
Hey, community! 👋
I'm Alice, a student from Sweden passionate about using technology. AI excites me because it can enhance human creativity, find otherwise undetected patterns, and create personalized learning tools.

As a ham radio operator, I wanted to learn Morse code to communicate with other operators worldwide. Because in times of crisis, traditional radio can be an alternative channel for critical information. But I had only old audio Morse recordings with exercises that took forever to check manually, and I wanted a more fun and engaging way to learn it.
So…I built a Streamlit app! It's an interactive Morse tutor with 15 levels, five checkpoints, and memorable mnemonics that helped me transmit words and phrases from the first week.
Morse code was developed in the 1800s, but it's still relevant for signaling and identification and is often used in capture-the-flag events (CTFs), escape rooms, and puzzles!
In this post, I'll show you how to create it in five steps:
- Step 1. What is Morse code anyway?
- Step 2. Sound module
- Step 3. Game module
- Step 4. Levels
- Step 5. Checkpoints and Playground
Step 1. What is Morse code anyway?
The Morse alphabet associates each letter with a sequence of short and long pulses called "dots" and "dashes." But how do you choose which letter gets which sequence? It's far from random. If you think about it, you'd probably want to reserve the shorter sequences for the most common letters.
The International Morse code table looks like this:

If we analyze the frequency of the English letters, that is how many times a letter is used on average, we get the following graph:
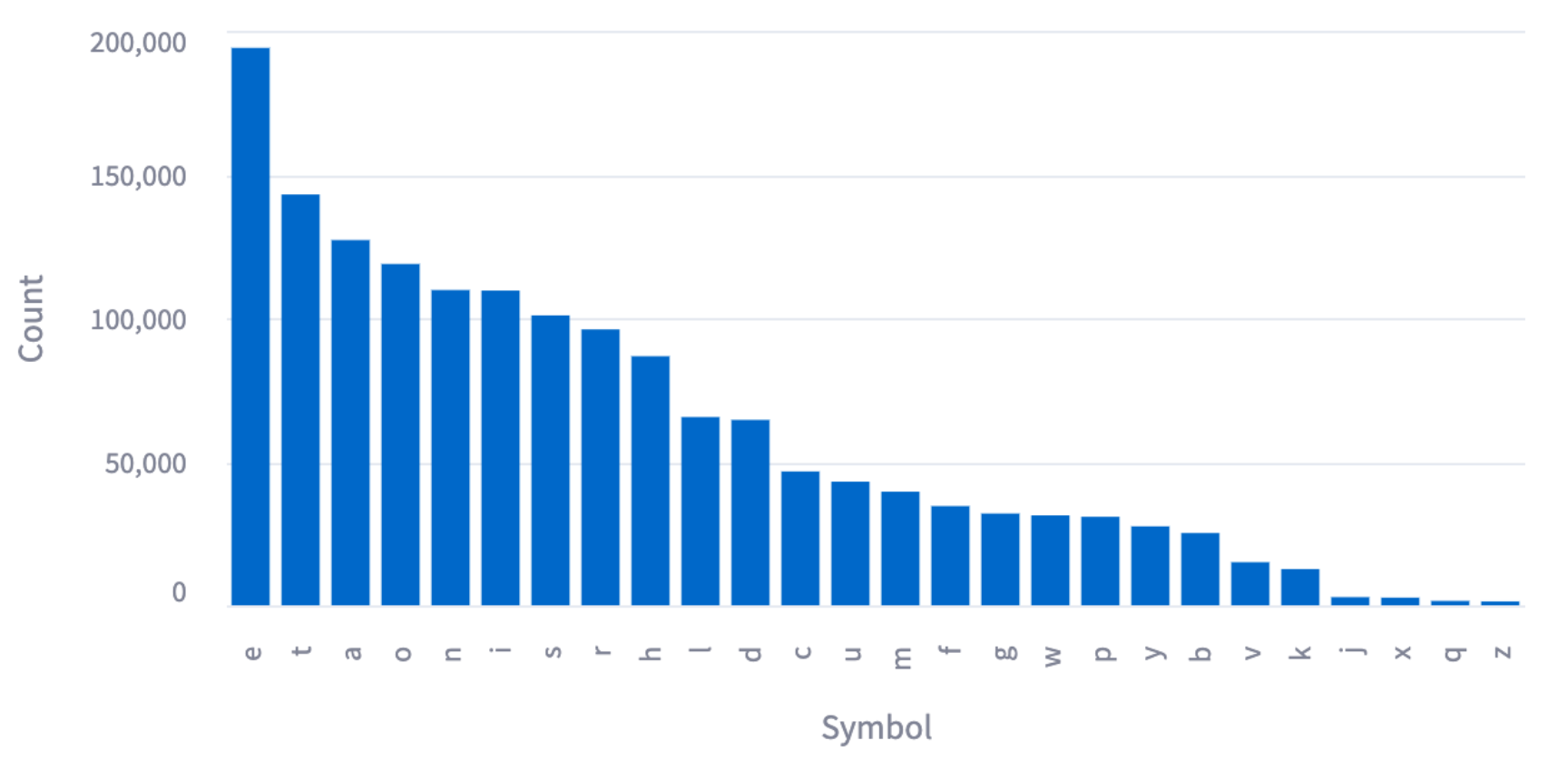
Notice that the most common letters, "e t a o n," have the shortest sequences.
