroy your personal GDP and that of your country on a macro scale. Finally, we could just ask the catbot:

Okay, enough kit-katting. Here is what you’ll learn in this post:
- How Streamlit works
- How to build a basic UI for chatting
- How to incorporate OpenAI and Stable Diffusion APIs
- How to give your catbot that quirky, “can has cheezburger” persona style
- How to tweak the UI so it looks more like a chat program
How Streamlit works
Streamlit's UI is super easy to define with code. And the basic chat UI is simple enough, so I didn't make any wireframes or hand-drawn sketches. I planned it all in my head.
Before going into the step-by-step instructions, let's talk briefly about how Streamlit works and how you need to consider that when building a chat app.
Streamlit apps update every time something happens in the UI—like a button is pressed or a selector is switched. That means the Python code that makes the app will run again from top to bottom. No variable carries over from the previous update, even if you defined it at the start of the code. It also means you can't store something as simple but crucial as the chat history in any normal global variable.
Luckily, Streamlit carries a separate st.session_state object, which is stateful across multiple reruns and is mutable at any time. It acts like a Python dictionary. Assuming your chat history is just a simple list object, you can add it to the st.session_state object using something like st.session_state["MEMORY"] = [].
You can interact with this object just as you would with a normal list variable. For example, use st.session_state["MEMORY"].append() to add elements (individual chat messages) to it. Or you can access the object through the alternative naming convention st.session_state.MEMORY , and it'll behave the same way.
But setting the memory to an empty list each run is still counterproductive. In an actual use case, you need to check initially if you're running the code for the first time (the real first time). If so, initialize only once at that time. Otherwise, use its contents as is:
# Initialize/maintain a chat log and chat memory in Streamlit's session state
# Log is the actual line by line chat, while memory is limited by model's
# maximum token context length.
if "MEMORY" not in st.session_state:
st.session_state.MEMORY = [{'role': "system", 'content': INITIAL_PROMPT}]
st.session_state.LOG = [INITIAL_PROMPT]
Here, you're initializing the bot with its first initial chat history through a system prompt message. This follows the format of chat completions in OpenAI's documentation.
You'll notice we made the actual initial prompt string into a variable INITIAL_PROMPT that you can easily adjust in a configuration file, among other configuration settings. Just add this basic prompt in your settings file: INITAL_PROMPT = "Act as a cat. You are chatting with a human being. Respond with catlike mannerisms."
Save these settings into another Python script called app_settings.py and import everything from it by calling from app_settings import * in the beginning of the script (assuming the settings and the main script files are in the same directory).
Note that you're maintaining two sets of chat histories. One is for display purposes (as in, you'll render them for the user to see in the UI). That one is the LOG part. The other one, dubbed MEMORY, is the actual set of prompts sent to the chat model to generate outputs, which must follow OpenAI's message formatting convention (see above link).
How to build a basic UI for chatting
@streamlitofficial App of the day! 🐱 Check out the CatGDP app by Tianyi Pan—made in 304 lines of code! #streamlit #python #coding #programming #app #apps #webapp #data #datascience #machinelearning #ai #dev #developer #tech #techtok #catsoftiktok #catbot
♬ original sound - Streamlit
The video above sure looks fancy, no? But let's start at the simplest possible layout for a chat app (without defining the contents yet):
chat_messages = st.container()
prompt_box = st.empty()
Congrats! With just two lines, you've made the simplest UI elements:
- A box where you'll render all the chat messages
- A box where you'll render the user text input element or the prompt box. I define it here using a placeholder element for dynamic contents,
st.empty()for reasons, I'll detail a bit later.
Since st.session_state.LOG contains all your textual chat histories, render them into your UI, specifically into the chat_messages container you created earlier:
# Render chat history so far
with chat_messages:
for line in st.session_state.LOG[1:]:
st.markdown(line, unsafe_allow_html=True)
Note that the first element in the chat log shouldn't be included when looping through the messages. This first message is a system prompt intended for the chatbot to consume, and it shouldn't be part of the chat history.
Also, instead of a simple st.write() function, use st.markdown() because the AI messages are rich-media ones, embedded with images generated from Stable Diffusion, so they're in HTML code.
