
Large language models (LLMs) are trained on massive amounts of text data using deep learning methods. The resulting model can perform a wide range of natural language processing (NLP) tasks, broadly categorized into seven major use cases: classification, clustering, extraction, generation, rewriting, search, and summarization (read more in Meor Amer posts here and here).
In the previous LangChain tutorials, you learned about two of the seven utility functions: LLM models and prompt templates. In this tutorial, we’ll explore the use of the document loader, text splitter, and summarization chain to build a text summarization app in four steps:
- Get an OpenAI API key
- Set up the coding environment
- Build the app
- Deploy the app
What is text summarization?
Text summarization involves creating a summary of a source text using natural language processing. This is useful for condensing long-form text, audio, or video into a shorter, more digestible form that still conveys the main points. Examples include news articles, scientific papers, podcasts, speeches, lectures, and meeting recordings.
There are two main types of summarization:
- Extractive summarization. This type identifies and extracts key phrases or sentences (i.e., excerpts) from the source text and combines them into a summary. It leaves the original text unchanged and only selects the important parts.
- Abstractive summarization. This type involves understanding the main ideas in the source text and creating a new summary that expresses those ideas in a fresh and condensed way (i.e., paraphrasing). It's more complex because it requires a deeper understanding of the source text and the ability to convey the same information in fewer words.
App overview
