Do you want to find like-minded people on Hacker News with a similar commenting history?
We've got you covered!
In this post, you'll learn how to build a Doppelgänger app in three simple steps:
- Create a vector database in Pinecone.
- Build an app in Streamlit.
- Combine the two together.
Can't wait and want to see how it works? Try the app right here.
But before we get into building it, let's answer one question...
Why a Doppelgänger app?
Searching for your celebrity doppelgänger isn’t a new idea. In fact, it’s so unoriginal that no one has updated the celebrity-face dataset in three years!
But we weren't looking for celebrities. We were looking for users with matching comment histories—Hacker News "celebrities" like patio11, tptacek, and pc.
At Pinecone, we've built a vector database that makes it easy to add semantic search to production applications. We were intrigued by the idea of making a semantic search app for Hacker News. Could it compare the semantic meaning of your commenting history with the histories of all the other users?
So we thought, "How about the doppelgänger idea but for Hacker News?"
It took only a few hours to build it, with most of that time being spent on converting raw data into vector embeddings (more below) and debating which users to feature as examples. The app got a lot of attention on Hacker News (Surprise!), getting thousands of visitors and 215 comments. Many people asked how it works, so here's an inside look at how we made it and how you can make your own version.
Step 1. Create a vector database of Hacker News users
1. Create a database in Pinecone
Create a new vector index for storing and retrieving data by semantic similarity. We use cosine similarity as it's more intuitive and widely used with word vectors.
!pip install -qU pinecone-client
!pip install -qU sentence-transformers
!pip install -qU google-cloud-bigquery
!pip install -q pyarrow pandas numpy
import pinecone
import os
# Load Pinecone API key
api_key = os.getenv('PINECONE_API_KEY') or 'YOUR_API_KEY'
# Set Pinecone environment. Default environment is us-west1-gcp
env = os.getenv('PINECONE_ENVIRONMENT') or 'us-west1-gcp'
pinecone.init(api_key=api_key, environment=env)
index_name = 'hackernews-doppel-demo'
pinecone.create_index(index_name, dimension=300, metric="cosine", shards=1)
index = pinecone.Index(index_name)
2. Retrieve the data
Create a class to collect the data from the publicly available dataset on BigQuery. Get every comment and story from every user that hasn't been deleted or labeled as "dead" in the last three years (stories and comments killed by software, moderators, or user flags).
from google.cloud.bigquery import Client
class BigQueryClient:
__client = None
@classmethod
def connect(cls):
os.environ[
'GOOGLE_APPLICATION_CREDENTIALS'] = '<file_name>'
cls.__client = Client()
@classmethod
def get_client(cls):
if cls.__client is None:
cls.connect()
return cls.__client
3. Prepare and embed the data
Collect and merge all available data for each user—with no additional processing steps and no weights added to comments or stories.
You'll face two limitations:
- Caring about all comments and stories equally.
- Capturing exactly why a user was matched with someone else if they've changed interests in the last three years.
Next, create a single embedding for each user with the help of the average word embeddings of Komninos and Manandhar (about three hours). This algorithm works much faster when compared to other state-of-the-art approaches (such as the commonly used BERT model).
from sentence_transformers import SentenceTransformer
MODEL = SentenceTransformer('average_word_embeddings_komninos')
import pandas as pd
import numpy as np
from typing import List
class NewsDataPrep():
def load_data(self, interval: int) -> pd.DataFrame:
news_data = pd.DataFrame()
try:
print('Retrieving data from bigquery..')
query = f"""
SELECT distinct b.by as user, b.title, b.text
FROM `bigquery-public-data.hacker_news.full` as b
WHERE b.timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(),
INTERVAL {interval} DAY)
AND b.timestamp <= TIMESTAMP_SUB(CURRENT_TIMESTAMP(),
INTERVAL {interval - 90} DAY)
AND (b.deleted IS NULL AND b.dead IS NULL)
AND (b.title IS NOT NULL OR b.text IS NOT NULL)
AND b.type in ('story', 'comment');
"""
query_job = BigQueryClient.get_client().query(query)
news_data = query_job.to_dataframe()
except Exception as e:
if '403' in str(e):
print('Exceeded quota for BigQuery! (403)')
if '_InactiveRpcError' in str(e):
print('Pinecone service is not active '
'at the moment (_InactiveRpcError)')
print(e)
return news_data
def get_embeddings(self, news_data: pd.DataFrame) -> List:
def func(x):
return [*map(np.mean, zip(*x))]
news_data.title.fillna(value='', inplace=True)
news_data.text.fillna(value='', inplace=True)
news_data['content'] = news_data.apply(
lambda x: str(x.title) + " " + str(x.text), axis=1)
vectors = MODEL.encode(news_data.content.tolist())
news_data['vectors'] = vectors.tolist()
news_data_agg = (news_data.groupby(['user'], as_index=False)
.agg({'vectors': func}))
# return user_embeddings
return list(zip(news_data_agg.user, news_data_agg.vectors))
4. Insert the data
Now insert the data (as vector embeddings) into the Pinecone database. Our total index size (the number of inserted embeddings) was around 230,000. Each data point was represented as a single tuple that contained a user ID and a corresponding vector. Each vector contained 300 dimensions.
import itertools
def chunks(iterable, batch_size=100):
it = iter(iterable)
chunk = tuple(itertools.islice(it, batch_size))
while chunk:
yield chunk
chunk = tuple(itertools.islice(it, batch_size))
data_days_download= 1100
news_data_prep = NewsDataPrep()
for i in range(data_days_download, 0, -90):
print(f'Loading data from {i - 90} to {i} days in the past')
news_data = news_data_prep.load_data(interval=i)
print('Creating embeddings. It will take a few minutes')
embeddings = news_data_prep.get_embeddings(news_data)
print('Starting upsert')
for batch in chunks(embeddings, 500):
index.upsert(vectors=batch)
print('Upsert completed')
5. Query Pinecone
Your database is ready to be queried for the top 10 similar users given any user ID (represented as a vector embedding). Let's build a Streamlit app so that anyone can do this through their browser.
