
Struggling to find a parking spot in a busy place? Then keep reading!
In this post, I'll teach you how to build a Streamlit app that detects parking spots from a live YouTube stream. You'll learn:
- How to stream from a YouTube camera to Streamlit with OpenCV
- How to detect parking spots with Mask R-CNN
- How to connect it all in Streamlit
Can't wait to try it for yourself? Here's a sample app and repo code.
Let's get started!
1. How to stream from a YouTube camera to Streamlit with OpenCV
Let's say, you're on a road trip. You've arrived in Jackson Hole, Wyoming. You want to take a selfie with the elk antler arches. But there are no parking spots. What do you do?

This is 2021. There's data for that. 😉
Jackson Hole's town square has a public webcam. Let's analyze its camera's YouTube video stream. If Google can recognize faces in photographs, why not recognize cars in parking spots? 🚗
Step 1: Import libraries for pulling the video stream into Python
# Video getting and saving
import cv2 # open cvs, image processing
import urllib
import m3u8
import time
import pafy # needs youtube_dl
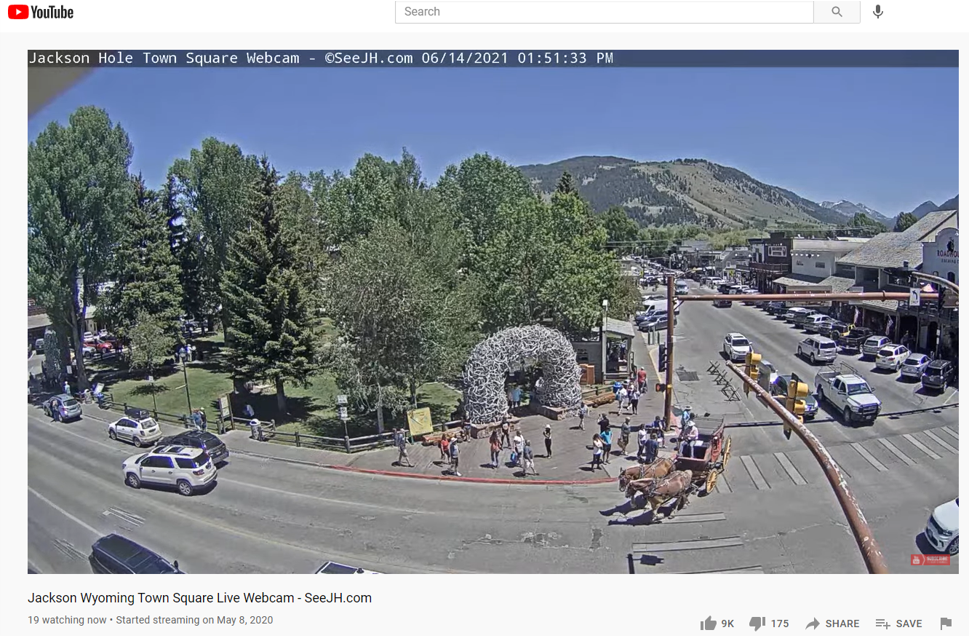
For our next app, can we help horse-drawn wagons find parking? ☝️
Step 2: Make a function to grab and display a video clip
def watch_video(video_url, image_placeholder, n_segments=1,
n_frames_per_segment=60):
"""Gets a video clip,
video_url: YouTube video URL
image_placeholder: streamlit image placeholder where clip will display
n_segments: how many segments of the YouTube stream to pull (max 7)
n_frames_per_segment: how many frames each segment should be, max ~110
"""
####################################
# SETUP BEFORE PLAYING VIDEO TO GET VIDEO URL
####################################
# Speed up playing by only showing every nth frame
skip_n_frames=10
video_warning = st.warning("showing a clip from youTube...")