At a high level, the app's workflow is relatively simple:
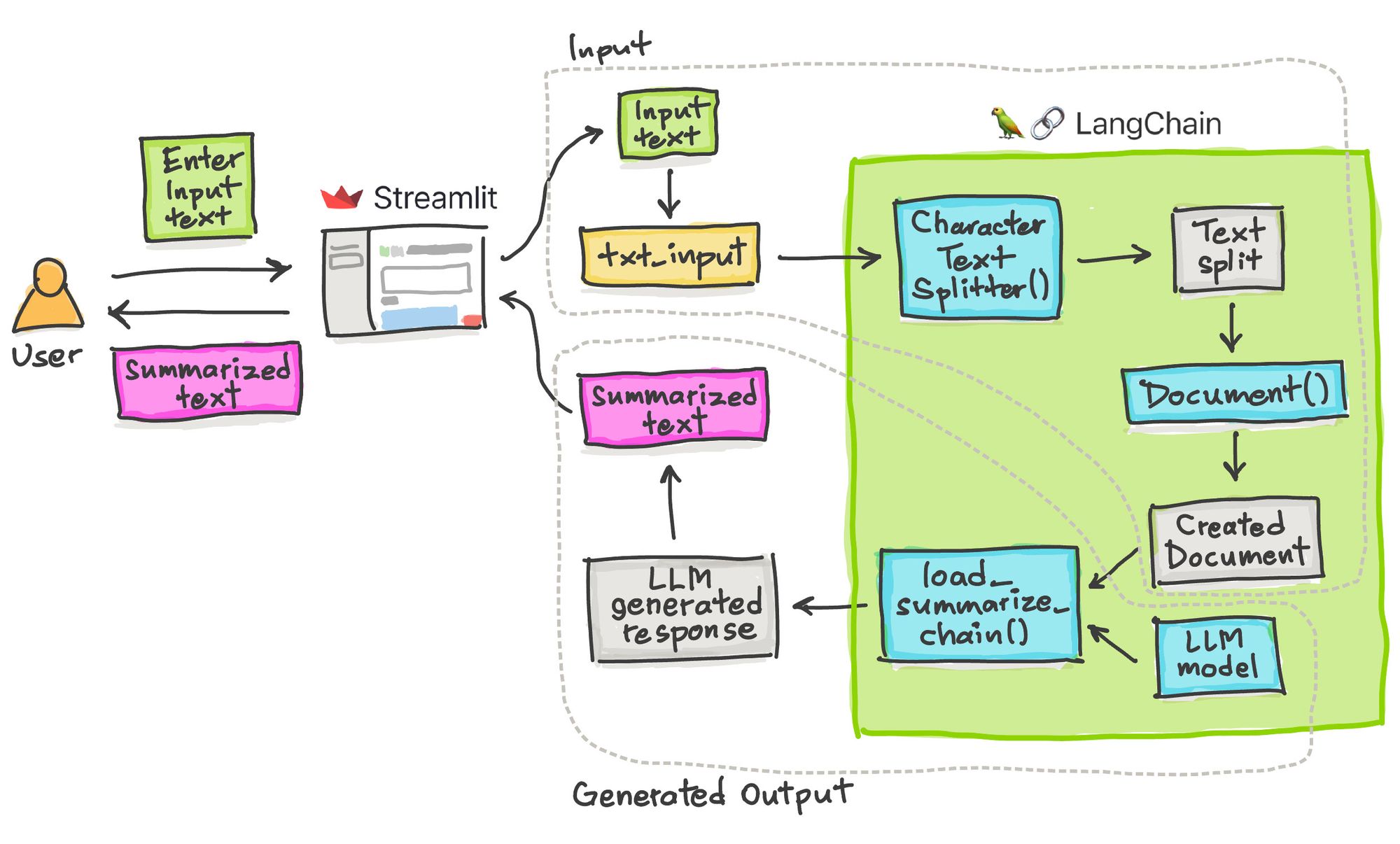
- The user submits an input text to be summarized into the Streamlit frontend.
- The app pre-processes the text by splitting it into several chunks, creating documents for each chunk, and applying the summarization chain with the help of the LLM model.
- After a few moments, the summarized text is displayed in the app.
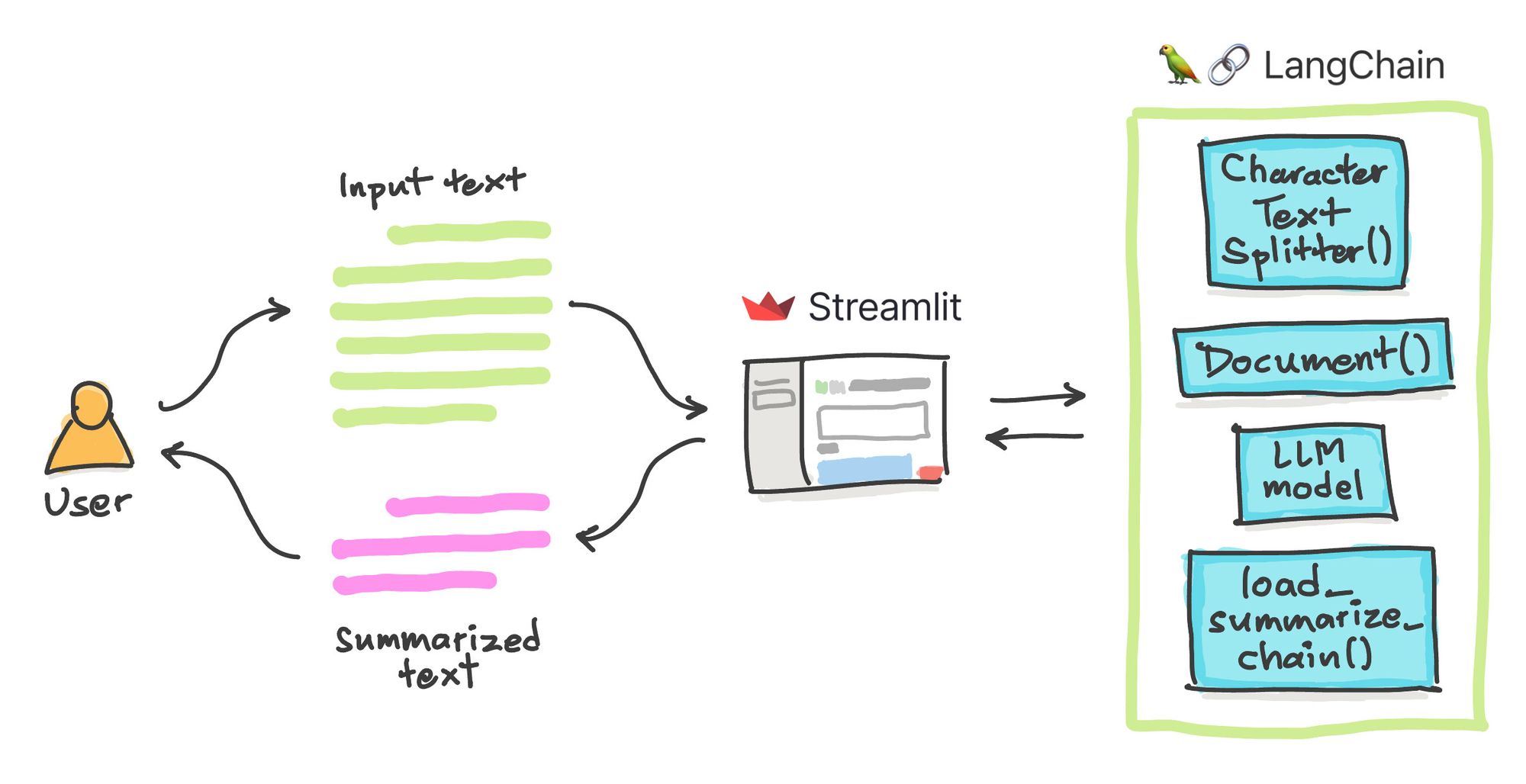
Let's take a closer look at the underlying details for when (1) the input text is submitted for processing by the app and (2) an LLM-generated response is created as summarized text.
- Input. The input text is first split into several chunks of text using
CharacterTextSplitter(), followed by the creation of documents for each text split viaDocument(). - Generated Output. The processed text will then serve as input, along with the LLM model, to the
