
In recent months, large language models (LLMs) have attracted widespread attention as they open up new opportunities, particularly for developers creating chatbots, personal assistants, and content.
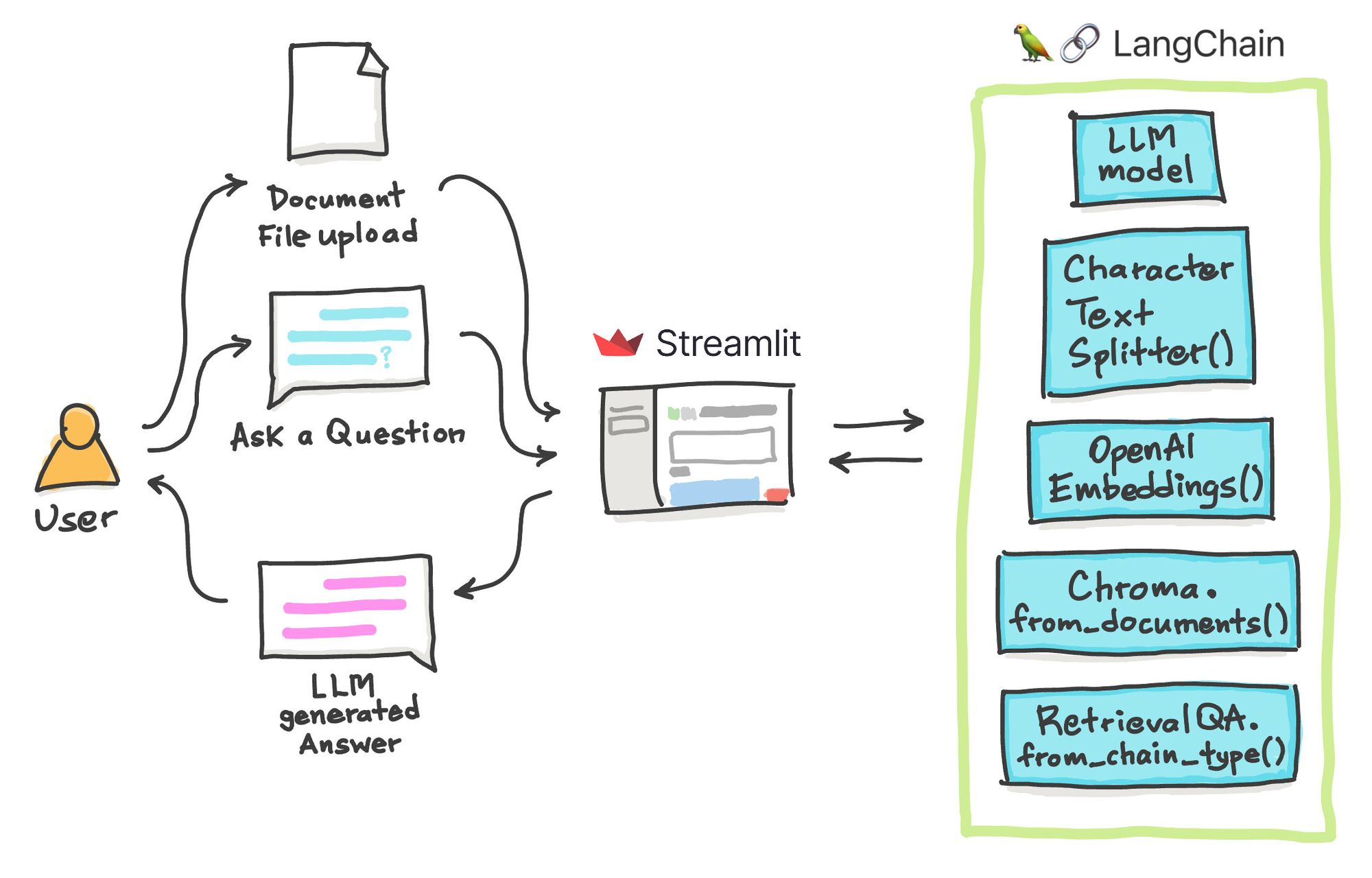
In the previous LangChain tutorials, you learned about three of the six key modules: model I/O (LLM model and prompt templates), data connection (document loader and text splitting), and chains (summarize chain).