Step 2. Build the app in Streamlit
The above summarized the data preparation and the database configuration steps (see the Pinecone quickstart guide for instructions). With the data vectorized and loaded into Pinecone, you can now build a Streamlit app to let anyone query that database through the browser.
1. Install Streamlit
Install Streamlit by running:
pip install streamlit
To see some examples of what Streamlit is capable of, run:
streamlit hello
2. Create a base Streamlit app
Create a base class to represent your Streamlit app. It'll contain a store and an effect object. You'll use the effect object to initialize Pinecone and to save the index name in the store. Next, add a render method to handle the page layout.
In a Streamlit app, each user action prompts the screen to be cleared and the main function to be run. Create the app and call render. In render, use st.title to display a title, then call render on the home page.
import streamlit as st
class App:
title = "Hacker News Doppelgänger"
def __init__(self):
self.store = AppStore()
self.effect = AppEffect(self.store)
self.effect.init_pinecone()
def render(self):
st.title(self.title)
PageHome(self).render()
if __name__ == "__main__":
App().render()
3. Create Store and Effects
The store will be used to hold all the data needed to connect to Pinecone. To connect to a Pinecone index, you'll need your API key and the name of your index. You'll take this data from environment variables.
To set these locally, run:
export PINECONE_API_KEY=<api-key> && export PINECONE_INDEX_NAME=<index-name>
These can be set in a published Streamlit app during the creation process or by changing the settings on a running app:
import os
from dataclasses import dataclass
API_KEY = os.getenv("PINECONE_API_KEY")
INDEX_NAME = os.getenv("PINECONE_INDEX_NAME")
@dataclass
class AppStore:
api_key = API_KEY
index_name = INDEX_NAME
Use the AppEffect class to connect your app to Pinecone (with init) and to the index (docs):
class AppEffect:
def __init__(self, store: AppStore):
self.store = store
def init_pinecone(self):
pinecone.init(api_key=self.store.api_key)
def init_pinecone_index(self):
return pinecone.Index(self.store.index_name)
4. Layout the page
Create and fill out the render method of the PageHome class.
First, use st.markdown to display instructions. Under it, display the buttons for suggested usernames. Use st.beta_columns to organize Streamlit elements in columns and st.button to place a clickable button on the page.
If the app's last action was clicking on that button, then st.button will return True. Save the value of that user in st.session_state (to save and use this value between renderings):
def render_suggested_users(self):
st.markdown("Try one of these users:")
columns = st.beta_columns(len(SUGGESTED_USERNAMES))
for col, user in zip(columns, SUGGESTED_USERNAMES):
with col:
if st.button(user):
st.session_state.username = user
Below the suggested users, show a text entry where the user can enter any username and a submit button which they can click on, to search.
To do this, use st.form with st.text_input and st.form_submit_buttonm. If you have a selected username saved in st.session_state.markdown, put that value in the text box. Otherwise, leave it empty for user input.
Now, return the value from st.form_submit_button . It'll return true if the user clicked the submit button on the last run:
def render_search_form(self):
st.markdown("Or enter a username:")
with st.form("search_form"):
if st.session_state.get('username'):
st.session_state.username = st.text_input("Username", value=st.session_state.username)
else:
st.session_state.username = st.text_input("Username")
return st.form_submit_button("Search")
Once the user searches, render the results. Use st.spinner to show a progress indicator to the user while loading the results. Because of Pinecone's blazing-fast search speeds, the loading icon won't be visible for long!