load_summarize_chain()function. The text will be transformed into a concise form as summarized text.
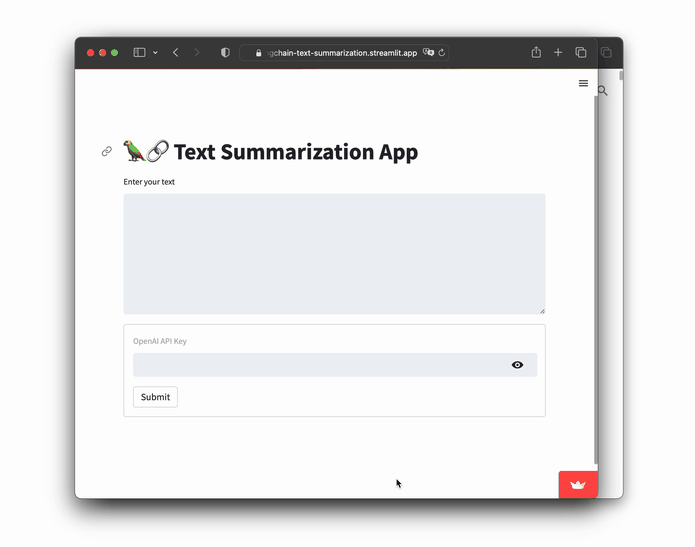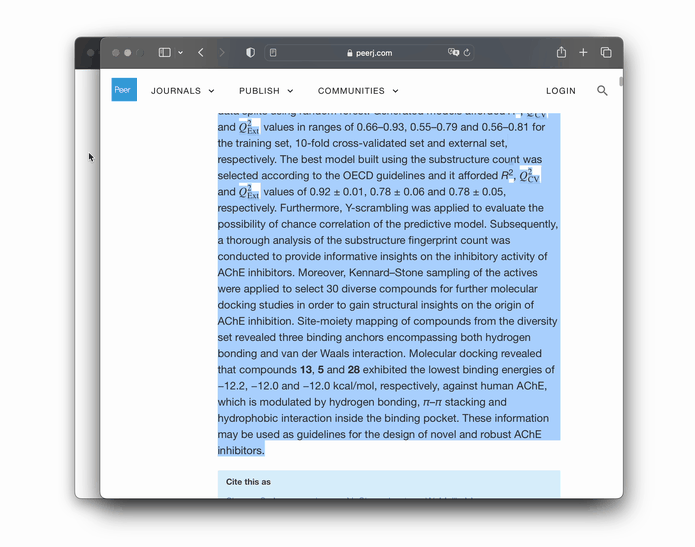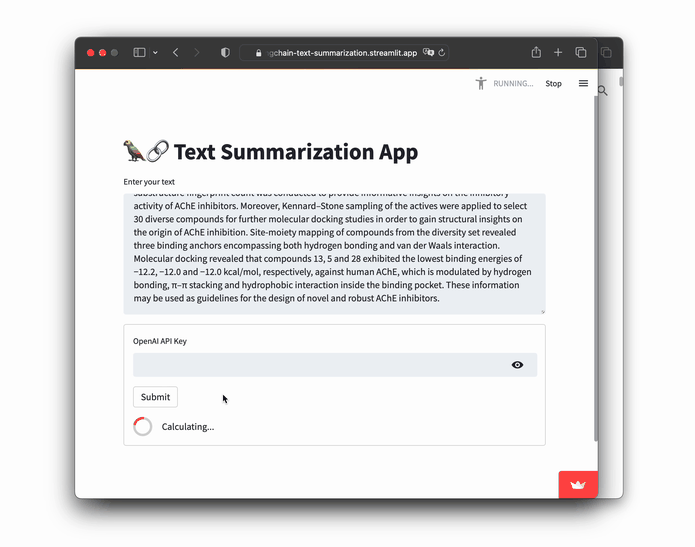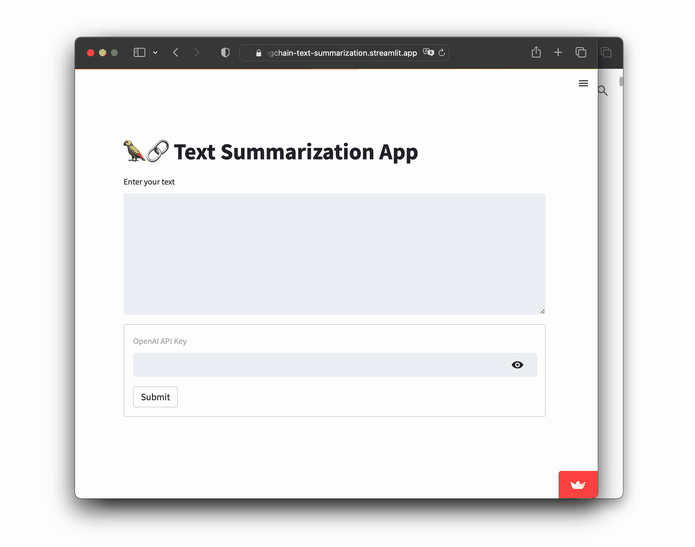
Here is the app in action:
Try it for yourself:
Now, let's get to building!
Step 1: Get an OpenAI API key
Read how to obtain an OpenAI API key in LangChain Tutorial #1.
Step 2: Set up the coding environment
Local development
To set up a local coding environment, ensure that you have Python version 3.7 or higher installed, then install the following Python libraries:
pip install streamlit langchain openai tiktoken
Cloud development
You can also set up your app on the cloud by deploying to the Streamlit Community Cloud. To get started, use this Streamlit app template (read more about it here).
