
Your headphones are on. Your favorite Spotify playlist is on shuffle. You like the music, but something is off. You keep hitting "next," searching for that special feeling. Finally, you start scrolling through your algorithmically created playlists. Spotify made them just for you, but they don't feel like you. They feel like a stereotype.
Sound familiar? You're not alone. Here is what I realized…
The recommended playlists feel off because they play the same songs!
I wanted the music to transport me to a unique time and place in my life—like high school. So I built a Streamlit app to help discover old favorites. Choose the years and get the Spotify playlist link with the top songs.
In this post, I'll show you:
- How to scrape Billboard Hot 100 top-ten singles
- How to make 1,000+ playlists with the Spotify API
- How to build an app to present the playlists to the users
Ready to go? Let's get into it!
How to scrape Billboard Hot 100 top-ten singles
To start, let's get some song data. Helpfully, Wikipedia lists Hot 100 singles for the years 1958-2022. Use Python (and pandas) to scrape the song lists from the corresponding Wikipedia pages and store them in a CSV file.
For example, here is the 1958 year page (with a song list HTML table):
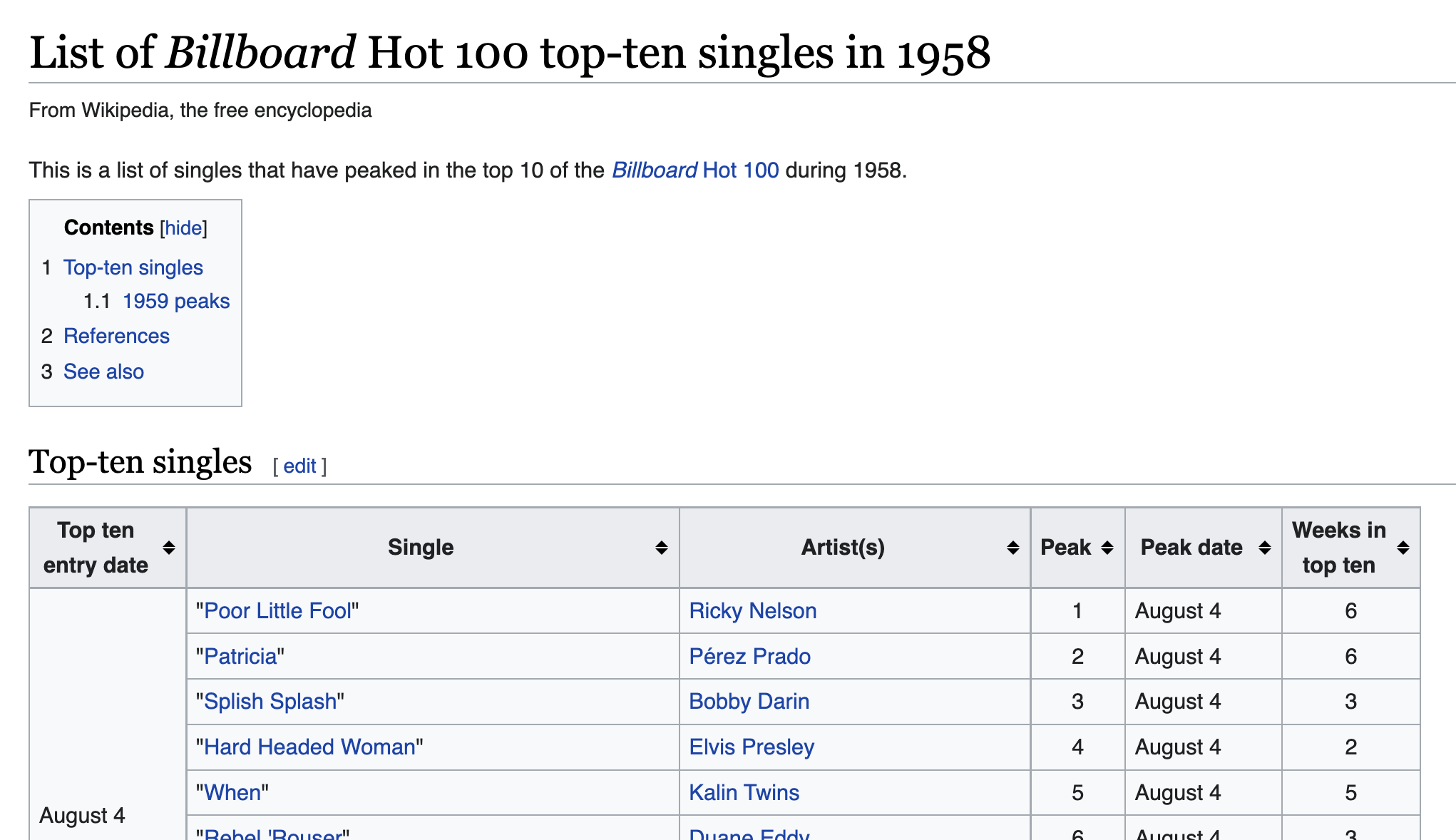
The page URLs differ by year so that you can generate each URL with a bit of code:
# We will need these later so go ahead and import them now
import pandas as pd
import numpy as np
urls = []
for year in range(1958, 2023):
urls.append(f"<https://en.wikipedia.org/wiki/List_of_Billboard_Hot_100_top-ten_singles_in_{year}>")
If you haven't already, install pandas, numpy, spotipy, and lxml by using PyPi (you can run it in your notebook or your preferred environment manager):
!pip install pandas numpy spotipy lxml
Next, write a loop to go to each URL, grab the HTML table with the pandas read_html method, and extract the table with the top songs.
Since every page has multiple HTML tables, I needed to figure out how to find the one with the song data. I settled on finding the largest table by the row count as it contained the most songs.