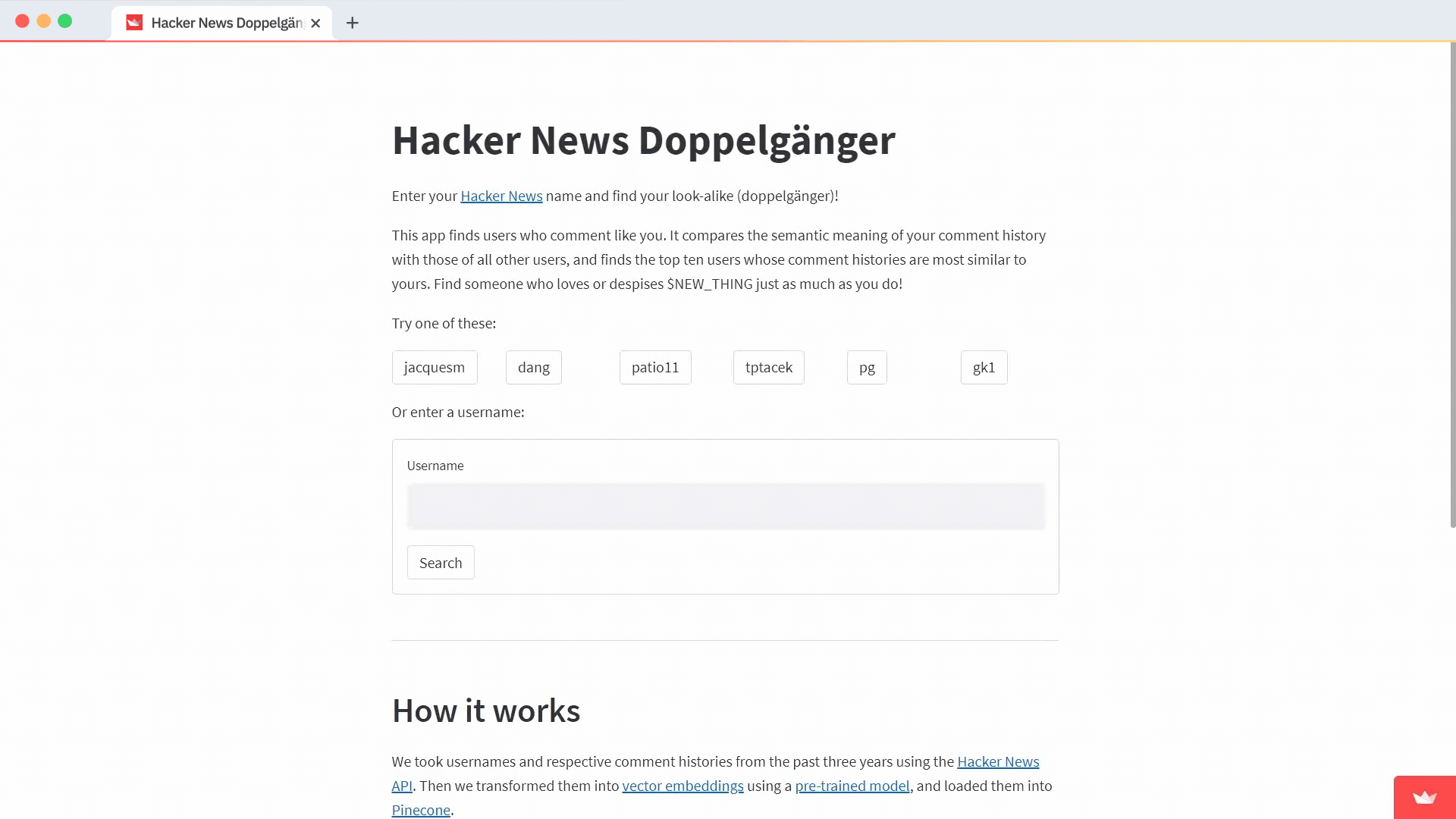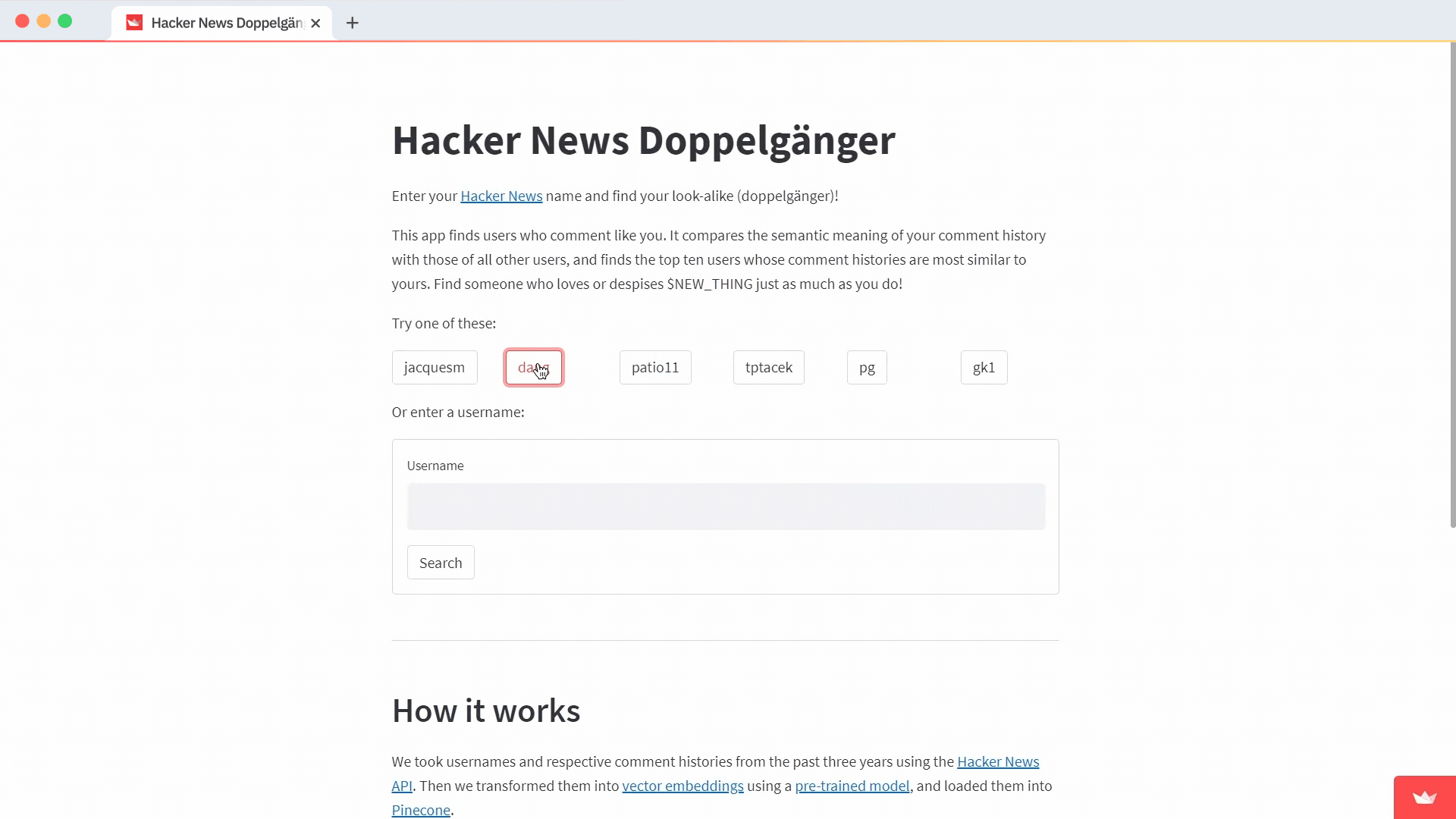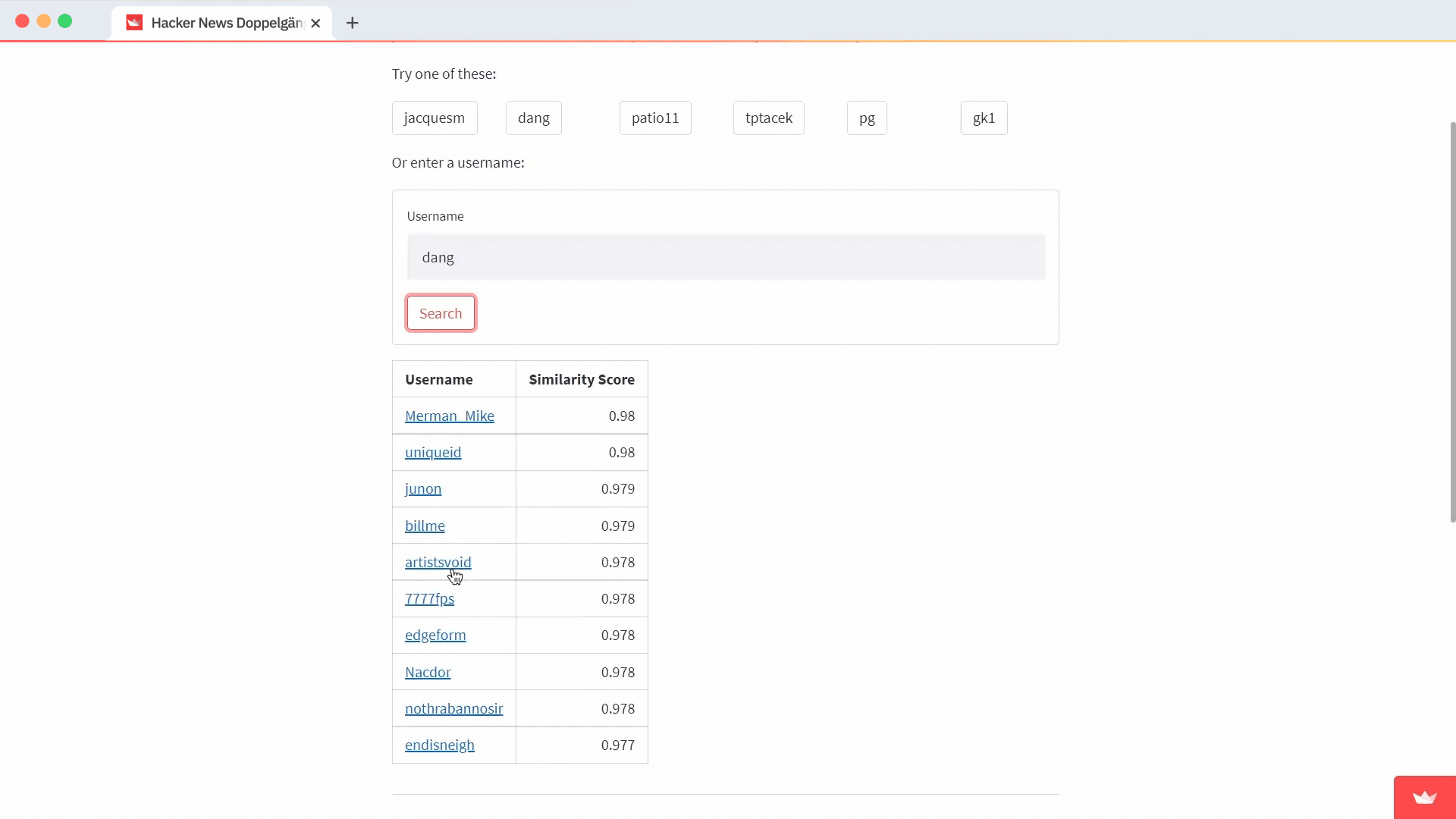