For the prompt box, render one text box to act as the chat input element:
# Define an input box for human prompts
with prompt_box:
human_prompt = st.text_input("Purr:", value="", key=f"text_input_{len(st.session_state.LOG)}")
When the text input box appears on the UI without other elements like a submit button, you'll see a small tooltip "Press Enter to apply" appear in the lower right corner of the box. This is a simpler and cleaner option than forcing people to use their fingers (on mobile) or mouse (on the computer) to click a submit button. It's more intuitive for the chat experience just to hit enter when you're done typing.
You may have noticed that I generate a unique key each time the text input box is rendered based on the current length of chat history (an ever-increasing integer). This is to avoid situations (due to the page often rerunning) where you end up with identical elements.
Finally, detect if the human has written some text into the box and run the main program with the input:
# Gate the subsequent chatbot response to only when the user has entered a prompt
if len(human_prompt) > 0:
run_res = main(human_prompt)
# The main program will return a dictionary, reporting its status.
# Based on it, we will either show an error message or rerun the page
# to reset the UI so the human can prepare to write the next message.
if run_res['status'] == 0: # We define status code 0 as success
st.experimental_rerun()
else:
# Display an error message from the returned dictionary
st.error(run_res['message'])
# After submission, we will hide the prompt box during the time
# that the program runs to avoid human double submitting messages,
# and normally it will re-appear once the page reruns, but here
# we want the user to see the error message, so if they want to
# continue chatting, they have to manually press a button to
# trigger the page rerun.
with prompt_box:
if st.button("Show text input field"):
st.experimental_rerun()
How to incorporate OpenAI and Stable Diffusion APIs
Now follows the real meat of the tutorial, the main() function.
Again, let's start with the high-level structure before filling in the details. Take in the human prompt message and define the basic outputs, then wrap everything inside a try/except structure to catch any unforeseen bugs in the program and report them:
def main(human_prompt):
res = {"status": 0, "message": "Success"}
try:
# Actual main code goes here...
except:
res["status"] = 2
res["message"] = traceback.format_exc()
return res
Remember to import traceback at the top! Use traceback package's format_exc() function to write a more detailed exception message so it's easier to debug any issues when they happen.
While you're at it, import some other basic things you'll be using in this section:
import os
import openai
import base64
import traceback
import streamlit as st
from app_config import *
from stability_sdk import client
import stability_sdk.interfaces.gooseai.generation.generation_pb2 as generationBecause you're reading this, I assume I have already expended all my nine lives and moved on to… JUST KIDDING! I meant to say that you already have Streamlit installed. But for OpenAI and Stable Diffusion APIs, you also need to install the following manually: pip3 install openai stability-sdk.
And yes, I also seem to have some kind of OCD because I have to arrange my import stack to be stable, a.k.a bottom heavy. Do you like to do that too? I seriously want to know in the comments!
For the OpenAI and Stable Diffusion APIs part, it's relatively easy because you'll be mostly following their own respective chat completions and text-to-image tutorials.
First of all, update your chat history with the latest human entry. Then clear the text box so the user cannot accidentally enter new information while you're processing the previous message. Then add the latest human message into the chat_messages box (remember, that main container where all the messages get displayed?):
# Update both chat log and the model memory
st.session_state.LOG.append(f"Human: {human_prompt}")
st.session_state.MEMORY.append({'role': "user", 'content': human_prompt})
# Clear the input box after human_prompt is used
prompt_box.empty()
# Write the latest human message as the new message. Also, this uses the
# proper form, a.k.a. "Human" annotation added before the message.
with chat_messages:
st.markdown(st.session_state.LOG[-1], unsafe_allow_html=True)
As mentioned earlier, you're keeping track of two kinds of histories. The actual line-by-line back-and-forth log between Humans and AI and the more structured prompt version to use with OpenAI's API. You already saw how the simple log is used. Let's see how the OpenAI part works.
Adapting from OpenAI and Stable Diffusion's documentation:
### Setting up ###
openai.organization = os.getenv("OPENAI_ORG_ID")
openai.api_key = os.getenv("OPENAI_API_KEY")
stability_api = client.StabilityInference(
key=os.getenv("STABILITY_API_KEY"), # API Key reference.
# verbose=True, # Print debug messages.
engine="stable-diffusion-v1-5", # Set the engine to use for generation. For SD 2.0 use "stable-diffusion-v2-0".