Here is the loop with the code to clean up the tables:
rows = []
for url, year in zip(urls, range(1958, 2023)):
print(year)
dfs = pd.read_html(url)
row_num = []
for df in dfs:
row_num.append(df.shape[0])
year_df = dfs[row_num.index(max(row_num))]
year_df = year_df.iloc[:,:6]
columns = ['entry_date','title','artist','peak','peak_date','weeks_top_ten']
year_df.columns = columns
year_df = year_df[~pd.to_numeric(year_df['peak'], errors='coerce').isna()].reset_index(drop=True)
year_df['year'] = year
rows.extend(year_df.to_dict(orient='records'))
df = pd.DataFrame(rows)
The resulting pandas DataFrame has over 5,000 songs and columns for the title, the artist, and the year:

Song names by themselves aren't useful. To make a Spotify playlist, you need to know the Spotify URI for the song. It's a unique identifier that Spotify uses for each track, album, or playlist. Let's use the Spotify API plus a very convenient package, Spotipy (get it? 😉), to look up the URIs.
But first, clean up the song titles (Spotify's API doesn't like certain characters) with some code:
to_replace = ["/", "\\\\", "(", ")", "'", ":", "."]
for item in to_replace:
df['title'] = df['title'].str.replace(item,"", regex=False)
Now import Spotipy and make a loop to look up each song title from the search endpoint. As this endpoint doesn't require user authentication, you can use the SpotifyClientCredentials class to create a server-to-server authentication. Later you'll need to complete user authentication to create your playlists.
The loop below converts your pandas DataFrame to a list of dictionaries and loops through it. The loop queries the API using the track title and the artist name for each song list item. This returns multiple results. I naively chose to grab and save the first URI!
It's possible that a similar artist and song name could give the wrong result—like a remix or a re-release of the song. I tested this on about 20 songs, and it returned the correct result each time, so I decided this simple approach worked for the app.