Next, include the three prerequisite Python libraries in the requirements.txt file:
streamlit
langchain
openai
tiktoken
Step 3. Building the app
Code overview
Before diving deeper into the code walkthrough, let's take a high-level overview of the code. It can be implemented in just 38 lines:
import streamlit as st
from langchain import OpenAI
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
def generate_response(txt):
# Instantiate the LLM model
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
# Split text
text_splitter = CharacterTextSplitter()
texts = text_splitter.split_text(txt)
# Create multiple documents
docs = [Document(page_content=t) for t in texts]
# Text summarization
chain = load_summarize_chain(llm, chain_type='map_reduce')
return chain.run(docs)
# Page title
st.set_page_config(page_title='🦜🔗 Text Summarization App')
st.title('🦜🔗 Text Summarization App')
# Text input
txt_input = st.text_area('Enter your text', '', height=200)
# Form to accept user's text input for summarization
result = []
with st.form('summarize_form', clear_on_submit=True):
openai_api_key = st.text_input('OpenAI API Key', type = 'password', disabled=not txt_input)
submitted = st.form_submit_button('Submit')
if submitted and openai_api_key.startswith('sk-'):
with st.spinner('Calculating...'):
response = generate_response(txt_input)
result.append(response)
del openai_api_key
if len(result):
st.info(response)
Importing prerequisite libraries
As always, we'll start by importing the necessary libraries:
import streamlit as st
from langchain import OpenAI
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
AI-generated response
Next, we'll create a custom function generate_response(). It generates a response based on a given text input txt. For our use case, the input text will be the full text that needs to be summarized, and the output text will be the summarized version:
def generate_response(txt):
# Instantiate the LLM model
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
# Split text
text_splitter = CharacterTextSplitter()
texts = text_splitter.split_text(txt)
# Create multiple documents
docs = [Document(page_content=t) for t in texts]
# Text summarization
chain = load_summarize_chain(llm, chain_type='map_reduce')
return chain.run(docs)
This function performs four key tasks:
- It instantiates the LLM model, using the LLM model from OpenAI in this example. You can substitute this with any other LLM model of your choice. The API key is defined by the
open_api_keyparameter, which also takes in the OpenAI API key stored in theopenai_api_keyvariable specified by the user via thest.text_input()method (implemented later in a subsequent code block). - The text is then split using the
split_text()method fromCharacterTextSplitter(). - A document is created for each of the text splits using list comprehension (
[Document(page_content=t) for t in texts]). - The summarize chain (
load_summarize_chain()) is defined and assigned to thechainvariable, applied to the documents created above, and stored in thedocsvariable via therun()method.
App logic
Let's define the app elements.
First, we'll set the page title using st.set_page_config() and the in-app title using st.title():
# Page title
st.set_page_config(page_title='🦜🔗 Text Summarization App')
st.title('🦜🔗 Text Summarization App')
The app will accept text input via st.text_area()—assigned to the txt_input variable.
Before defining the form, we'll create an empty list called result to later store the AI-generated response.
In this tutorial, the form is slightly different from previous ones. We clear the API key text box using the clear_on_submit=True parameter after an AI-generated response has been successfully performed.
After the user clicks the Submit button, a Calculating... spinner is displayed. Once an AI-generated response is made, the results are stored in the result list created earlier. Then the API key is deleted, and the text output is printed via st.info(response):
# Text input
txt_input = st.text_area('Enter your text', '', height=200)
# Form to accept user's text input for summarization
result = []
with st.form('summarize_form', clear_on_submit=True):
openai_api_key = st.text_input('OpenAI API Key', type = 'password', disabled=not txt_input)
submitted = st.form_submit_button('Submit')
if submitted and openai_api_key.startswith('sk-'):
with st.spinner('Calculating...'):
response = generate_response(txt_input)
result.append(response)
del openai_api_key
if len(result):
st.info(response)
Note that in this tutorial, the app will clear any memory of the API key as an added security measure to prevent lingering memory of the key.
Step 4. Deploy the app
Once the app is created, it can be deployed in three simple steps:
- Create a GitHub repository for the app.
- Go to Streamlit Community Cloud, click on the
New appbutton, and select the repository, branch, and app file. - Click on the
Deploy!button.
That's it! Your app will be up and running in no time.
Wrapping up
You learned how to build a text summarization app using LangChain and Streamlit. It involved using Streamlit as the front-end to accept input text, processing it with LangChain and its associated LLM utility functions, and displaying the LLM-generated response.
For ideas and inspiration, check out the LLM gallery. I can't wait to see what you build. Please let me know in the comments below or contact me on Twitter at @thedataprof or on LinkedIn. You can also find me on the official Streamlit YouTube channel and my personal YouTube channel, Data Professor.
Happy Streamlit-ing! 🎈
P.S. This post was made possible thanks to the technical review by Mihal Nowotka and editing by Ksenia Anske.




Comments
Continue the conversation in our forums →