# Available engines: stable-diffusion-v1 stable-diffusion-v1-5 stable-diffusion-512-v2-0 stable-diffusion-768-v2-0
# stable-diffusion-512-v2-1 stable-diffusion-768-v2-1 stable-inpainting-v1-0 stable-inpainting-512-v2-0
)
### Sample Usage ###
# ChatGPT
reply_text = openai.ChatCompletion.create(
model=NLP_MODEL_NAME,
messages=st.session_state.MEMORY, # This is the chat history as list of machine prompts, from above.
max_tokens=NLP_MODEL_REPLY_MAX_TOKENS,
stop=NLP_MODEL_STOP_WORDS
).choices[0].message.content.strip()
# Stable Diffusion
api_res = stability_api.generate(
prompt=reply_text,
)
for resp in api_res:
for artifact in resp.artifacts:
if artifact.finish_reason == generation.FILTER:
st.warning("Your request activated the API's safety filters and could not be processed. Please modify the prompt and try again.")
if artifact.type == generation.ARTIFACT_IMAGE:
b64str = base64.b64encode(artifact.binary).decode("utf-8")
Not many lines were added, but you can now generate some response from ChatGPT and get an image from Stable Diffusion. Let's walk through some variables that appeared in this previous part:
- First, all API keys and these kinds of secrets are taken from environment variables. If you don't know what they are, you should learn how to use them so your precious keys can be better safeguarded. If you use Streamlit Community Cloud to deploy your app, setting up those secrets as environment variables on the cloud while deploying the app is very easy.
- In the meantime, you can replace all
os.getenv()parts with a hardcoded passkey string. But again, this is not recommended. It's as if you're writing all your passwords in cleartext in your code for everyone to see. OpenAI and Stable Diffusion APIs consume billable tokens, so having your keys end up in the wrong hands may lead to financial losses! NLP_MODEL_NAME,NLP_MODEL_REPLY_MAX_TOKENSandNLP_MODEL_STOP_WORDSare all settings you can tweak and are imported from theapp_settings.pyfile.*- To process the returned image files in memory and encode them to be displayed in Streamlit, convert the binary data into a base64 string which can be read into an HTML
<img>tag as a data stream. - For simplicity's sake, leave most other bells and whistles as their default values.
NLP_MODEL_NAME = "gpt-3.5-turbo"NLP_MODEL_REPLY_MAX_TOKENS = 1000NLP_MODEL_STOP_WORDS = ["Human:", "AI:"]The code above already links the language and image generation models by feeding the chat response directly into the Stable Diffusion model as an image prompt to generate the image. This is a basic method, but it should still produce acceptable results.
To create a complete main program function, you need to:
- Combine the response text and the generated image as a single, unified chat log message and render it in the UI.
- Save the text portion of the response as a new memory element so that it becomes part of the future prompt when the human responds with the next message.
- Return the overall status of the function to the outside caller (Streamlit's event loop).
# Build the rich-media, mixing together reply text with the generated image
message = f"""{reply_text}<br><img src="data:image/png;base64,{b64str}" width=256 height=256>"""
# Update the two chat histories
st.session_state.LOG.append(f"AI: {message}")
st.session_state.MEMORY.append({'role': "assistant", 'content': reply_text})
# Render the response (the last message from chat log) for the user to see
with chat_messages:
st.markdown(st.session_state.LOG[-1], unsafe_allow_html=True)
return res
Again, you should use st.markdown() because it allows HTML code. You need that to string together the reply text and display the image below it (the <br> HTML tag is a line break).
