
Hey, community! 👋
My name is Mala Deep Upadhaya, and I'm an independent consultant specializing in data visualization and analysis projects. I also teach people how to analyze data and share insights in a more accessible manner. I built PureHuB to give access to profiles, groundbreaking work, and cutting-edge research produced by the extraordinary minds of Coventry University.
In this post, I'll walk you through the process of building it step-by-step:
- Scrapper setup
- Preprocessing
- Building the front end
But first…
Why PureHuB?
Humans have always been driven by their inherent curiosity to seek out information. This is one of the motivations behind developing search engines [1]. From WebCrawler, created by Brian Pinkerton, a computer science student at the University of Washington, to the web3.0-based search engines like Presearch, to AltaVista, Lycos, Yahoo, HotBot, and Google in 1988, many search engines have grown rapidly [2]. There are 29 generic search engines and numerous domain-specific ones [3].
Unlike general search engines that index and search the entire web for relevant results, vertical search engines focus on specific data sets. This makes them faster and more relevant when users look for specific information. Google Books, Google News, Google Flights, and Google Finance are examples of vertical searches within the Google search engine. These search engines were created to ease the burden of searching for specialized information or topics.
App overview
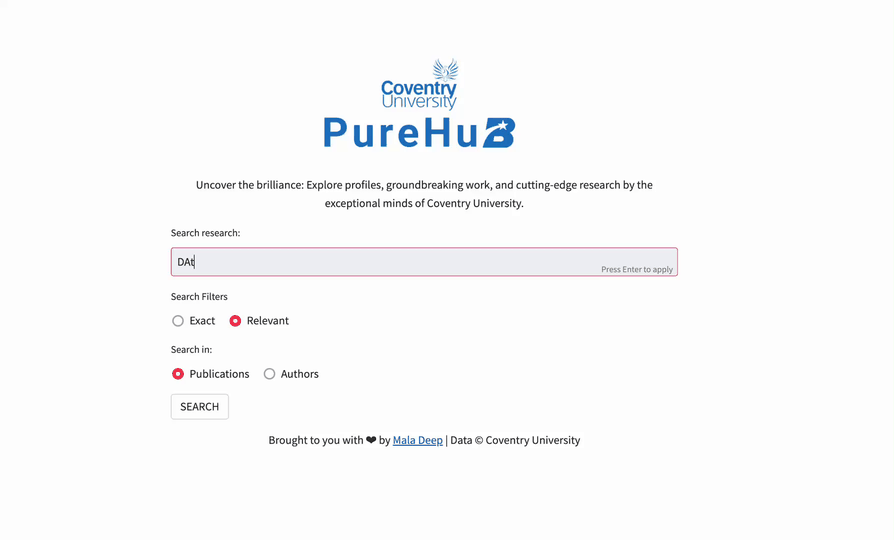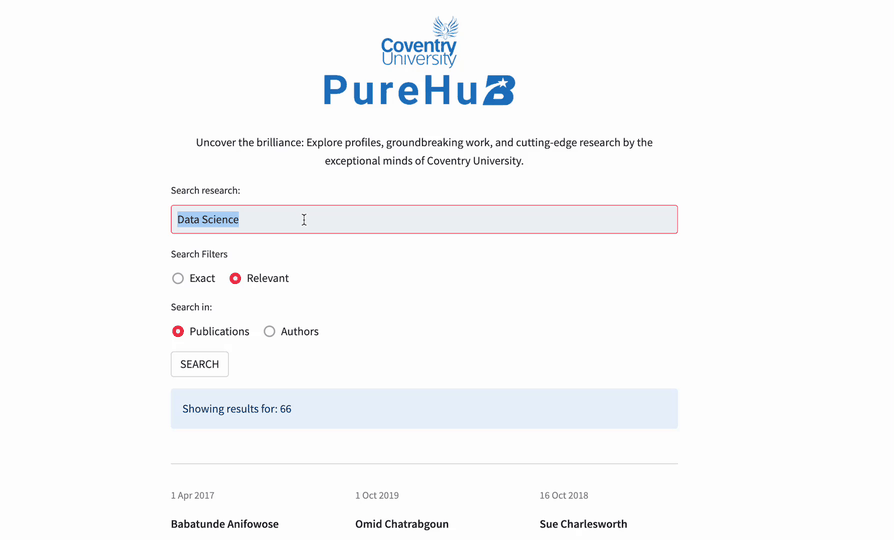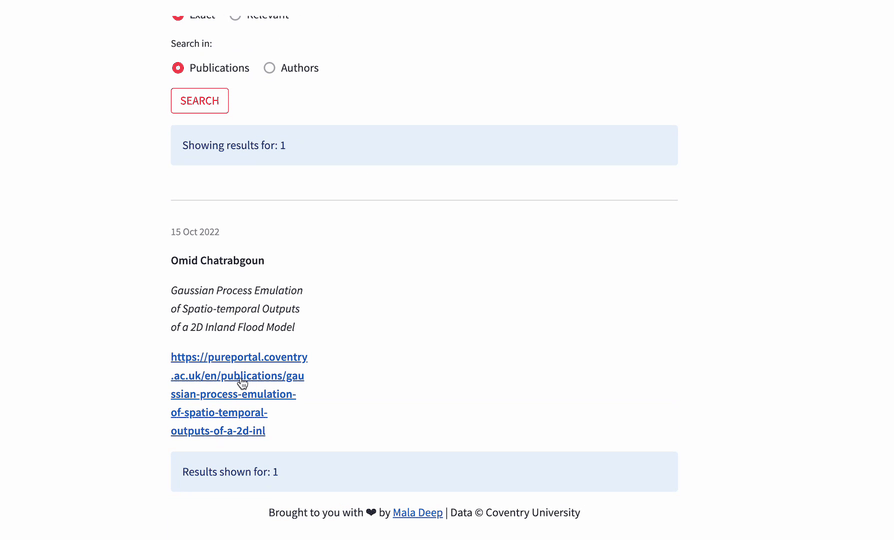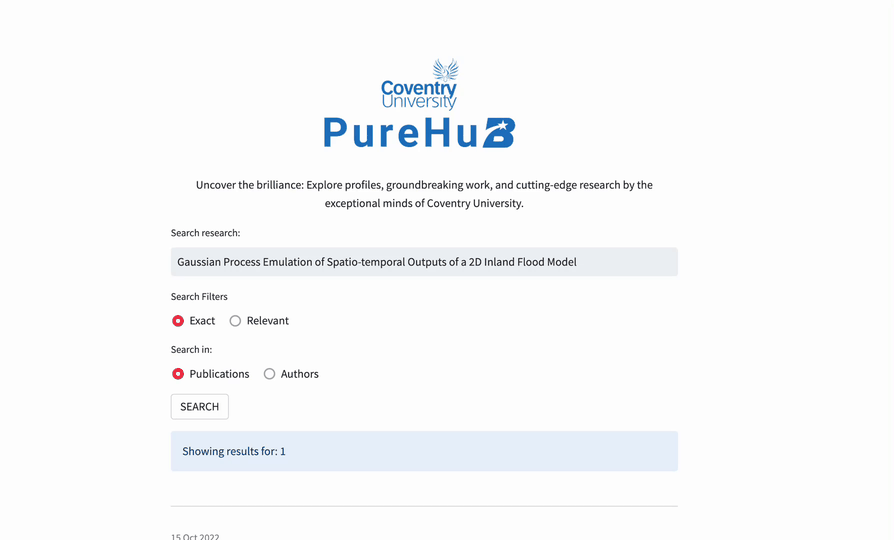
Here is how the app works.
To search for research, enter your query in the "Search research" field. Then, choose an operator: "Exact" or "Relevant." Select "Exact" for an exact match of your query or "Relevant" for the relevance and ranking of the search results. You can also choose the search type between "Publications" and "Authors."
Next, click "SEARCH." The app will give you the most relevant results:
1. Scrapper setup
For web scraping and automation, I used two popular Python libraries:
- BeautifulSoup for parsing the HTML of Pure Portal. It provides an easy and convenient way to extract data from web pages by navigating the HTML structure.