Armed with these insights, we can tailor our training to focus on the most commonly used letters and words to make the most of limited time.
Let's get coding!
Step 2. Sound module
The most important module is the creation of Morse audio sequences. To do this, we need to understand pulse timing. In Morse, we make the shortest pulse one unit and define all other lengths relative to it:
- Short pulse: 1 unit
- Long pulse: 3 units
- Intraletter spacing: 1 unit
- Interletter spacing: 3 units
- Interword spacing: 7 units
For example, the word “PARIS” becomes “• - - • • - • - • • • • • •”, with a total of 50 units ($10\text{ short} \cdot 1\text{ unit} + 4\text{ long} \cdot 3\text{ units} + 9\text{ intraletter} \cdot 1\text{ unit} + 4\text{ interletter} \cdot 3\text{ units} + 1\text{ interword} \cdot 7\text{ units} = 50\text{ units}$):
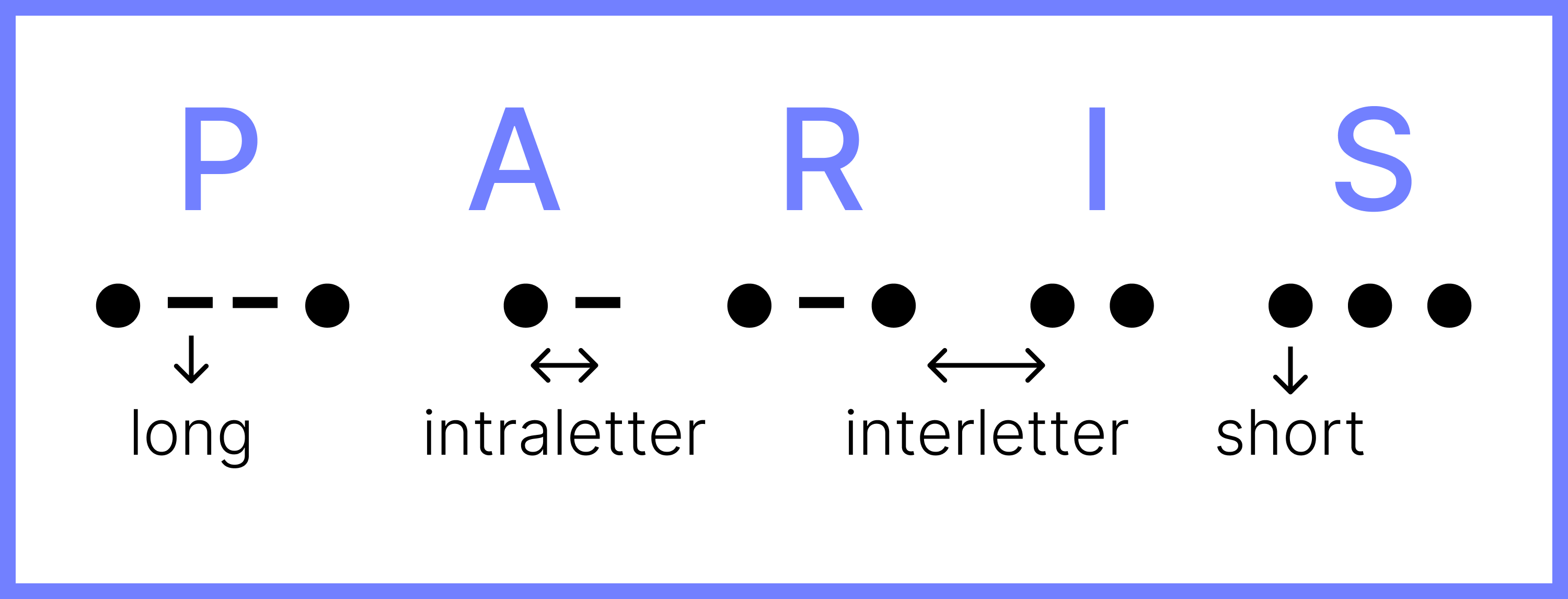
When practicing Morse code, the goal is not to memorize the sequences of letters but to imprint their auditory patterns.