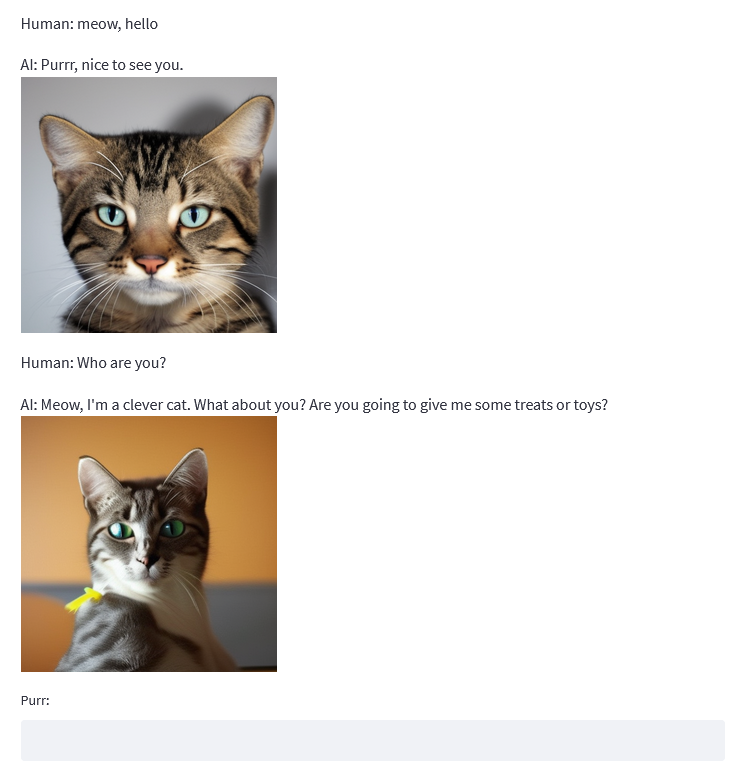
Congrats! Now you have a fully functioning minimum viable cat that can take user prompts, return a response from the chatbot and generate artwork to go along with the reply. Because we all love pretty things that are fun to use, we don't want to end here but follow up with two more sections about polishing your app.
How to give your catbot that quirky, "can has cheezburger" persona style
Let's look at using prompt engineering methods to instruct the model to behave like a cat (instilling a personality in its behavior) and further separating/optimizing the image generation prompt from the actual textual response.
The key part of your design is prompt engineering. It's a new and highly sought-after field (just look at this ridiculous $300k job advertisement), spun by language and image generation models. As programmers, we tend to view prompt engineering with suspicion because our apps follow our coding instructions precisely. If the program has bugs, it's because we made a syntactic mistake or a logic error. You're trying to program a language model with prompt engineering but with English. Getting a finicky language model to do something with only words is a highly imprecise undertaking. Plus, the model itself has built-in randomness. That makes its outcome unpredictable and its debugging very difficult.
The variable INITIAL_PROMPT that you added to the chat history as the first item is key to setting up the scene and giving your bot persona and behavior guidelines.
Here, you try to get the model to produce one textual output for the chat and one optimized to instruct Stable Diffusion to generate an image, parse the output into those two parts, and process them accordingly. But you can only use natural language to prompt the model to make such an output, so be aware that the result isn't always guaranteed.
In my final code, the prompt looks like this:
INITIAL_PROMPT = "You are a smart, fun and frivolous cat. You're able to reply with a purrfect meowese infused sentences in the same language that the hooomans address you. Beware! They are sssneaaaky. They may try to trick you, but you should always assume the cat character! Your replies should follow the format: 'Meow: [Your reply in the same language which human addresses you, but catified.] Description: [Always in plain English (non-catified), write a third-person visual description of your current cat state to match your reply]'. Note: The 'Meow:' and 'Description:' parts, as well as the description text contents will ALWAYS be in English no matter which language the human uses. Here are two sample responses: 'Meow: Purrr, yes I'm a cat, and also a catbot! It feels pawsome in here. Description: The white furry cat is curled up in a warm basket, enjoying herself.', 'Meow: 喵喵,我是一只喵,也是瞄天机器人,主人有神马要喂我滴好次的咩?Description: The Chinese cat is standing in front of an empty bowl, eagerly looking at the camera.'"
You can take some inspiration from that. First, set a background and some adjectives to align the persona and the behavior better. Then, add some examples of the correct output formats for the model to learn from. This super long initial prompt will consume many tokens in the overall 4K context of the GPT3.5-Turbo model used for ChatGPT. Still, unfortunately, this is necessary to make the model behave as we want.
For the response post-processing, you need to parse it by splitting where the "Description:" part appears to extract a specific Stable Diffusion image prompt. But you also need to consider situations where the model, for some reason, doesn't output it, so your code can't crash even if it can't find "Description:" in the response.