After you grab the URI, it gets saved in the row dictionary. Once the loop is complete, save the list of dictionaries back to the pandas DataFrame:
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
spotify = spotipy.Spotify(client_credentials_manager=SpotifyClientCredentials())
list_df = df.to_dict(orient='records')
for item in list_df:
try:
result = spotify.search(
f"""track:{item['title']} artist:{item['artist']}""", type="track", limit=1
)
if len(result["tracks"]["items"]) > 0:
item["spotify_uri"] = result["tracks"]["items"][0]["uri"]
else:
item["spotify_uri"] = np.nan
except spotipy.client.SpotifyException as e:
item["spotify_uri"] = str(e.http_status) + " - " + e.msg
df = pd.DataFrame(list_df)
To clean up the results, drop the rows with NaN values (empty cells) and the rows where the API has returned "Not found":
df = df.dropna()
df = df[~df['spotify_uri'].str.contains("Not found")]
Your songs are now ready to go with the included URI! Save the results in a CSV file:
df.to_csv('songs.csv', index=False)
How to make 1000+ playlists with the Spotify API
Before creating playlists, head to the Spotify Developer Dashboard and make an app. Take note of the client ID and the secret. Set them as environment variables so Spotipy can use them when authenticating:
import spotipy
from spotipy.oauth2 import SpotifyOAuth
import os
os.environ["SPOTIPY_CLIENT_ID"] = your client ID
os.environ["SPOTIPY_CLIENT_SECRET"] = your client secret
os.environ["SPOTIPY_REDIRECT_URI"] = <http://localhost:8080>
Next, authenticate with OAuth as a registered Spotify user (who you'll make playlists for) to access user data via the API:
Step 1. Get an authorization URL to sign in and receive a token:
# Sets up authentication and scope.
auth_manager = SpotifyOAuth(scope="playlist-modify-public",
open_browser=False)
auth_manager.get_authorize_url()
Copy the link and paste it into the browser. After you sign in with your Spotify account, you'll be redirected to your local machine. In the URL bar, you'll see your authentication code:
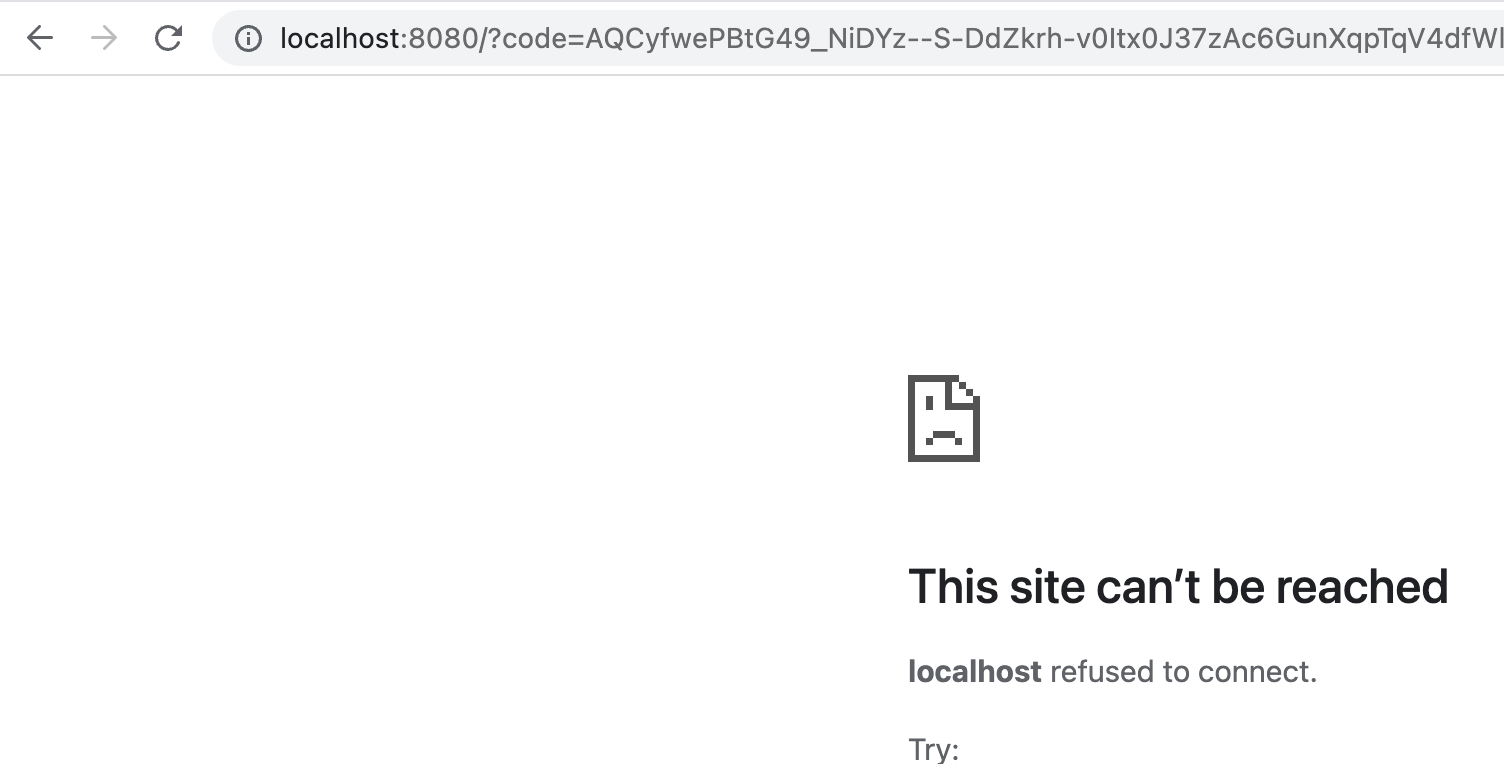
Step 2. Copy the code and paste it in the "token here" spot in the code below:
auth_manager.get_access_token("token here", as_dict=False)
You're now authenticated and can interact with your Spotify account via the API. See if it worked by checking the current user:
spotify = spotipy.Spotify(auth_manager=auth_manager)
user_dict = spotify.current_user()
user_dict
# Output - If it worked you should see a dictionary like this.
{'display_name': 'Datafantic',
'external_urls': {'spotify': '<https://open.spotify.com/user/31s4ct55ob6xjoghw4uxspvyu34u>'},