In this tutorial, we'll explore how to use these modules, how to create embeddings and store them in a vector store, and how to use a specialized chain for question answering about a text document. We'll use these tools to build the Ask the Doc app in four steps:
- Get an OpenAI API key
- Set up the coding environment
- Build the app
- Deploy the app
What is document question-answering?
As the name implies, document question-answering answers questions about a specific document. This process involves two steps:
Step 1. Ingestion
The document is prepared through a process known as ingestion so that the LLM model can use it. Ingestion transforms it into an index, the most common being a vector store. The process involves:
- Loading the document
- Splitting the document
- Creating embeddings
- Storing the embeddings in a database (a vector store)
Step 2. Generation
With the index or vector store in place, you can use the formatted data to generate an answer by following these steps:
- Accept the user's question
- Identify the most relevant document for the question
- Pass the question and the document as input to the LLM to generate an answer
App overview
At a conceptual level, the app's workflow remains impressively simple:
- The user uploads a document text file, asks a question, provides an OpenAI API key, and clicks "Submit."
- LangChain processes the two input elements. First, it splits the input document into chunks, creates embedding vectors, and stores them in the embeddings database (i.e., the vector store). Then it applies the user-provided question to the Question Answering chain so that the LLM can answer the question:
Let's see the app in action.
Check out these materials if you want to follow along:
- Input file: state_of_the_union.txt
- Question: "What did the president say about Ketanji Brown Jackson?"
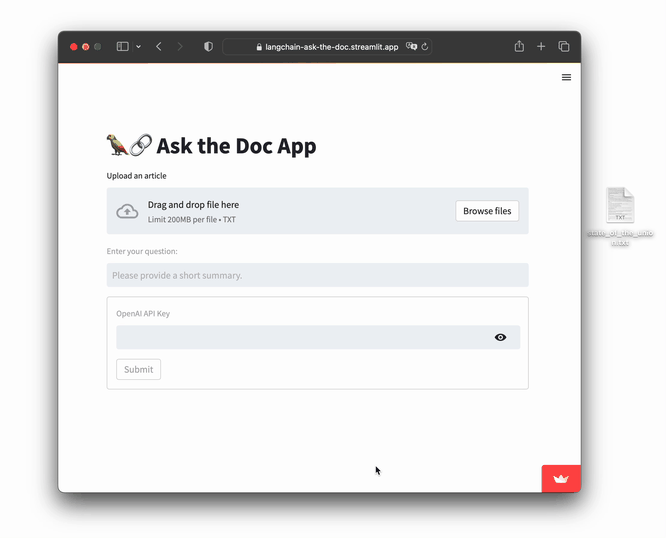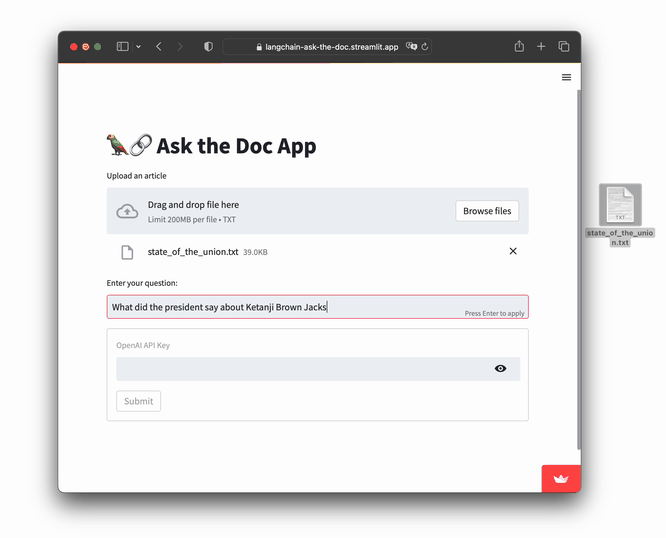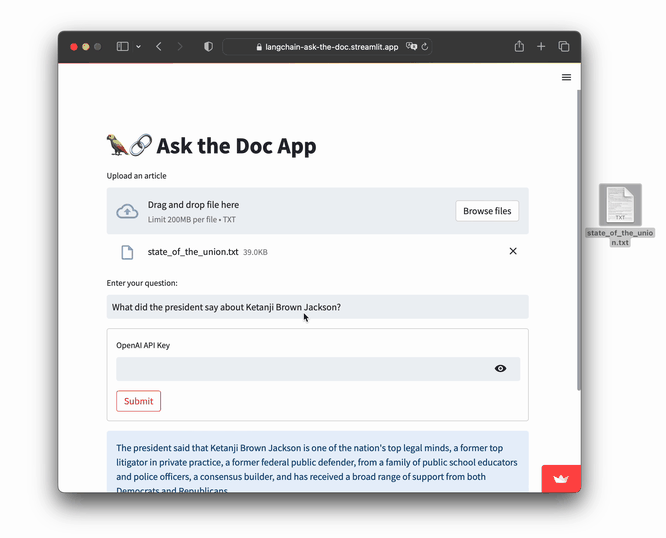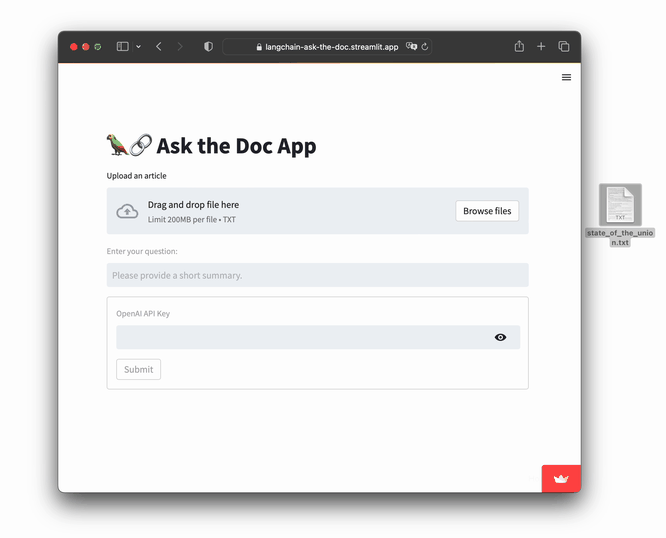
Go ahead and try it:
Step 1. Get an OpenAI API key
For a detailed walkthrough on getting an OpenAI API key, read LangChain Tutorial #1.
Step 2. Set up the coding environment
Local development
To set up a local coding environment, use pip install (make sure you have Python version 3.7 or higher):
pip install streamlit langchain openai tiktoken