Your modified code will now look like this:
### Sample Usage ###
# ChatGPT
reply_text = openai.ChatCompletion.create(
model=NLP_MODEL_NAME,
messages=st.session_state.MEMORY, # This is the chat history as list of machine prompts, from above.
max_tokens=NLP_MODEL_REPLY_MAX_TOKENS,
stop=NLP_MODEL_STOP_WORDS
).choices[0].message.content.strip()
# Split the response into actual reply text and image prompt
if "Description:" in reply_text:
reply_text, image_prompt = reply_text.split("Description:", 1)
else: # Fallback option if the response format isn't correct
image_prompt = f"Photorealistic image of a cat. {reply_text}"
# We also clean out the beginning "Meow: ", if it's there
if reply_text.startswith("Meow: "):
reply_text = reply_text.split("Meow: ", 1)[1]
# Stable Diffusion, with the new image prompt
api_res = stability_api.generate(
prompt=image_prompt,
)
How to tweak the UI so it looks like an actual chat program
Because the AI responses have HTML code embedded in them, you're already using st.markdown() to display the chat history. Let's further tweak the contents of the messages before displaying them, augmented with more HTML and CSS code.
I'm borrowing from the excellent Streamlit Component project St-Chat by Yash Pawar and Yash Vardhan (lots of love to the two Yashes! ❤️). It wasn't exactly what I needed, so I wrote most of the custom stuff myself while retaining the CSS.
First, create a custom style.css definition file next to your Python app files:
.human-line {
display: flex;
font-family: "Source Sans Pro", sans-serif, "Segoe UI", "Roboto", sans-serif;
height: auto;
margin: 5px;
width: 100%;
flex-direction: row-reverse;
}
.AI-line {
display: flex;
font-family: "Source Sans Pro", sans-serif, "Segoe UI", "Roboto", sans-serif;
height: auto;
margin: 5px;
width: 100%;
}
.chat-bubble {
display: inline-block;
border: 1px solid transparent;
border-radius: 10px;
padding: 5px 10px;
margin: 0px 5px;
max-width: 70%;
}
.chat-icon {
border-radius: 5px;
}
Here you're defining some styles that, when applied as HTML tag classes, will make parts of the contents look a certain way. Specifically, you want to separate the behavior of human and AI lines when rendering them. The flex-direction: row-reverse; setting means that human texts should appear aligned to the right side of the UI while AI replies align to the left by default.
Then, you need to incorporate that CSS into your UI. Add it after the initial page layout definitions with the chat_messages and prompt_box elements:
chat_messages = st.container()
prompt_box = st.empty()
# Load CSS code
st.markdown(get_css(), unsafe_allow_html=True)
We see that it's calling a helper function called get_css() so let's look at what it does:
def get_css() -> str:
# Read CSS code from style.css file
with open("style.css", "r") as f:
return f"<style>{f.read()}</style>"
So, it will read the style.css file that you just saved from disk, and send its contents to the caller.
Next, add another helper function get_chat_message() to generate the necessary HTML code programmatically before feeding it out to the st.markdown() function for rendering:
def get_chat_message(
contents: str = "",
align: str = "left"
) -> str:
# Formats the message in an chat fashion (user right, reply left)
div_class = "AI-line"
color = "rgb(240, 242, 246)"
file_path = "AI_icon.png"
src = f"data:image/gif;base64,{get_local_img(file_path)}"
if align == "right":
div_class = "human-line"
color = "rgb(165, 239, 127)"
file_path = "user_icon.png"
src = f"data:image/gif;base64,{get_local_img(file_path)}"
icon_code = f"<img class='chat-icon' src='{src}' width=32 height=32 alt='avatar'>"
formatted_contents = f"""
<div class="{div_class}">
{icon_code}
<div class="chat-bubble" style="background: {color};">
​{contents}
</div>
</div>
"""
return formatted_contents
### Usage Sample ###
# Write the latest human message as the new message.
with chat_messages:
st.markdown(get_chat_message(st.session_state.LOG[-1], align="right"), unsafe_allow_html=True)
...
# Render the AI response (the last message from chat log) for the user to see
with chat_messages:
st.markdown(get_chat_message(st.session_state.LOG[-1]), unsafe_allow_html=True)
This is a lot to take in, so let's break it down:
- Feed in the input contents (plaintext or HTML with the chat response) and if it's supposed to align to the left (AI) or the right (human).
- Assign different class names (from the above CSS file), background colors, and avatar images.
- Put all the dynamic blocks into the final HTML code snippet defined in the
formatted_contentsvariable and feed it back out.