- Selenium for automating web browsers. It allows you to control a web browser programmatically and was used to perform various actions, such as clicking buttons and navigating between pages, without human intervention.
To account for website exploration through browsers, I incorporated the Chrome browser and used the ChromeDriver, a separate executable that bridges Selenium and the Chrome browser. It has better compatibility, debugging, and logging features during development. I also implemented a 1-second time delay.
Here is the code:
import os # Module for interacting with the operating system
import time # Module for time-related operations
import ujson # Module for working with JSON data
from random import randint # Module for generating random numbers
from typing import Dict, List, Any # Type hinting imports
import requests # Library for making HTTP requests
from bs4 import BeautifulSoup # Library for parsing HTML data
from selenium import webdriver # Library for browser automation
from selenium.common.exceptions import NoSuchElementException # Exception for missing elements
from webdriver_manager.chrome import ChromeDriverManager # Driver manager for Chrome (We are using Chromium based )
def initCrawlerScraper(seed,max_profiles=500):
# Initialize driver for Chrome
webOpt = webdriver.ChromeOptions()
webOpt.add_experimental_option('excludeSwitches', ['enable-logging'])
webOpt.add_argument('--ignore-certificate-errors')
webOpt.add_argument('--incognito')
webOpt.headless = True
driver = webdriver.Chrome(ChromeDriverManager().install(), options=webOpt)
driver.get(seed) # Start with the original link
links = [] # Array with pureportal profiles URL
pub_data = [] # To store publication information for each pureportal profile
nextLink = driver.find_element_by_css_selector(".nextLink").is_enabled() # Check if the next page link is enabled
print("Crawler has begun...")
while (nextLink):
page = driver.page_source
# XML parser to parse each URL
bs = BeautifulSoup(page, "lxml") # Parse the page source using BeautifulSoup
# Extracting exact URL by spliting string into list
for link in bs.findAll('a', class_='link person'):
url = str(link)[str(link).find('<https://pureportal.coventry.ac.uk/en/persons/'):].split('>"')
links.append(url[0])
# Click on Next button to visit next page
try:
if driver.find_element_by_css_selector(".nextLink"):
element = driver.find_element_by_css_selector(".nextLink")
driver.execute_script("arguments[0].click();", element)
else:
nextLink = False
except NoSuchElementException:
break
# Check if the maximum number of profiles is reached
if len(links) >= max_profiles:
break
print("Crawler has found ", len(links), " pureportal profiles")
write_authors(links, 'Authors_URL.txt') # Write the authors' URLs to a file
print("Scraping publication data for ", len(links), " pureportal profiles...")
count = 0
for link in links:
# Visit each link to get data
time.sleep(1)
driver.get(link)
try:
if driver.find_elements_by_css_selector(".portal_link.btn-primary.btn-large"):
element = driver.find_elements_by_css_selector(".portal_link.btn-primary.btn-large")
for a in element:
if "research output".lower() in a.text.lower():
driver.execute_script("arguments[0].click();", a)
driver.get(driver.current_url)
# Get name of Author
name = driver.find_element_by_css_selector("div[class='header person-details']>h1")
r = requests.get(driver.current_url)
# Parse all the data via BeautifulSoup
soup = BeautifulSoup(r.content, 'lxml')
# Extracting publication name, publication url, date and CU Authors
table = soup.find('ul', attrs={'class': 'list-results'})
if table != None:
for row in table.findAll('div', attrs={'class': 'result-container'}):
data = {}
data['name'] = row.h3.a.text
data['pub_url'] = row.h3.a['href']
date = row.find("span", class_="date")
rowitem = row.find_all(['div'])
span = row.find_all(['span'])
data['cu_author'] = name.text
data['date'] = date.text
print("Publication Name :", row.h3.a.text)
print("Publication URL :", row.h3.a['href'])
print("CU Author :", name.text)
print("Date :", date.text)
print("\\n")
pub_data.append(data)
else:
# Get name of Author
name = driver.find_element_by_css_selector("div[class='header person-details']>h1")
r = requests.get(link)
# Parse all the data via BeautifulSoup
soup = BeautifulSoup(r.content, 'lxml')
# Extracting publication name, publication URL, date and CU Authors
table = soup.find('div', attrs={'class': 'relation-list relation-list-publications'})
if table != None:
for row in table.findAll('div', attrs={'class': 'result-container'}):
data = {}
data["name"] = row.h3.a.text
data['pub_url'] = row.h3.a['href']
date = row.find("span", class_="date")
rowitem = row.find_all(['div'])
span = row.find_all(['span'])
data['cu_author'] = name.text
data['date'] = date.text
print("Publication Name :", row.h3.a.text)
print("Publication URL :", row.h3.a['href'])
print("CU Author :", name.text)
print("Date :", date.text)
print("\\n")
pub_data.append(data)
except Exception:
continue
print("Crawler has scrapped data for ", len(pub_data), " pureportal publications")
driver.quit()
# Writing all the scraped results in a file with JSON format
with open('scraper_results.json', 'w') as f:
ujson.dump(pub_data, f)
initCrawlerScraper('<https://pureportal.coventry.ac.uk/en/organisations/coventry-university/persons/>', max_profiles=500)
I imported the necessary modules and libraries for interacting with the operating system, performing time-related operations, working with JSON data, generating random numbers, making HTTP requests, parsing HTML data, and automating web browsing using Selenium.