# Use pafy to get the 360p url
url=video_url
video = pafy.new(url)
# best = video.getbest(preftype="mp4") # Get best resolution stream available
# In this specific case, the 3rd entry is the 360p stream,
# But that's not ALWAYS true.
medVid = video.streams[2]
# load a list of current segments for live stream
playlist = m3u8.load(medVid.url)
# will hold all frames at the end
# can be memory intestive, so be careful here
frame_array = []
# Speed processing by skipping n frames, so we need to keep track
frame_num = 0
###################################
# Loop over each frame of video, and each segment
###################################
# Loop through all segments
for i in playlist.segments[0:n_segments]:
capture = cv2.VideoCapture(i.uri)
# go through every frame in each segment
for i in range(n_frames_per_segment):
# open CV function to pull a frame out of video
success, frame = capture.read()
if not success:
break
# Skip every nth frame to speed processing up
if (frame_num % skip_n_frames != 0):
frame_num += 1
pass
else:
frame_num += 1
# Show the image in streamlit, then pause
image_placeholder.image(frame, channels="BGR")
time.sleep(0.5)
# Clean up everything when finished
capture.release() # free the video
# Removes the "howing a clip from youTube" message"
video_warning.empty()
st.write("Done with clip, frame length", frame_num)
return None
Wow, lots going on here! You've got some initial setup, then a loop where the video is being displayed one frame at a time, followed by closing the video and removing the messages the user saw while the video played.
NOTE: YouTube videos are copyrighted! YouTube terms were updated earlier in 2021 to restrict people from doing machine learning 'face harvesting' from videos. I received permission from the video poster I'm using in the example.
Step 3: Wrap this in another function to build a sidebar menu
def camera_view():
# streamlit placeholder for image/video
image_placeholder = st.empty()
# url for video
# Jackson hole town square, live stream
video_url = "<https://youtu.be/DoUOrTJbIu4>"
# Description for the sidebar options
st.sidebar.write("Set options for processing video, then process a clip.")
# Make a slider bar from 60-360 with a step size of 60
# st.sidebar is going to make this appear on the sidebar
n_frames=60 # Frames per 'segment"
n_segments = st.sidebar.slider("How many frames should this video be:",
n_frames, n_frames*6, n_frames, step=n_frames, key="spots", help="It comes in 7 segments, 100 frames each")
# We actually need to know the number of segments,
# so convert the total number of frames to the number of segments we want
n_segments = int(n_segments/n_frames)
# Add a "go" button to show the clip in streamlit
if st.sidebar.button("watch video clip"):
watch_video(video_url=video_url,
image_placeholder=image_placeholder,
n_segments=n_segments,
n_frames=n_frames)
This wrapper lets the user control when to start the video and how long it should be.
NOTE: For Streamlit Cloud to work, you'll need a requirements.txt and a packages.txt files. This tells the server what Python libraries and packages you'll need. To make requirements.txt use pip list --format=freeze > requirements.txt. The packages file contains anything you needed to install (i.e., not from PyPi or conda). This is for openCV. Use virtual environments to manage Python packages. Here's my sample requirements file and packages file.
2. How to detect parking spots with Mask R-CNN
Before you find available spots, you'll need to map out where the spots are. Following Adam Geitgey's method, I've used a video clip during 'rush hour' when all spots were full and ran Mask R-CNN to detect vehicles. The idea was to identify cars that didn't move and assume they were parked.
In technical terms, you'll detect all the cars in the first frame and make a bounding box around them. A few frames later you'll detect where all the cars are again. If any bounding boxes from the first frame are still full in the later frame, it's a parking spot. Any boxes that weren't full are considered noise and are thrown away (i.e., a car driving on the road).