So we want to keep the speed of the letter sequences high, but we can increase the spacing between letters and words to create a slower beginner pace. To do this, we use something called Farnsworth timing. It allows us to "warp" a higher word-per-minute speed to a lower one just by lengthening the pauses. This article explains the mathematics behind the formulas used to make this transformation.
Here is the code:
class SoundCreator:
def __init__(self, character_speed=22, farnsworth_speed=8, sample_rate=44100.0):
self.sample_rate = sample_rate
self.character_speed = character_speed
self.farnsworth_speed = farnsworth_speed
# Compute timings
u = 1.2 / character_speed
ta = (60 * character_speed - 37.2 * farnsworth_speed) / (farnsworth_speed * character_speed)
tc = (3 * ta) / 19
tw = (7 * ta) / 19
# Convert to milliseconds
self.dot_length = round(u * 1000)
self.dash_length = round(u * 3 * 1000)
self.intra_character_space = round(u * 1000)
self.inter_character_space = round(tc * 1000)
self.inter_word_space = round(tw * 1000)
# Initialize audio array
self.audio = []
self.morse_dict = {k: l[1].replace("▄▄", "-").replace("▄", "*").replace(" ", "") for k, l in mnemonics.items()}
We generate an audio sample by constructing an array of tone data. Zeros represent silence, while our tone is calculated by a formula based on our desired duration, volume, sample rate, and frequency:
def _append_silence(self, duration_ms=500):
"""Adding silence by appending zeros."""
num_samples = duration_ms * (self.sample_rate / 1000.0)
for _ in range(int(num_samples)):
self.audio.append(0.0)
def _append_sinewave(self, freq=550.0, duration_ms=500, volume=0.2):
"""Appends a beep of length duration_ms"""
num_samples = duration_ms * (self.sample_rate / 1000.0)
for x in range(int(num_samples)):
self.audio.append(volume * math.sin(2 * math.pi * freq * (x / self.sample_rate)))
With the general audio functions complete, we can construct a function that turns any character string into a playable Morse code audio snippet.
Here is the code that does just that:
def create_audio_from(self, sequence: str, start_delay_ms=None):
"""Takes a strings sequence and transforms it into a playable Morse audio clip.
Args:
sequence (str): Message to be enconded into Morse Code.
Returns:
np_array: audio data for an audio player.
"""
# reset audio array
self.audio = []
# Add silence at beginning
if start_delay_ms:
self._append_silence(duration_ms=start_delay_ms)
for character in sequence:
character = character.upper()
if character in self.morse_dict:
morse_encoding = self.morse_dict[character]
for i, symbol in enumerate(morse_encoding):
if symbol == "*":
# Short sound
self._append_sinewave(duration_ms=self.dot_length)
elif symbol == "-":
# Long sound:
self._append_sinewave(duration_ms=self.dash_length)
if i + 1 < len(morse_encoding):
self._append_silence(duration_ms=self.intra_character_space)
# Add inter-character spacing
self._append_silence(duration_ms=self.inter_character_space)
if character == " ":
# Add inter-word spacing
self._append_silence(duration_ms=self.inter_word_space)
return np.array(self.audio)
The functions take the following inputs:
sequenceis a string message, such as "Hey," encoded in Morse code.start_delayadds silence to the audio clip's beginning to allow the user to prepare after pressing play.
The function returns an audio array containing audio data that can be played by Streamlit's audio player.