The code defines a function called initCrawlerScraper, which takes a seed URL and an optional max_profiles parameter. The function uses web scraping techniques to extract publication data from the crawled web pages. It finds links to individual profiles, visits each profile, and retrieves publication information associated with each profile. The extracted data includes publication names, URLs, publication dates, and the authors' names from Coventry University. The extracted publication data is stored in the pub_data list.
Finally, the function saves the authors' URLs in a file named "Authors_URL.txt" and the scraped publication data in a JSON file named "scraper_results.json".
2. Preprocessing
I loaded the obtained scrapped file and imported NLTK libraries, including stopwords, word_tokenize, and Porter-Stemmer, for natural language processing (NLP) tasks.
2.1. Tokenization
Tokenization is the process of breaking down a text or a sequence of characters into smaller units called tokens. They can be individual words, sentences, or even sub-word units, depending on the level of tokenization applied [4].
To tokenize each publication name and the author's name into individual words, I used the nltk.tokenize module's word_tokenize function (takes the input as tokens):
import nltk
from nltk.tokenize import word_tokenize
# Open a file with publication names in read mode
with open('pub_name.json', 'r') as f:
publication = f.read()
# Load JSON File
pubName = ujson.loads(publication)
# Tokenization
tokenized_pub_list = []
for file in pubName:
tokens = word_tokenize(file)
tokenized_pub_list.append(tokens)
# Save tokenized publication list to a file
with open('tokenized_pub_list.json', 'w') as f:
ujson.dump(tokenized_pub_list, f)
This code snippet loads publication names from the pub_name.json file. Then, word_tokenize from NLTK is used to tokenize each publication name. The tokenized publication lists are stored in the tokenized_pub_list list.
Finally, the tokenized publication list is saved to the tokenized_pub_list.json file.
2.2 Stopwords
I used the nltk.corpus.stopwords module to remove commonly used English stopwords. Stopwords are words that are considered insignificant [5], such as "I", "he", "a", "the", etc. This allows focusing on more meaningful words.
Here is the code:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Open a file with publication names in read mode
with open('pub_name.json', 'r') as f:
publication = f.read()
# Load JSON File
pubName = ujson.loads(publication)
# Predefined stopwords in NLTK are used
stop_words = stopwords.words('english')
# Stopword removal
filtered_pub_list = []
for file in pubName:
tokens = word_tokenize(file) #from tokenized
filtered_tokens = [word for word in tokens if word.lower() not in stop_words]
filtered_pub = ' '.join(filtered_tokens)
filtered_pub_list.append(filtered_pub)
# Save filtered publication list to a file
with open('filtered_pub_list.json', 'w') as f:
ujson.dump(filtered_pub_list, f)
This code snippet loads publication names from the pub_name.json file, then removes stopwords using stopwords.words('english') from the NLTK library. Each publication name is tokenized using word_tokenize, and stopwords are filtered out from the tokens. The filtered tokens are then joined back into a string, and the filtered publication list is stored in the filtered_pub_list list.