Step 4: Do imports for this section, which includes Mask R-CNN
# IMPORTS
# general
import numpy as np
import pandas as pd
# File handling
from pathlib import Path
import os
import pickle
from io import BytesIO
import requests
import sys
# Import mrcnn libraries
# I am using Matterport mask R-CNN modified for tensor flow 2, see source here:
# <https://raw.githubusercontent.com/akTwelve/Mask_RCNN/master>'
# You'll need a copy of mrcnn in your working directory, it can't be installed
# from pypi yet.
import mrcnn.config
import mrcnn.utils
from mrcnn.model import MaskRCNN
Matterport's Mask R-CNN model hasn't been updated for TensorFlow 2. Luckily, someone else has done it. Use these installation instructions.
How is it going so far?
Look! You're standing on the shoulders of giants! Your tool includes code from Google (TensorFlow 2) and Facebook (Mask R-CNN). Next, you'll add pre-trained weights that enable the model to classify 80 different object categories. Two of those categories are cars and trucks. This is what will tell you if parking spots are vacant or not.
Time to make your model and load the weights.
Step 5: Create your Mask R-CNN model
def maskRCNN_model():
"""Makes a Mask R-CNN model, ideally save to cache for speed"""
weights = get_weights()
# Create a Mask-RCNN model in inference mode
model = MaskRCNN(mode="inference", model_dir="model", config=MaskRCNNConfig())
# Load pre-trained model
model.load_weights(weights, by_name=True)
model.keras_model._make_predict_function()
return model
#Let's invoke it like so, with a nice message for streamlit users.
# Give message while loading weights
weight_warning = st.warning("Loading model, might take a few minutes, hold on...")
#Create model with saved weights
model = maskRCNN_model()
weight_warning.empty() # Make the warning go away, done loading
Pass this model around to your other functions to do the object detection work.
Step 6: Combine your YouTube streaming code with the model
def detectSpots(video_file, model,
show_video=True, initial_check_frame_cutoff=10):
'''detectSpots(video_file, initial_check_frame_cutoff=10)
Returns: np 2D array of all bounding boxes that are still occupied
after initial_check_frame_cutoff frames. These can be considered "parking spaces".
An update might identify any spaces that get occupied at some point and stay occupied
for a set length of time, in case some areas start off vacant.
video_file: saved or online video file to detect on
model: mask R-CNN model
show_video: Boolean, display to streamlit or not
initial_check_frame_cutoff: The frame number to compare against the 1st. Frames
After this number will be ignored. i.e. =55, then frame 55 will have detection
run to compare which boxes from the first frame still have a car in them.
'''
# Load the video file we want to run detection on
video_capture = cv2.VideoCapture(video_file)
# Store the annotated frames for output to video/counting how many frames we've seen
frame_array = []
# Will contain bounding boxes of parked cars to identify 'parkable spots'
parked_car_boxes = []
# same as above, but for final pass
parked_car_boxes_updated = []
# Make image appear in streamlit
image_placeholder_processing = st.empty()
# Loop over each frame of video
while video_capture.isOpened():
success, frame = video_capture.read()
if not success:
st.write(f"Processed {len(frame_array)} frames of video, exiting.")
return parked_car_boxes
# Convert the image from BGR color (which OpenCV uses) to RGB color
rgb_image = frame[:, :, ::-1]
# ignore the inbetween frames 0 to x, don't run the model on them and save processing time
if 0 < len(frame_array) < initial_check_frame_cutoff:
print(f"ignore this frame for processing, #{len(frame_array)}")
else:
print(f"Processing frame: #{len(frame_array)}")
# Run the image through the Mask R-CNN model to get results
results = model.detect([rgb_image], verbose=0)
# Mask R-CNN assumes we are running detection on multiple images.
# We only passed in one image to detect, so only grab the first result.
r = results[0]
# The r variable will now have the results of detection:
# - r['rois'] are the bounding box of each detected object
# - r['class_ids'] are the class id (type) of each detected object
# - r['scores'] are the confidence scores for each detection
# - r['masks'] are the object masks for each detected object (which gives you the object outline)
if len(frame_array) == 0:
# This is the first frame of video,
# Save the location of each car as a parking space box and go to the next frame of video.
# We check if any of those cars moved in the next 5 frames and assume those that don't are parked
parked_car_boxes = get_car_boxes(r['rois'], r['class_ids'])
parked_car_boxes_init = parked_car_boxes
print('Parking spots 1st frame:', len(parked_car_boxes))
# If we are past the xth initial frame, already know where parked cars are, then check if any cars moved:
else:
# We already know where the parking spaces are. Check if any are currently unoccupied.
# Get where cars are currently located in the frame
car_boxes = get_car_boxes(r['rois'], r['class_ids'])
# See how much those cars overlap with the known parking spaces
overlaps = mrcnn.utils.compute_overlaps(parked_car_boxes, car_boxes)
# Loop through each known parking space box
for row, areas in enumerate(zip(parked_car_boxes, overlaps)):
parking_area, overlap_areas = areas
# For this parking space, find the max amount it was covered by any
# car that was detected in our image (doesn't really matter which car)
max_IoU_overlap = np.max(overlap_areas)
# Get the top-left and bottom-right coordinates of the parking area
y1, x1, y2, x2 = parking_area
# Check if the parking space is occupied by seeing if any car overlaps
# it by more than x amount using IoU
if max_IoU_overlap < 0.20:
# In the first few frames, remove this 'spot' and consider it as a moving car instead
# Transient event, draw green box
cv2.rectangle(frame, (x1, y1),
(x2, y2), (0, 255, 0), 3)
else:
# Consider this a parking spot, car is still in it!
# Dangerous to mutate array while using it! So using a copy
parked_car_boxes_updated.append(list(parking_area))
# Parking space is still occupied -> draw a red box around it
cv2.rectangle(frame, (x1, y1),
(x2, y2), (0, 0, 255), 1)
# Write the top and bottom corner locations in the box for ref
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, str(parking_area),
(x1 + 6, y2 - 6), font, 0.3, (255, 255, 255))
parked_car_boxes = np.array(
parked_car_boxes_updated) # only happens once
# print number of frames
font = cv2.FONT_HERSHEY_COMPLEX_SMALL
cv2.putText(frame, f"Frame: {len(frame_array)}",
(10, 340), font, 0.5, (0, 255, 0), 2, cv2.FILLED)
# Show the frame of video on the screen
if show_video:
image_placeholder_processing.image(frame, channels="BGR")
time.sleep(0.01)
# Append frame to outputvideo
frame_array.append(frame)
# stop when cutoff reached
if len(frame_array) > initial_check_frame_cutoff:
print(f"Finished, processed frames: 0 - {len(frame_array)}")
break
# Clean up everything when finished
video_capture.release()
#write_frames_to_file(frame_array=frame_array, file_name=video_save_file)
# Show final image in matplotlib for ref
return parked_car_boxes
The machine learning toolbox has something called "intersection over union" or IoU. IoU calculates the number of pixels where two bounding boxes overlap. IoU is used heavily inside of CNNs to find the 'best' bounding box around detected objects, removing all the initial overlapping guesses.
Set a cutoff to determine how 'occupied' a box needs to be, to be considered full. Think of this as a 'fraction of overlap' where 1 = perfect overlap and 0 = no overlap.
Here is what it looks like.
First frame:

Identify ALL cars in this frame and save their bounding box.
Nth frame:

Compare IoU on the boxes from the first frame with the cars in this frame. If IoU is high (i.e., there's still a car in the spot), count it as a parking spot. Red = 'parking spot' (had a car in both frames). Green = 'not a valid spot' (didn't have cars in the nth frame).
But look...

This method isn't perfect! Notice the red boxes that aren't parking spots? One was never a car. And in another one, two separate cars happened to be in the same place. This caused the algorithm to consider it a parking spot.
Step 7: Combine your YouTube clip with the detected parking spot to see which spots are full or empty
- Detect all cars in the given frame.