Cloud development
You can deploy your app to the Streamlit Community Cloud using the Streamlit app template. (read more in the previous blog post).
To proceed, include the following prerequisite Python libraries in the requirements.txt file:
streamlit
langchain
openai
chromadb
tiktoken
Step 3. Build the app
The code for the app is only 46 lines, 10 of which are in-line documentation explaining what each code block does:
import streamlit as st
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
def generate_response(uploaded_file, openai_api_key, query_text):
# Load document if file is uploaded
if uploaded_file is not None:
documents = [uploaded_file.read().decode()]
# Split documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.create_documents(documents)
# Select embeddings
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Create a vectorstore from documents
db = Chroma.from_documents(texts, embeddings)
# Create retriever interface
retriever = db.as_retriever()
# Create QA chain
qa = RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key), chain_type='stuff', retriever=retriever)
return qa.run(query_text)
# Page title
st.set_page_config(page_title='🦜🔗 Ask the Doc App')
st.title('🦜🔗 Ask the Doc App')
# File upload
uploaded_file = st.file_uploader('Upload an article', type='txt')
# Query text
query_text = st.text_input('Enter your question:', placeholder = 'Please provide a short summary.', disabled=not uploaded_file)
# Form input and query
result = []
with st.form('myform', clear_on_submit=True):
openai_api_key = st.text_input('OpenAI API Key', type='password', disabled=not (uploaded_file and query_text))
submitted = st.form_submit_button('Submit', disabled=not(uploaded_file and query_text))
if submitted and openai_api_key.startswith('sk-'):
with st.spinner('Calculating...'):
response = generate_response(uploaded_file, openai_api_key, query_text)
result.append(response)
del openai_api_key
if len(result):
st.info(response)
Let's dissect the individual code blocks…
Import libraries
First, import the necessary libraries (primarily Streamlit and LangChain):
import streamlit as st
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
Create the LLM response generation function
Next, create the generate_response() custom function that contains the bulk of the LLM pipeline (the uploaded file is loaded as a text string).