Finally, the filtered publication list is saved to the filtered_pub_list.json file.
2.3 Porter-Stemmer algorithms
Stemming is the process of reducing words to their base or root form. The Porter-Stemmer algorithm applies a series of heuristic rules to remove common word endings and suffixes to achieve this reduction [6]. I used the PorterStemmer from nltk.stem to implement the Porter stemming algorithm and help group together similar words. In the search_data function, the Porter Stemmer is used to stem words before performing search operations. For example, the word "computational" and "computer" are reduced to "compute."
Here is the code:
import nltk
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer
# Open a file with publication names in read mode
with open('pub_name.json', 'r') as f:
publication = f.read()
# Load JSON File
pubName = ujson.loads(publication)
# Initialize PorterStemmer
stemmer = PorterStemmer()
# Stemming
stemmed_pub_list = []
for file in pubName:
tokens = word_tokenize(file)
stemmed_tokens = [stemmer.stem(word) for word in tokens]
stemmed_pub = ' '.join(stemmed_tokens)
stemmed_pub_list.append(stemmed_pub)
# Save stemmed publication list to a file
with open('stemmed_pub_list.json', 'w') as f:
ujson.dump(stemmed_pub_list, f)
This code snippet loads publication names from the pub_name.json file applies Porter stemming using PorterStemmer from NLTK, and tokenizes each publication name using word_tokenize. The resulting tokens are derived using the stem() method of the PorterStemmer object. They're then joined back into a string, and the stemmed publication list is stored in the stemmed_pub_list list.
Finally, the code saves the stemmed publication list to the stemmed_pub_list.json file.
2.4 Term Frequency - Inverse Document Frequency (TF-IDF)
Information retrieval and text mining are two major problems frequently using the TF-IDF weight. TF-IDF is used to:
- Determine the value of a word to a group of documents
- Give more significance to a term the more frequently it appears
TF is determined by dividing the number of times a phrase appears in a document by the total number of words [6]. On the other hand, IDF measures the term's importance, calculated as the logarithm of the number of documents in the corpus divided by the number of documents where the particular term appears [7].
I used TF-IDF to calculate the relevance or similarity between documents based on their term frequencies and the rarity of the terms in the document collection. I applied the TF-IDF vectorization using the TfidfVectorizer class from the scikit-learn library and stored the resulting TF-IDF vectors in the temp_file variable.
Finally, I used tfidf.transform(stem_word_file) to transform the stem_word_file (which represents a single document) into its TF-IDF vector representation and calculated the cosine similarity between temp_file and the TF-IDF vector of stem_word_file using the cosine_similarity() function.
Here is the code:
import ujson
from sklearn.feature_extraction.text import TfidfVectorizer
# Open a file with publication names in read mode
with open('pub_name.json', 'r') as f:
publication = f.read()
# Load JSON File
pubName = ujson.loads(publication)
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Calculate TF-IDF
tfidf_matrix = vectorizer.fit_transform(pubName)
# Get feature names (terms)
feature_names = vectorizer.get_feature_names()
# Print TF-IDF scores
for i in range(len(pubName)):
print("Publication:", pubName[i])
for j in range(len(feature_names)):
tfidf_score = tfidf_matrix[i, j]
if tfidf_score > 0:
print(" Term:", feature_names[j])
print(" TF-IDF Score:", tfidf_score)
print()
In this code snippet, the publication names are loaded from the pub_name.json file. The code uses the TfidfVectorizer from scikit-learn to calculate the TF-IDF scores. The fit_transform method is used to transform the publication names into a TF-IDF matrix. The feature names (terms) can be obtained using the get_feature_names method. The TF-IDF scores are printed for each publication and term combination.
2.5 Cosine similarity
Regardless of the size of the documents, cosine similarity can measure the text similarity between them. The cosine similarity metric has a value range from 0 to 1 and evaluates the cosine of the angle between two n-dimensional vectors projected in a multi-dimensional space; a higher value (1) indicates greater similarity [7].