'followers': {'href': None, 'total': 0},
'href': '<https://api.spotify.com/v1/users/31s4ct55ob6xjoghw4uxspvyu34u>',
'id': '31s4ct55ob6xjoghw4uxspvyu34u',
'images': [],
'type': 'user',
'uri': 'spotify:user:31s4ct55ob6xjoghw4uxspvyu34u'}
See your account info? You're good to go. Save your created playlists in a CSV file, then make an empty pandas DataFrame and save it to playlists.csv (you'll add the column names later):
pd.DataFrame(columns=['id','name','link']).to_csv("playlists.csv", index=False)
To create playlists, I made some convenience functions (to simplify things and prevent a giant loop that's hard to debug):
- The main function,
make_playlist, takes the start and the end year, finds songs from those years, and creates the playlist. - Another function,
check_playlists, checks if the playlist has already been made. I did this after accidentally making 20 playlists and then having to delete them one by one on the web. - Finally,
save_playliststakes the created playlist and adds it to theplaylists.csvfile which looks up the playlists on the app:
def check_playlists(playlist_name, playlists_df):
"""Checks if playlist has already been created."""
result = playlists_df[playlists_df['name'] == playlist_name].shape[0]
if result > 0:
return False
else:
return True
def save_playlists(playlist, playlist_name, playlists_df):
"""Saves playlist in a csv file."""
new_playlist = {
'name':playlist_name,
'id':playlist['id'],
'link':playlist['external_urls']['spotify']
}
playlists_df = pd.concat([playlists_df, pd.DataFrame([new_playlist])])
playlists_df.to_csv("playlists.csv", index=False)
def make_playlist(start_year, end_year):
"""Makes the playlist and adds tracks from songs.csv given the start and end year"""
playlists_df = pd.read_csv("playlists.csv")
if (start_year - end_year) == 0:
playlist_name = f"Top US Singles: {start_year}"
else:
playlist_name = f"Top US Singles: {start_year}-{end_year}"
if check_playlists(playlist_name, playlists_df):
description = 'This playlist was generated automatically for a project on Datafantic.com.'
playlist = spotify.user_playlist_create(user=user_dict['id'],
name=playlist_name,
description=description)
uris = list(df[(df['year'] >= start_year) & (df['year'] <= end_year)]['spotify_uri'].values)
chunked_uris = np.array_split(uris, math.ceil(len(uris) / 100))
for uri_list in chunked_uris:
spotify.user_playlist_add_tracks(user=user_dict['id'],
playlist_id=playlist['id'],
tracks=uri_list)
save_playlists(playlist, playlist_name, playlists_df)
With these functions, you can create playlists for arbitrary start and end years.