- For each car, see if it's overlapping a parking spot.
- Color the parking spot boxes red if filled and green if vacant.
- Repeat for all frames.
This code is similar to the detect spots function. It's doing the same things but on all processed frames instead of only two. Need help? See the function countSpots() in my repo code linked at the top.
3. How to connect it all in Streamlit
Well done! You've built the framework for a solid app.
Step 8: Tie all these functions together with a Streamlit interface
st.title("Title: Spot Or Not?")
st.write("Subtitle: Parking Spot Vacancy with Machine Learning")
# Render the readme as markdown using st.markdown as default
# This loads a markdown file from your github. Much cleaner than putting loads
# of text in your Streamlit app! Easier to edit too!
readme_text = st.markdown(get_file_content_as_string("instructions.md"))
# Add a menu selector for the app mode on the sidebar.
st.sidebar.title("Settings")
app_mode = st.sidebar.selectbox("Choose the app mode",
["Show instructions", "Live data", "Camera viewer","Show the source code"])
if app_mode == "Show instructions":
st.sidebar.success('Next, try selecting "Camera viewer".')
# Loads the source code and displays it
elif app_mode == "Show the source code":
readme_text.empty()
st.code(get_file_content_as_string("streamlit_app.py"))
elif app_mode == "Live data":
# Add horizontal line to sidebar
st.sidebar.markdown("___")
readme_text.empty()
live_mode()
elif app_mode == "Camera viewer":
# Add horizontal line to sidebar
st.sidebar.markdown("___")
readme_text.empty()
camera_view()
I didn't go over the live_mode() function, but it's essentially a wrapper for detectSpots() and countSpots(), similar to what you've built for the camera viewer. Streamlit reruns the ENTIRE app every time you make a menu selection. Newer versions of Streamlit (such as 1.0 and later) can store session state. To keep things simple, stick with this menu.
Let's walk through what happens here.
After the app loads, it'll display the "show instructions" (the first item in your selectbox). If a user selects a different option, you need to clear the readme_text using readme_text.empty(). .empty()tells Streamlit to clear that particular object. Then you run your wrapper functions to show whatever it is the user selected in the main area. Since you don't have a session state, you don't need to 'erase' the previous choice, except the default- readme_text.
Wrapping up

Congratulations! You did it. You got a video stream from YouTube, used unsupervised machine learning to detect parking spaces from a video, identified which of those spaces are vacant, and tied it all together in Streamlit.
If you plan to deploy to Streamlit Cloud, do it early and test it regularly to avoid package dependency despair. Keep building and don't give up!
What's next?
Parking lot vacancy data has many potential uses:
- Vehicle routing—send vehicles to open spots via navigation app or digital signage.
- Proxy for how busy an area is (shopping malls, airports, conference centers, etc.) to inform visitors.
- Identification of the commonly used "parking spots" that aren't allowed (illegal parking).
If you found working with these tools amazing and frustrating at the same time, let's agree to ride a bike next time and avoid the parking hassle! 🚲
Got questions? Let me know in the comments below or message me on LinkedIn.
Happy Streamlit-ing! ❤️
References:
- Acharya, Yan. Real-time image-based parking occupancy detection using deep learning.
- Cazamias, Marek (2016). Parking Space Classification using Convolutional Neural Networks.
- Amato, Giuseppe; Carrara, Fabio; Falchi, Fabrizio; Gennaro, Claudio; Vairo, Claudio. Accessed June 2021, CNR park.
- COCO dataset, used to train Matterport model.
- Dwivedi, Priya (2018). Find where to park in real time using OpenCV and Tensorflow.
- Geitgey, Adam (2019). Snagging parking spaces with mask R CNN and Python.
- He, Kaiming; Gkioxari, Georgia; Dollár, Piotr; Girshick, Ross (2017). Original Mask R-CNN paper by Facebook research.




Comments
Continue the conversation in our forums →