Here is the code:
import ujson
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Open a file with publication names in read mode
with open('pub_name.json', 'r') as f:
publication = f.read()
# Load JSON File
pubName = ujson.loads(publication)
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Calculate TF-IDF
tfidf_matrix = vectorizer.fit_transform(pubName)
# Calculate cosine similarity
cosine_sim = cosine_similarity(tfidf_matrix)
# Example: Calculate similarity between first two publications
pub1_index = 0
pub2_index = 1
similarity_score = cosine_sim[pub1_index, pub2_index]
print("Similarity score between publication", pub1_index, "and publication", pub2_index, "is:", similarity_score)
This code snippet loads publication names from the pub_name.json file. It uses the TfidfVectorizer to calculate the TF-IDF matrix and then the cosine_similarity function to compute the cosine similarity between all pairs of vectors in the TF-IDF matrix. The similarity score is accessed between any two publications by indexing the cosine_sim matrix with the corresponding indices.
Finally, the resulting cosine similarity scores are assigned to the corresponding publication or author in the output_datadictionary. This output dictionary is what users see when they search.
2.6 Inverted index
An inverted index is a data structure used in information retrieval systems, search engines, and text analysis to efficiently store and retrieve information about the presence of keywords (or words) in a collection of documents [8]. It's called "inverted" because it reverses the link between terms and documents compared to a standard index. In traditional indexes, documents are indexed based on their unique IDs, and each entry contains a list of terms found in that document. In an inverted index, terms are organized as keys and associated with a list of documents or occurrences where they exist.
Here is the code:
data_dict = {} #empty dictionary
# Indexing process
for a in range(len(pub_list_stem_wo_sw)):
for b in pub_list_stem_wo_sw[a].split():
if b not in data_dict:
data_dict[b] = [a]
else:
data_dict[b].append(a)
To create an inverted index, the code initializes a dictionary named data_dict. This process involves a nested loop. The outer loop iterates over the length of the pub_list_stem_wo_sw list. Within each iteration, the inner loop iterates over each word in the publication name obtained by splitting the name based on spaces.
A new key-value pair is added during the inner loop if the current word is not already a key in data_dict. The key is the word itself, and the value is a list containing the current index of the publication in the pub_list_stem_wo_sw list. This way, each word is associated with a list of indices indicating the publications in which it appears. On the other hand, if the word already exists as a key in data_dict, the index of the current publication is appended to the existing list for that word. This allows for the indexing of multiple publications containing the same word.
By performing this process, the code creates an inverted index that facilitates efficient searching and retrieval of publications based on keywords. The resulting data_dict serves as a valuable resource for information retrieval tasks, providing a mapping from words to the publications where they occur. The same process was conducted for the author list.
Here is the complete code:
import nltk #NLTK for natural language processing tasks
from nltk.corpus import stopwords # list of stop word
from nltk.tokenize import word_tokenize # To tokenize each word
from nltk.stem import PorterStemmer # For specific rules to transform words to their stems
#Preprosessing data before indexing
with open('scraper_results.json', 'r') as doc: scraper_results=doc.read()
pubName = []
pubURL = []
pubCUAuthor = []
pubDate = []
data_dict = ujson.loads(scraper_results)
array_length = len(data_dict)
print(array_length)
#Seperate name, url, date, author in different file
for item in data_dict:
pubName.append(item["name"])
pubURL.append(item["pub_url"])
pubCUAuthor.append(item["cu_author"])
pubDate.append(item["date"])
with open('pub_name.json', 'w') as f:ujson.dump(pubName, f)
with open('pub_url.json', 'w') as f:ujson.dump(pubURL, f)
with open('pub_cu_author.json', 'w') as f:ujson.dump(pubCUAuthor, f)
with open('pub_date.json', 'w') as f: ujson.dump(pubDate, f)
#Open a file with publication names in read mode
with open('pub_name.json','r') as f:publication=f.read()
#Load JSON File
pubName = ujson.loads(publication)
#Predefined stopwords in nltk are used
stop_words = stopwords.words('english')
stemmer = PorterStemmer()