I initially thought to allow users to generate these playlists on the fly as they interact with the app. But that would take too much work to debug and ensure it was working in the cloud. So I opted to batch-create playlists for a list of start/end years.
I generated a list of start/end years with a 1 to 20 years gap. Since we can't make playlists into the future, I slice the years' list minus the gap to ensure no playlists can be made past 2022:
years = list(range(1958, 2023))
year_pairs = []
for width in range(0,21):
for year in years[:-width]:
year_pairs.append((year, year+width))
Now you can use your make_playlist function above to generate your playlists:
for pair in year_pairs:
make_playlist(pair[0], pair[1])
If you noticed, I left out single-year playlists (only 1958 or only 2022). The year_pairs list didn't include single years. Luckily there are convenience functions that you can loop through the list of years and make the playlists:
for year in years:
make_playlist(year, year)
I was impressed with how fast the Spotify API performed. It took about two seconds to create each playlist and about 43 minutes to run the loop of over 1,000 playlists. You can multi-thread this to speed things up (and have enough time for a snack 😉).
Once complete, you'll see the CSV file with all your playlists. Visit the links and see your playlist live on Spotify:
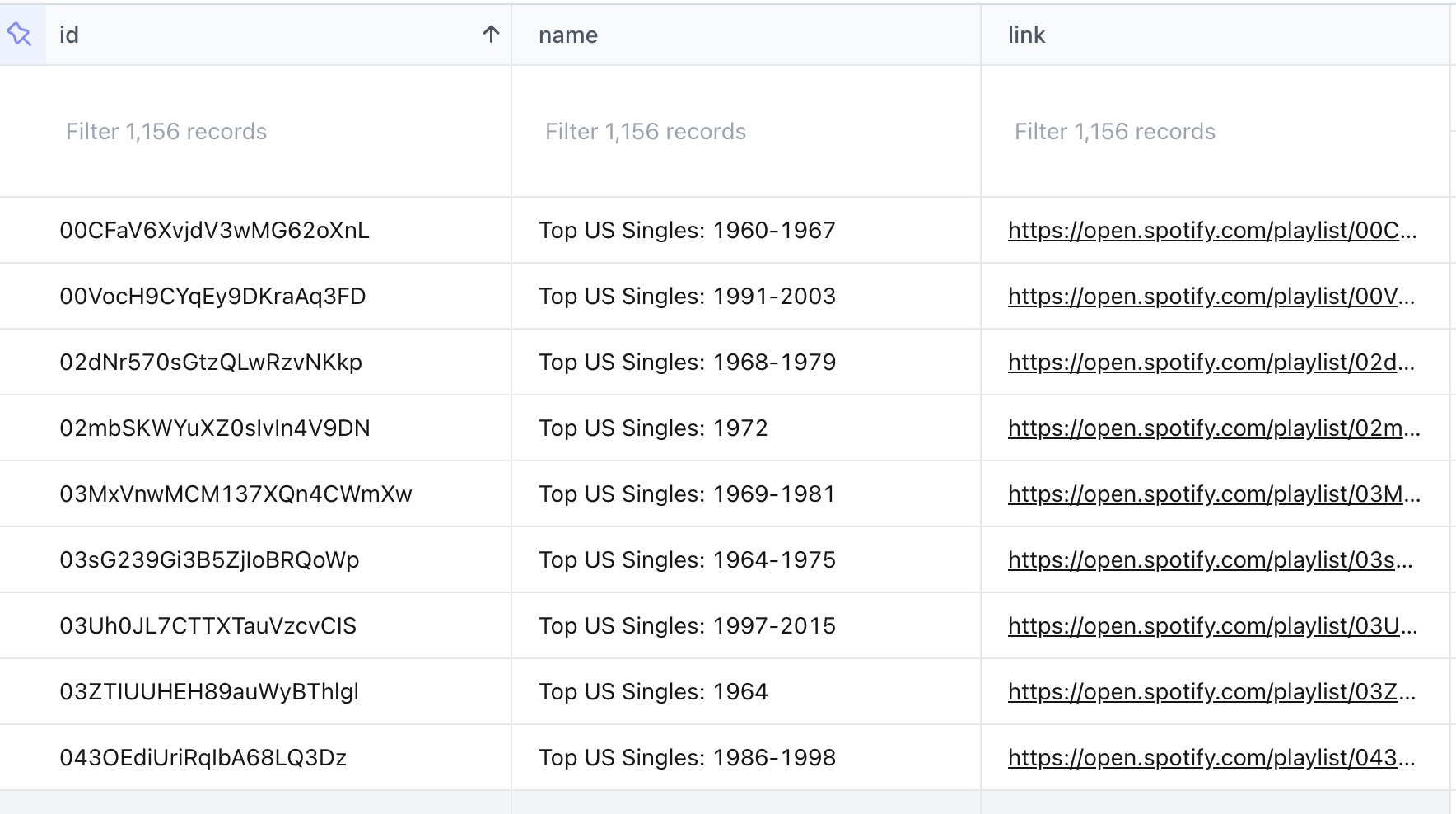
Now let's move on to building an app!