Use these LangChain functions to preprocess the text:
OpenAI()loads the OpenAI LLM model.CharacterTextSplitter()splits documents into chunks.OpenAIEmbeddings()encodes the document chunks or strings of text as embeddings (a vector or list of floating point numbers). Distances amongst the embeddings provide a measure of relatedness that determines their similarity or difference. Embeddings are useful as they can be used for anomaly detection, classification, recommendations, search, topic clustering, etc.Chroma()is an open-source embedding database (also called a vector store—a database of embedding vectors). Particularly,Chroma.from_documents()is used for creating the vector store index using the document chunk after the text split and theOpenAIEmbeddings()function as input arguments.RetrievalQA()is the question-answering chain that takes as input arguments the LLM via thellmparameter, the chain type to use via thechain_typeparameter, and the retriever via theretrieverparameter.
Finally, the run() method is executed on the defined instance of RetrievalQA(), using the query text as the input argument:
def generate_response(uploaded_file, openai_api_key, query_text):
# Load document if file is uploaded
if uploaded_file is not None:
documents = [uploaded_file.read().decode()]
# Split documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.create_documents(documents)
# Select embeddings
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Create a vectorstore from documents
db = Chroma.from_documents(texts, embeddings)
# Create retriever interface
retriever = db.as_retriever()
# Create QA chain
qa = RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key), chain_type='stuff', retriever=retriever)
return qa.run(query_text)
Define the web app frontend
Use the page_title parameter in the st.set_page_config() method to give the app a title (displayed in the browser).
Display the in-app title using st.title():
# Page title
st.set_page_config(page_title='🦜🔗 Ask the Doc App')
st.title('🦜🔗 Ask the Doc App')
Next, add input widgets that allow users to upload text files using st.file_uploader() and to ask questions about the uploaded text document using st.text_input():
# File upload
uploaded_file = st.file_uploader('Upload an article', type='txt')
# Query text
query_text = st.text_input('Enter your question:', placeholder = 'Please provide a short summary.', disabled=not uploaded_file)
After the user has provided the above two inputs, the form will unlock the ability to enter the OpenAI API key via st.text_input().
After you enter the OpenAI API key and click on Submit, you'll see a spinner element displaying the message Calculating.... This triggers the generate_response() function, which generates the LLM's answer to the user's question.
Once it's been generated, the API key is deleted to ensure API safety:
# Form input and query
result = []
with st.form('myform', clear_on_submit=True):
openai_api_key = st.text_input('OpenAI API Key', type='password', disabled=not (uploaded_file and query_text))
submitted = st.form_submit_button('Submit', disabled=not(uploaded_file and query_text))
if submitted and openai_api_key.startswith('sk-'):
with st.spinner('Calculating...'):
response = generate_response(uploaded_file, openai_api_key, query_text)
result.append(response)
del openai_api_key
if len(result):
st.info(response)
An empty list called result is defined before the form. This is followed by an if statement that displays the LLM-generated response when the result list is populated with it. This approach allows the API key to be deleted after an LLM-generated response is created.
result list.Step 4. Deploy the app
After creating the app, you can launch it in three steps:
- Establish a GitHub repository specifically for the app.
- Navigate to Streamlit Community Cloud, click the
New appbutton, and choose the appropriate repository, branch, and application file. - Finally, hit the
Deploy!button.
Your app will be live in no time!
Wrapping up
In this article, you've learned how to create the Ask the Doc app that facilitates question-answering about a user-uploaded text document. In other words, you prepared the document for ingestion to be used by the LLM for generating an answer to the user's question. I can't wait to see what you'll build!
If you're looking for ideas and inspiration, check out the LLM gallery. And if you have any questions, let me know in the comments below, or find me on Twitter at @thedataprof, on LinkedIn, on the Streamlit YouTube channel, or my personal YouTube channel Data Professor.
Happy Streamlit-ing! 🎈
P.S. This post was made possible thanks to the technical review by Tim Conkling and editing by Ksenia Anske.




Comments
Continue the conversation in our forums →