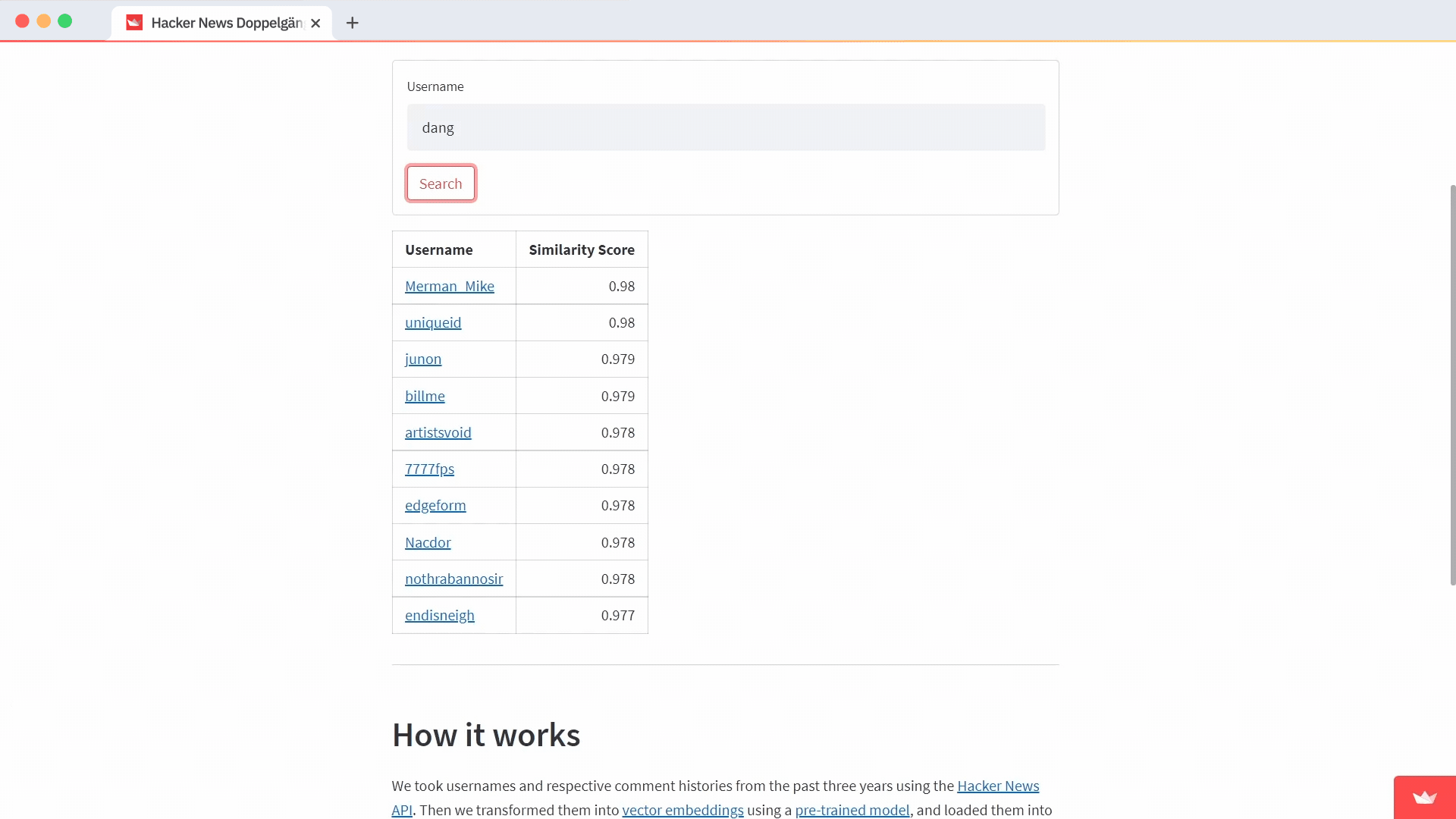
To complete the search, fetch the user from your Pinecone index using the entered username as the ID. No vector for the user? That means they didn't have any activity on Hacker News in the last three years, so you'll see an error message.