How to build an app to present the playlists to the users
The Streamlit app is super simple:
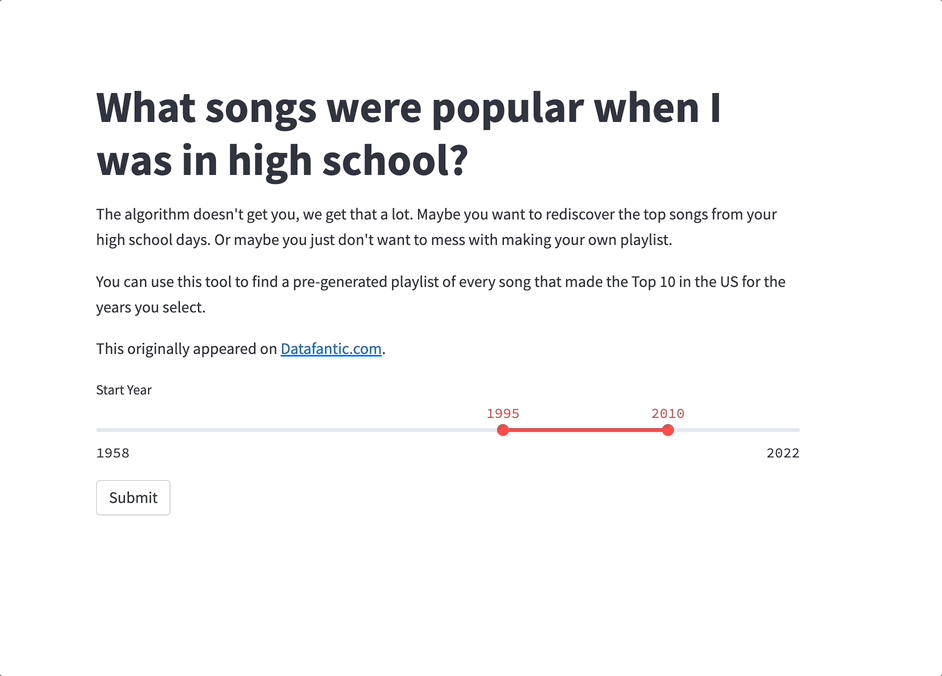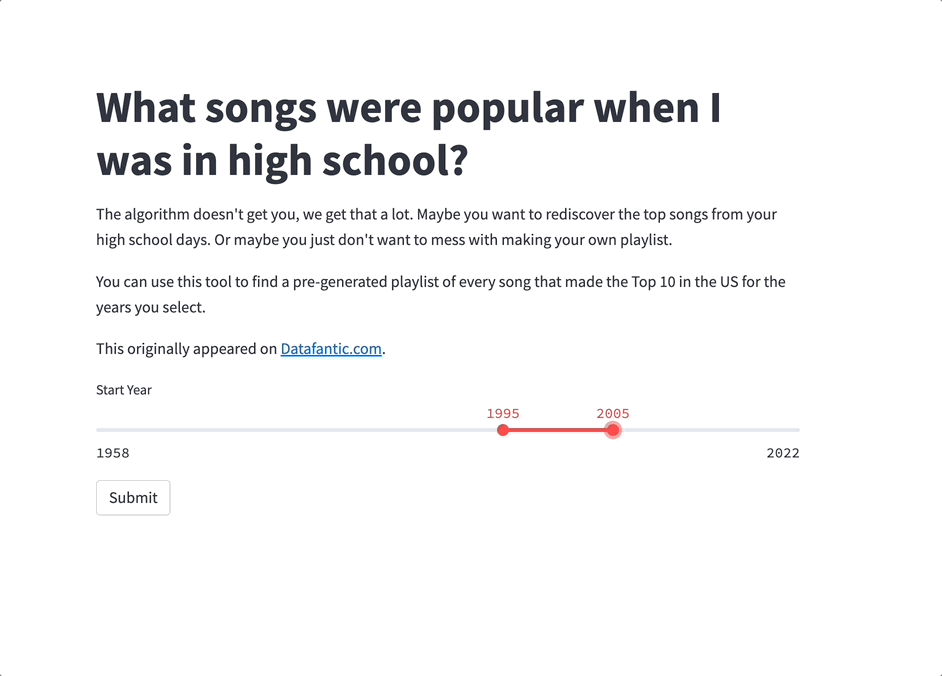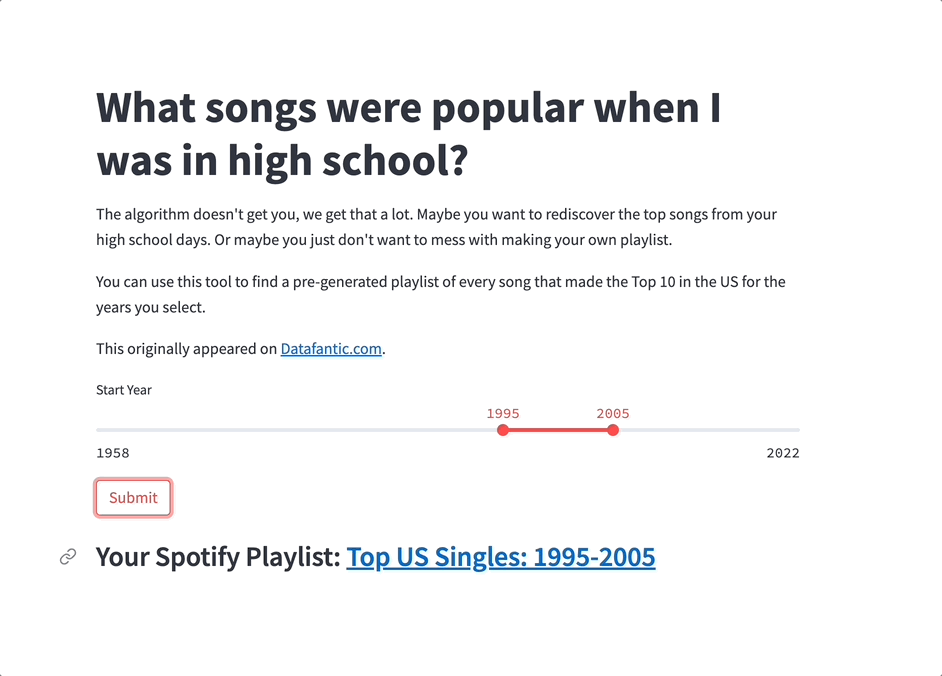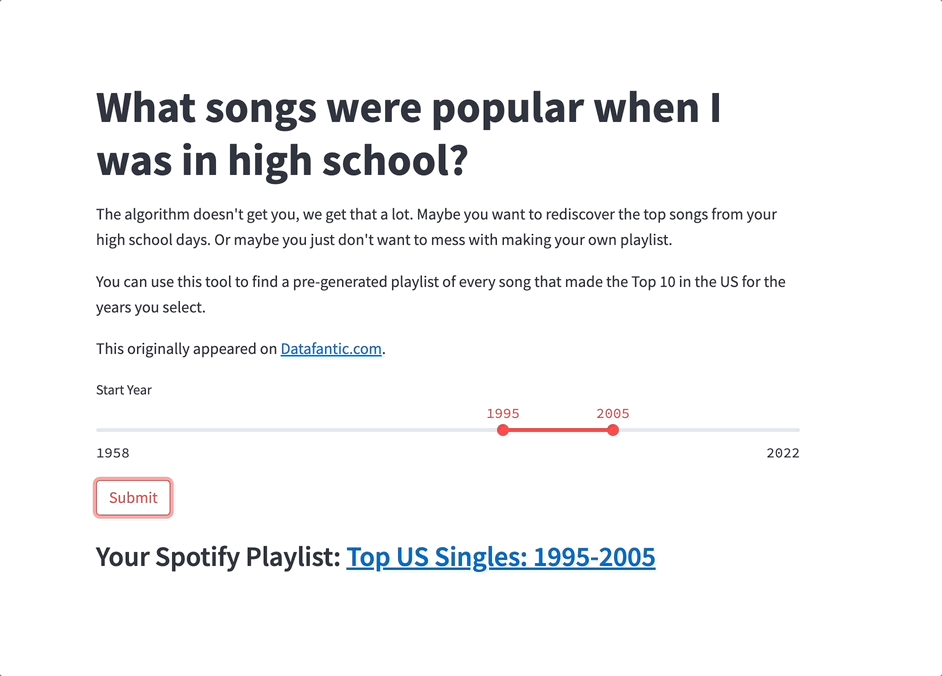
Start by making a new Python file (call it streamlit_app.py or whatever you like). It'll define the structure and content of your app. You'll be adding the code step by step.
I like adding a title and some descriptive text at the top of apps to give the user some context. In this Python file, write the imports you need and use the st.markdown component to add text:
import pandas as pd
import streamlit as st
st.markdown("""# What songs were popular when I was in high school?
The algorithm doesn't get you, we get that a lot. Maybe you want to rediscover the top songs from your high school days. Or maybe you just don't want to mess with making your own playlist.
You can use this tool to find a pre-generated playlist of every song that made the Top 10 in the US for the years you select.
This originally appeared on [Datafantic.com](<https://www.datafantic.com/what-songs-were-popular-when-i-was-in-high-school>).
""")