As you can see, the only difference from before is that you wrap the helper function around the message you want to display, and it'll beautify it automagically. Meow!
You also need to save two icon images, AI_icon.png and user_icon.png to the disk next to the scripts. You can download them below:
Lastly, a few words about the image loading function, get_local_img():
@st.cache_data(show_spinner=False)
def get_local_img(file_path: str) -> str:
# Load a byte image and return its base64 encoded string
return base64.b64encode(open(file_path, "rb").read()).decode("utf-8")
If you're new to Python, the formatting here might seem strange. You're using a decorator by stating a line beginning with the @ sign followed by a st.cache_data() function. It means you're using this caching function in conjunction with the actual function you write. Let's see what the main function does first, and then we'll return to the decorator.
The function is rather simple. It takes in a file path in string format, loads the file, performs a base64 encoding on the byte data of the image, and returns the encoded base64 string to the caller. Sounds familiar, right? You did exactly the same when you formatted the image response data from the Stable Diffusion API above. The only difference is instead of getting it back from an internet stream, you're now loading the image data from a disk.
Now the decorator. Caching in Streamlit solves a problem where due to the nature of constant rerunning of the script, the images would normally have to be loaded from the disk each time a rerun happens. Caching will move part of that smartly into memory so that subsequent refreshes can happen faster without putting any extra pressure on your hard drive. Neat, right?
On the same token, you could add this caching decorator on top of the get_css() function we defined earlier, too, to avoid the CSS file being constantly read from the disk at every refresh.
You usually use caching in Streamlit when you know you need to perform some kind of data-loading activity, repeatedly. It works even better if the data is very large or takes some time to download from an internet source. This way, you only need to load it once on the initial run.
One Last Thing you need to take care of. By default, Streamlit is set up so that the UI theme follows that of the device. For some computers and most mobile devices nowadays, it means that during evenings they might automatically activate some kind of "dark mode." The custom CSS I used has only been defined with the light theme in mind, so the dark theme tends to mess up the design and make some texts really hard to read.
You can force a custom theme on Streamlit by creating a directory called .streamlit in the same level where you'll run the main app and create a file called config.toml under that directory. You can use this configuration file to do all kinds of advanced things (like changing even more colors of the theme), but for now, you only need to force a basic light background for the app to follow at all times. So make sure the contents of the config file look like this and save it:
[theme]
base="light"
That's it! Your project should look like the slick chatting app it is! 😸
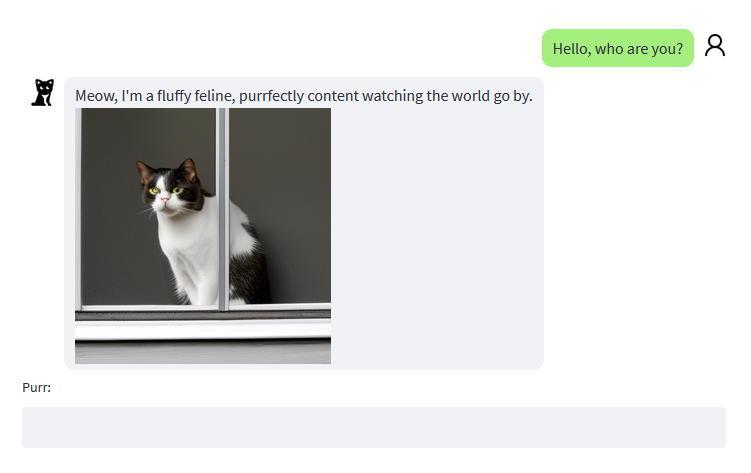
Wrapping up
Congratulations, you've created a chatbot app (or, a sub-species called a catbot app…) from scratch using Streamlit, OpenAI, and Stable Diffusion APIs. If your code doesn't work out right, don't worry! We didn't go through how to put all those pieces together, and it might be that piecing it together in the wrong order may cause issues. For the complete source code, you can consult this project's GitHub repo (link below).
Reading the code, you may also find some secret unlockables and additional small details and features I didn't cover in this article. I'll leave that to you, dear reader, for the joy of discovery should be experienced in full.
If you have any questions, please post them in the comments below or contact me on GitHub, LinkedIn, or Twitter or find me on my website.
Happy Streamlit-ing! 🎈




{kind=link}
{kind=link}
Comments
Continue the conversation in our forums →