pub_list_first_stem = []
pub_list = []
pub_list_wo_sc = []
print(len(pubName))
for file in pubName:
#Splitting strings to tokens(words)
words = word_tokenize(file)
stem_word = ""
for i in words:
if i.lower() not in stop_words:
stem_word += stemmer.stem(i) + " "
pub_list_first_stem.append(stem_word)
pub_list.append(file)
#Removing all below characters
special_characters = '''!()-—[]{};:'"\\, <>./?@#$%^&*_~0123456789+=’‘'''
for file in pub_list:
word_wo_sc = ""
if len(file.split()) ==1 : pub_list_wo_sc.append(file)
else:
for a in file:
if a in special_characters:
word_wo_sc += ' '
else:
word_wo_sc += a
pub_list_wo_sc.append(word_wo_sc)
#Stemming Process
pub_list_stem_wo_sw = []
for name in pub_list_wo_sc:
words = word_tokenize(name)
stem_word = ""
for a in words:
if a.lower() not in stop_words:
stem_word += stemmer.stem(a) + ' '
pub_list_stem_wo_sw.append(stem_word.lower())
data_dict = {}
# Indexing process
for a in range(len(pub_list_stem_wo_sw)):
for b in pub_list_stem_wo_sw[a].split():
if b not in data_dict:
data_dict[b] = [a]
else:
data_dict[b].append(a)
print(len(pub_list_wo_sc))
print(len(pub_list_stem_wo_sw))
print(len(pub_list_first_stem))
print(len(pub_list))
with open('publication_list_stemmed.json', 'w') as f:
ujson.dump(pub_list_first_stem, f)
with open('publication_indexed_dictionary.json', 'w') as f:
ujson.dump(data_dict, f)
Step 3. Building the front end
I use Streamlit to build apps for my data science and ML projects [9]. It simplifies creating and deploying web-based user interfaces, making it easy to showcase work. Here I used Streamlit to create a search engine application portal.
Within the search portal, I defined a search function called search_data, which takes input text, operator value, and search type as parameters. The function first checks the operator value to determine which search method to use:
- Exact: The input text is stemmed and compared with the publication or author index to find matching data. Cosine similarity is calculated between the stemmed word and the retrieved data, and the results are stored in an output dictionary.
- Relevant: Multiple words are processed similarly, and matching pointers are collected. The corresponding data is transformed and compared to calculate cosine similarity, and the results are added to the output dictionary. The function provides a way to search for relevant publication or author data based on user queries and retrieves results using cosine similarity.
Here is the code:
def app():
# Load the image and display it
image = Image.open('cire.png')
st.image(image)
# Add a text description
st.markdown("<p style='text-align: center;'> Uncover the brilliance: Explore profiles, groundbreaking work, and cutting-edge research by the exceptional minds of Coventry University.</p>", unsafe_allow_html=True)
input_text = st.text_input("Search research:", key="query_input")
operator_val = st.radio(
"Search Filters",
['Exact', 'Relevant'],
index=1,
key="operator_input",
horizontal=True,
)
search_type = st.radio(
"Search in:",
['Publications', 'Authors'],
index=0,
key="search_type_input",
horizontal=True,
)
if st.button("SEARCH"):
if search_type == "Publications":
output_data = search_data(input_text, 1 if operator_val == 'Exact' else 2, "publication")
elif search_type == "Authors":
output_data = search_data(input_text, 1 if operator_val == 'Exact' else 2, "author")
else:
output_data = {}
# Display the search results
show_results(output_data, search_type)
st.markdown("<p style='text-align: center;'> Brought to you with ❤ by <a href='<https://github.com/maladeep>'>Mala Deep</a> | Data © Coventry University </p>", unsafe_allow_html=True)
def show_results(output_data, search_type):
aa = 0
rank_sorting = sorted(output_data.items(), key=lambda z: z[1], reverse=True)
# Show the total number of research results
st.info(f"Showing results for: {len(rank_sorting)}")
# Show the cards
N_cards_per_row = 3
for n_row, (id_val, ranking) in enumerate(rank_sorting):
i = n_row % N_cards_per_row
if i == 0:
st.write("---")
cols = st.columns(N_cards_per_row, gap="large")
# Draw the card
with cols[n_row % N_cards_per_row]:
if search_type == "Publications":
st.caption(f"{pub_date[id_val].strip()}")
st.markdown(f"**{pub_cu_author[id_val].strip()}**")
st.markdown(f"*{pub_name[id_val].strip()}*")
st.markdown(f"**{pub_url[id_val]}**")
elif search_type == "Authors":
st.caption(f"{pub_date[id_val].strip()}")
st.markdown(f"**{author_name[id_val].strip()}**")
st.markdown(f"*{pub_name[id_val].strip()}*")
st.markdown(f"**{pub_url[id_val]}**")
st.markdown(f"Ranking: {ranking[0]:.2f}")
aa += 1
if aa == 0:
st.info("No results found. Please try again.")