Next, import your playlist.csv file by using Pandas with the read_csv method. Add a year slider for the user to define their playlist years. By passing a tuple to the value parameter (value=(1995, 2010)) you get two handles on the slider, allowing a minimum and a maximum year to be selected:
df = pd.read_csv("playlists.csv")
years = list(range(1958, 2022))
year_range = st.slider(label="Start Year",
min_value=1958,
max_value=2022,
value=(1995, 2010))
Next, add a submit button. When clicked, it'll filter the DataFrame to find the playlist based on the slider values. The playlist link will be added to Markdown and displayed to the user. If a playlist isn't found, the user will see a simple error message:
if st.button('Submit'):
if (int(year_range[0]) - int(year_range[1])) == 0:
playlist_name = f"Top US Singles: {year_range[0]}"
else:
playlist_name = f"Top US Singles: {year_range[0]}-{year_range[1]}"
if df[df['name'] == playlist_name].shape[0] > 0:
playlist = df[df['name'] == playlist_name].to_dict(orient='records')[0]
else:
playlist = "Ooops, it looks like we didn't make that playlist yet. Playlists with a range of 1-20 years were created. Try again with a more narrow year range."
if isinstance(playlist, dict):
link = f"### Your Spotify Playlist: [{playlist['name']}]({playlist['link']})"
st.markdown(link, unsafe_allow_html=True)
else:
st.markdown(playlist)
Wrapping up
I made this Streamlit app for my blog, datafantic.com. I analyze the top songs and how they have changed in this blog post. After publishing my app, I was surprised to get so much positive feedback.
Initially, I wanted to improve Spotify recommendations. Algorithmic song recommendations gave me a bad experience (I couldn't find what I wanted). Turns out, even simple curated playlists are immensely valuable to people. Algorithms stick us in a box—and not everyone likes that.
I might extend this app in the future to:
- Let the user enter the location. Regional differences in song preferences exist, but you'd need data to do this.
- Let the user sign in with Spotify to get a playlist based on their recent play history.
- Give the user some context about how their current play history compares to the top charts by using their Spotify sign-in.
I hope you enjoyed this app and are inspired to build cool Streamlit apps to share with the world. Thanks for reading! 🙏




Comments
Continue the conversation in our forums →