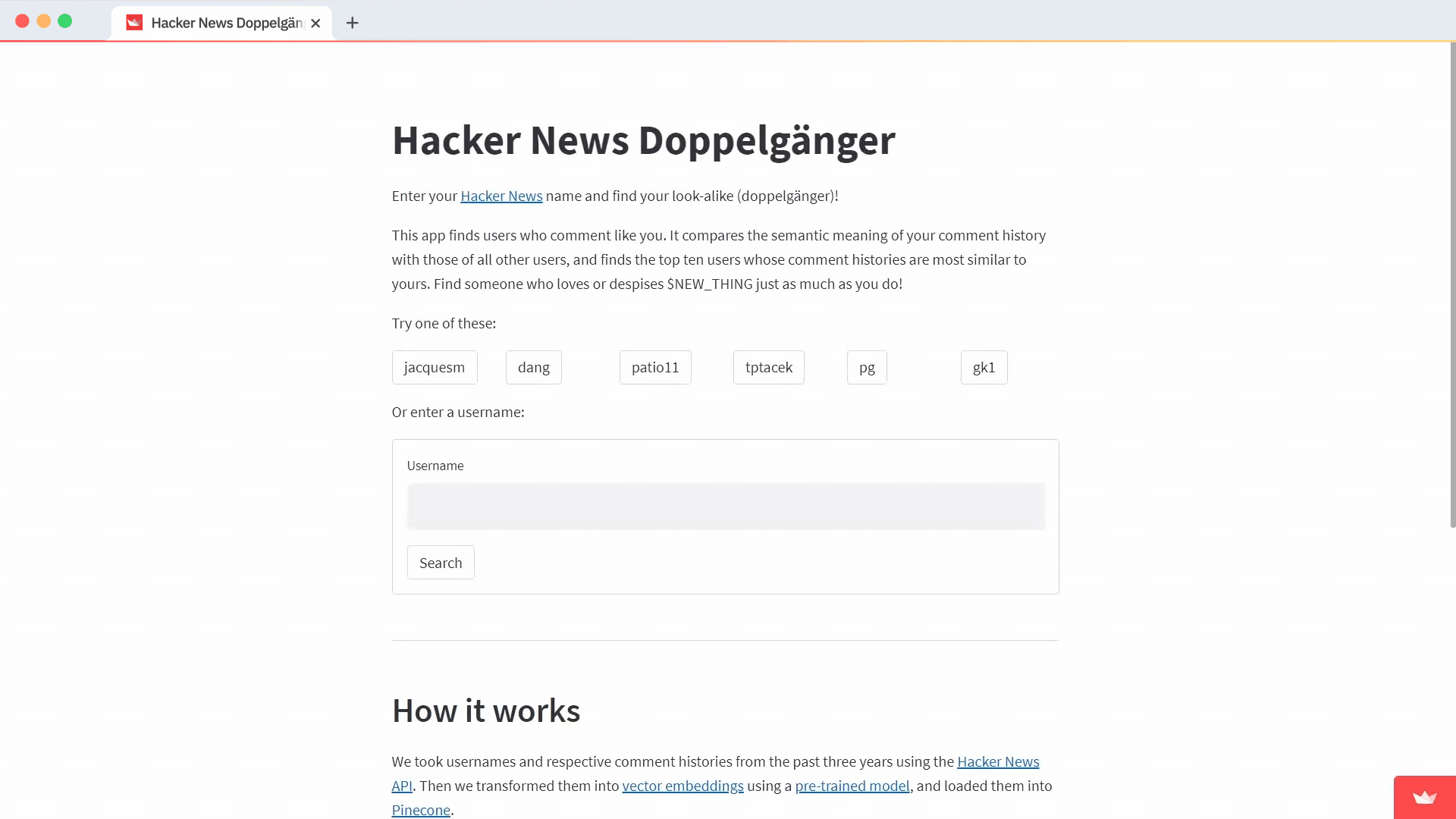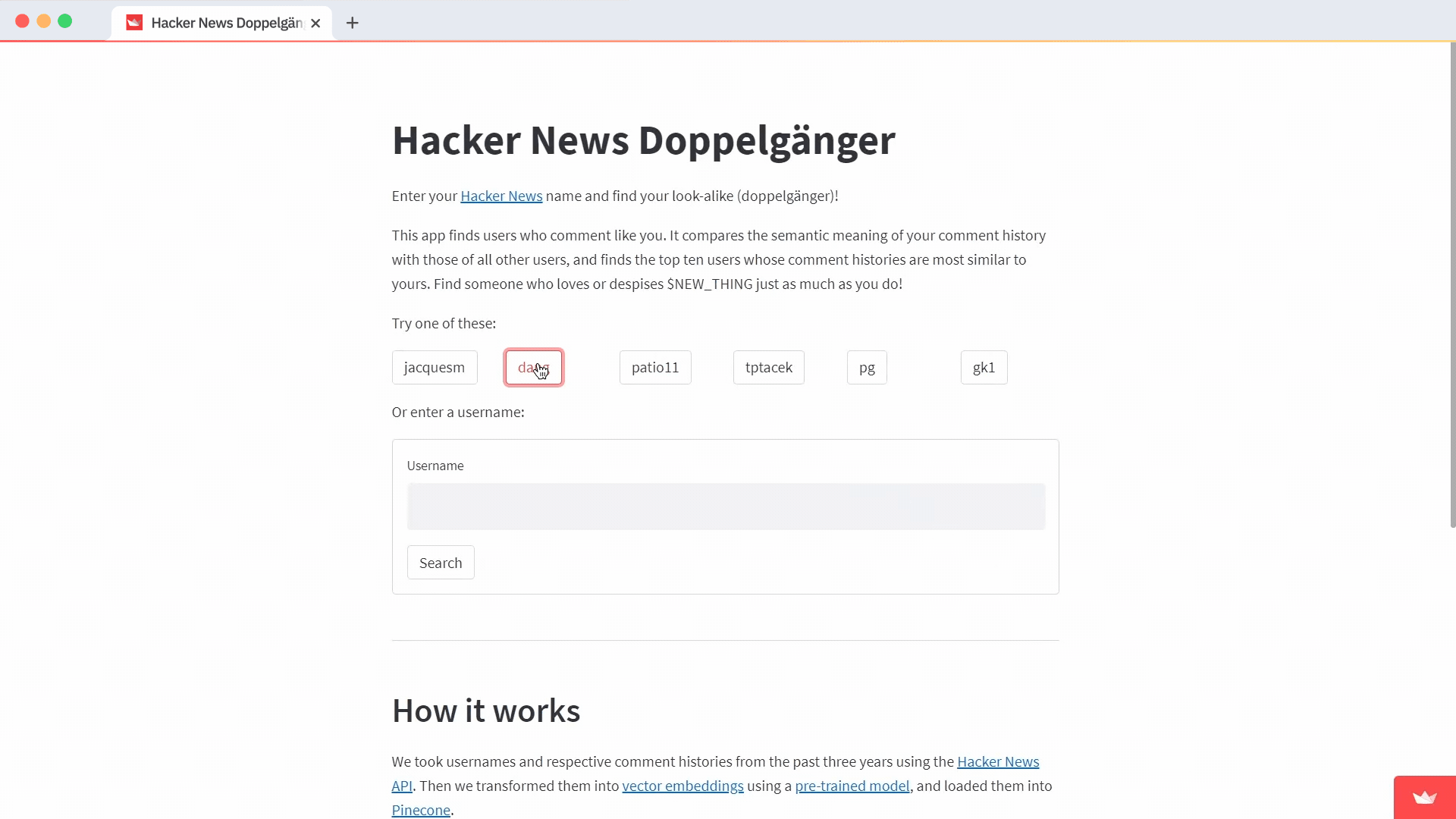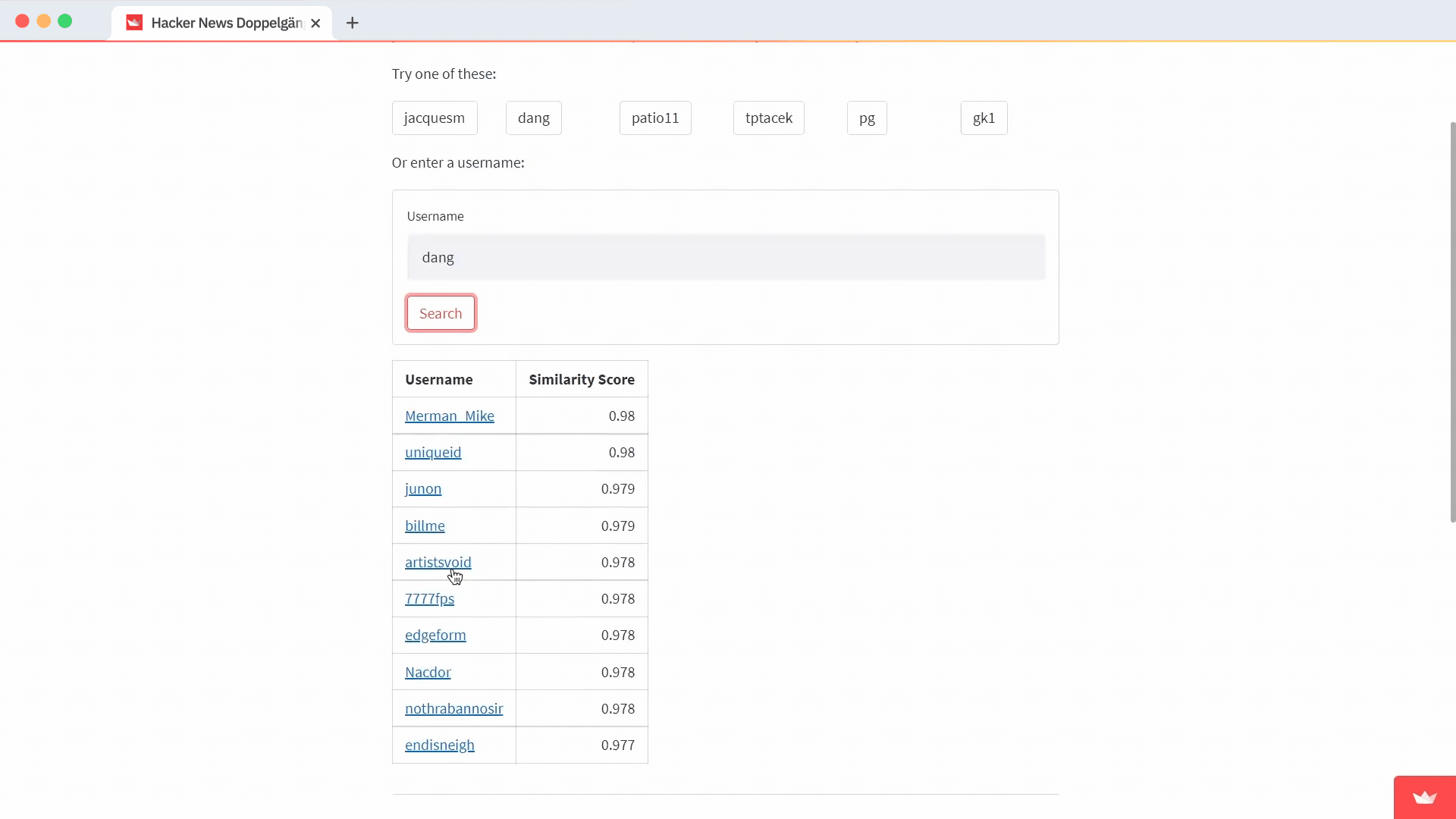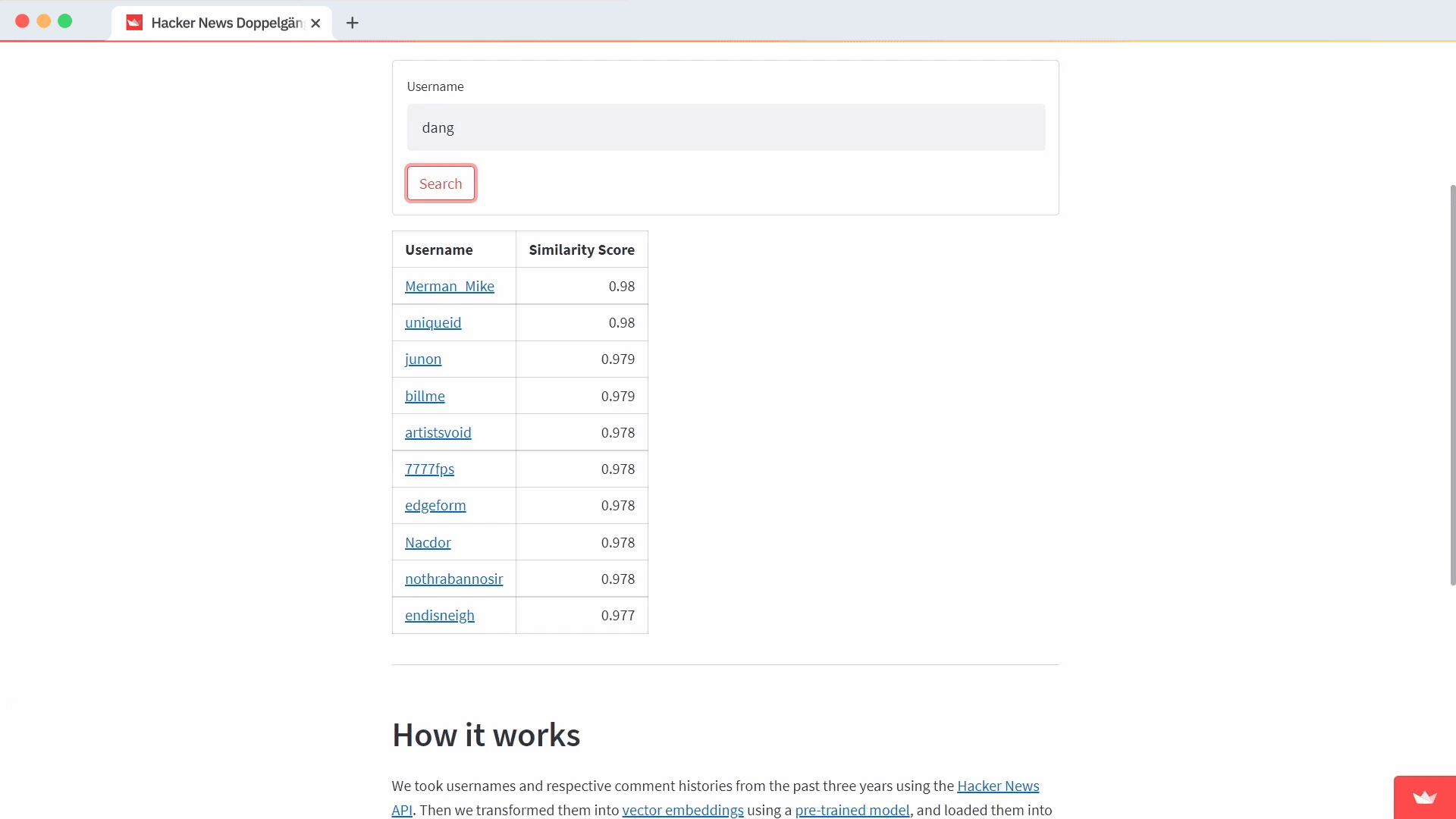
If you find a user, query Pinecone for the closest matches. Use a Markdown table to display the results and include a link to their Hacker News comment history as well as the proximity score for each result:
def render_search_results(self):
with st.spinner("Searching for " + st.session_state.username):
result = self.index.fetch(ids=st.session_state.username)
has_user = len(result.vector) != 0
if !has_user:
return st.markdown("This user does not exist or does not have any recent activity.")
with st.spinner("Found user history, searching for doppelgänger"):