else:
st.info(f"Results shown for: {aa}")
if __name__ == '__main__':
app()
Key takeaways
I created an inverted indexing search app that allows users to search for research papers or authors and return relevant results based on cosine similarity. I used NLTK for text preprocessing, TF-IDF vectorization for feature extraction, and cosine similarity for document similarity measurement. I implemented the search feature with choices for exact or relevant matching using OR and AND operators. The code analyzes user input and tokenizes search phrases, using Streamlit to execute searches in a user-friendly manner.
A few limitations, if addressed, can lead to a better outcome:
- Slow crawling speed: Adding a one-second time delay between requests can significantly slow down the crawling process. This can be a constraint when working with large websites or accessing up-to-date information quickly.
- Search precision: While cosine similarity is a widely used statistic to assess document similarity, it may not always adequately represent semantic meaning. The search result's accuracy can be improved using word embeddings, semantic similarity measurements, or parse_dot_topn [7].
Inverted indexing can improve search experiences by providing quick access to relevant content. You can use it as a starting point for additional modifications and customization based on your unique requirements and datasets.
Wrapping up
Thank you for reading my post! Now that you've learned how to create a search engine using Python, why not take it a step further and create a search engine tailored for your university? It's a great opportunity to streamline your academic pursuits and make your research more accessible. Try it and tell me how it goes in the comments below, on LinkedIn, or on Medium.
Happy coding, and best of luck with your research! 🎈
References
[1] One Second Internet Live Stats, "1 Second - Internet Live Stats," www.internetlivestats.com. https://www.internetlivestats.com/one-second/#google-band
[2] O. Whitcombe, "The History of Search Engines," Liberty Digital Marketing, May 26, 2022. https://www.libertymarketing.co.uk/blog/a-history-of-search-engines/ (accessed Oct. 12, 2022).
[3] Wikipedia, "List of search engines," Wikipedia, May 22, 2023. https://en.wikipedia.org/w/index.php?title=List_of_search_engines&oldid=1156345015 (accessed Jun. 25, 2023).
[4] M. Hassler and G. Fliedl, "Text preparation through extended tokenization," Jun. 27, 2006. https://www.witpress.com/elibrary/wit-transactions-on-information-and-communication-technologies/37/16699 (accessed Aug. 11, 2022).
[5] S. Sarica and J. Luo, "Stopwords in Technical Language Processing," PLOS ONE, vol. 16, no. 8, p. e0254937, Aug. 2021, doi: https://doi.org/10.1371/journal.pone.0254937.
[6] N. Tsourakis, Machine Learning Techniques for Text: Apply modern techniques with Python, 1st ed. Birmingham, UK: Packt Publishing Ltd., 2022.
[7] M. D. Upadhaya, "Surprisingly Effective Way To Name Matching In Python," Medium, Mar. 27, 2022. https://towardsdatascience.com/surprisingly-effective-way-to-name-matching-in-python-1a67328e670e
[8] H. Yan, S. Ding, and T. Suel, "Inverted index compression and query processing with optimized document ordering," The Web Conference, Apr. 2009, doi: https://doi.org/10.1145/1526709.1526764.
[9] M. D. Upadhaya, "Build Your First Data Visualization Web App in Python Using Streamlit," Medium, Mar. 05, 2021. https://towardsdatascience.com/build-your-first-data-visualization-web-app-in-python-using-streamlit-37e4c83a85db (accessed Jun. 25, 2023).




Comments
Continue the conversation in our forums →