closest = self.index.queries(queries=result.vector, top_k=11)
results = [{'username': id, 'score': round(score, 3)}
for id, score in zip(closest.ids, closest.scores)
if id != st.session_state.username][:10]
result_strings = "\\n".join([
f"|[{result.get('username')}](<https://news.ycombinator.com/threads?id={result.get('username')}>)|{result.get('score')}|" for result in results
])
markdown = f"""
| Username | Similarity Score |
|----------|------:|
{result_strings}
"""
with st.beta_container():
st.markdown(markdown)
Step 3. Combine the two together
You're almost done! All that's left is to tie it all together in a single render method:
class PageHome:
def __init__(self, app):
self.app = app
@property
def index(self):
return self.app.effect.init_pinecone_index()
def render(self):
self.render_suggested_users()
submitted = self.render_search_form()
if submitted:
self.render_search_results()```
Congratulations! 🥳
You now have a fully functioning Hacker News Doppelgänger app. Run streamlit.app.py and navigate to localhost:8051 to see your app in action.
Wrapping up
Thank you for reading this post. We're very excited to have shared this with you and we hope this inspires you to build your own semantic search application with Pinecone and Streamlit.
Have questions or improvement ideas? Please leave them in the comments below or send them to info@pinecone.io or @pinecone.
Happy app-building! 🎈




Comments
Continue the conversation in our forums →