Step 3. Game module
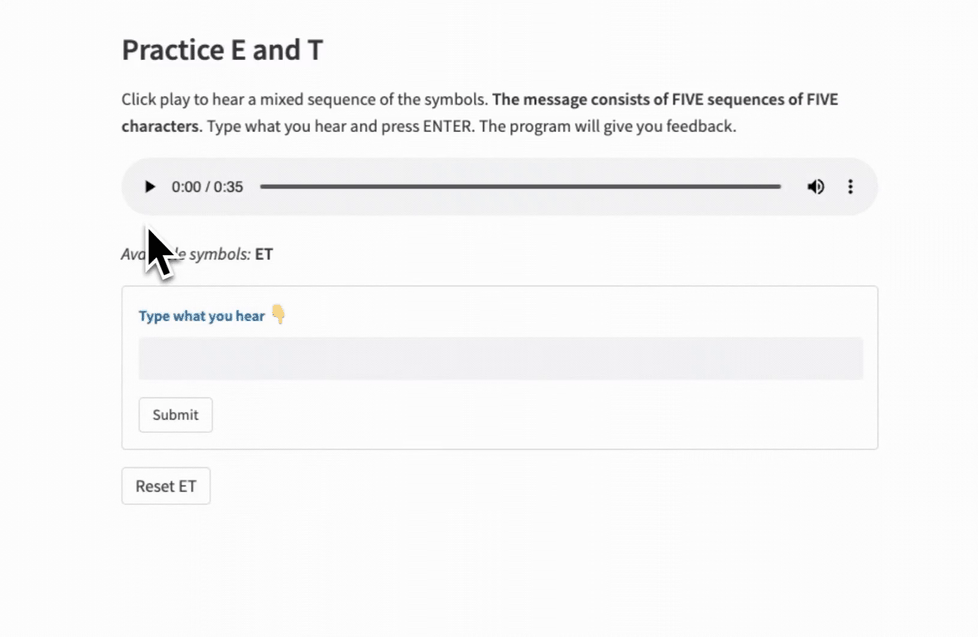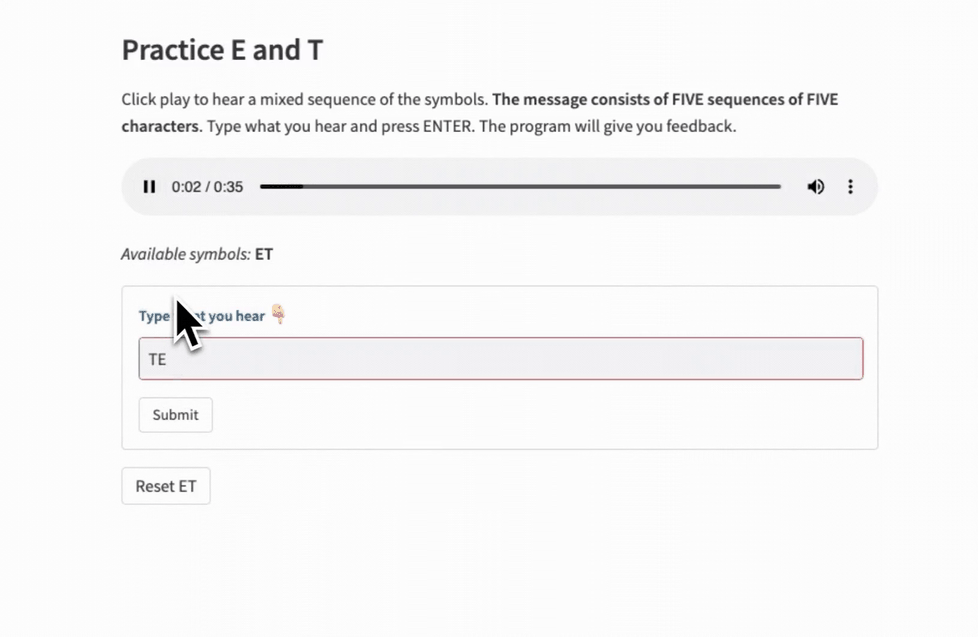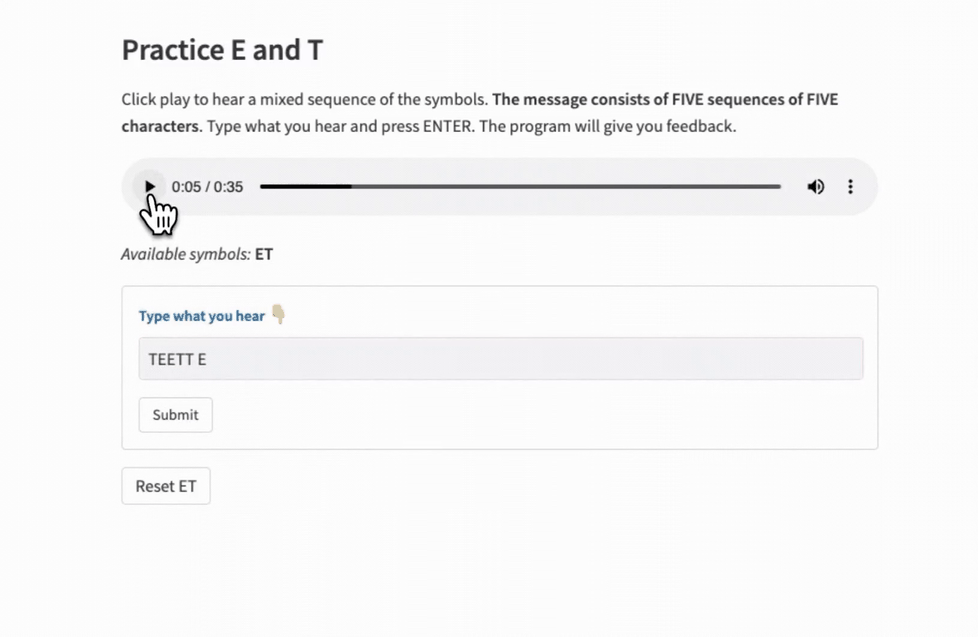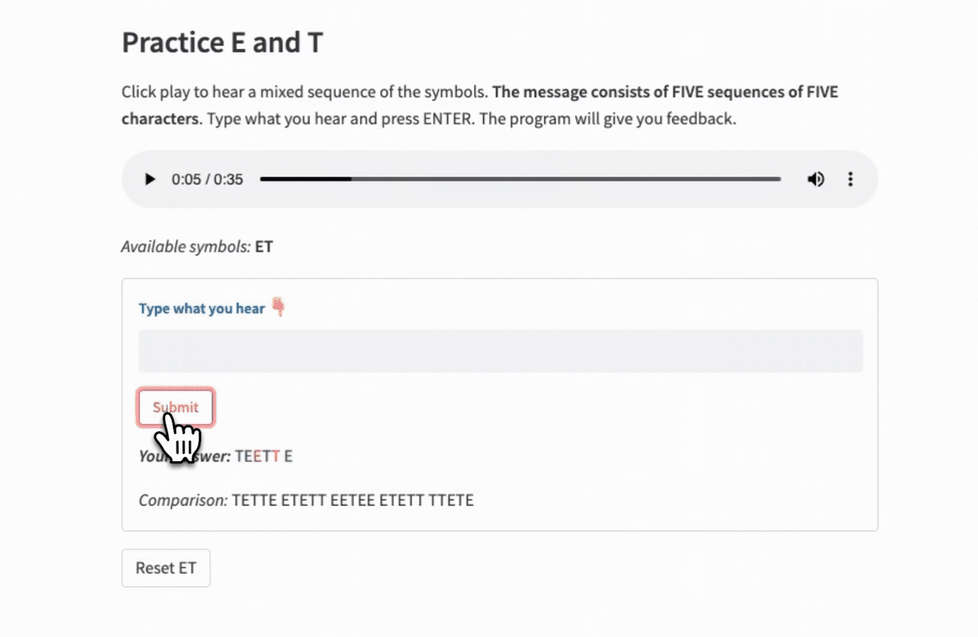
The Game Module handles the component that implements the interactive quizzing. Here is the class declaration:
class GameCreator:
def __init__(self, label, symbols):
self.label = label
self.symbols = symbols
self.anagrams = None
self.quotes = None
The Game Modules generate character sequences, and 2) accept and correct user input. I created two main functions to generate these sequences. One generates random groups in the defined character set. The other finds possible anagrams of a set of symbols and assembles them into word sequences.
Here is the code for it:
def generate_sequence(self, length_unit: int, num_units: int):
"""Creates a random letter sequence of *length_unit* chunks, *num_unit* times."""
seq = []
for _ in range(num_units):
seq.append("".join(random.choices(self.symbols, k=length_unit)))
return " ".join(seq)
def generate_anagrams(self, filename):
"""Find all possible words with the current symbol set. (self.symbols)"""
# Step 1: Read words from the file line by line
with open(filename, "r") as f:
words = f.read().split("\\n")
# Step 2: Get all anagrams
anagrams = []
symbol_set = set(self.symbols.lower())
for word in words:
word_set = set(word.lower())
if word_set.issubset(symbol_set):
if word.upper() not in anagrams:
anagrams.append(word.upper())
# Step 3: Save and return the list of anagrams
self.anagrams = anagrams
return anagrams
def generate_word_sequence(self, num_words: int):
"""Assemble possible words into a word sequence."""
words = random.choices(self.anagrams, k=num_words)
return " ".join(words)
In the final version, I extended this to include quotes and news summaries. You can create functions to generate any kind of practice text!
The "Typer" function acts as a reusable component with an audio player, instruction text, input field, and interactive feedback:
def Typer(self):
"""Component with instructions, audio player, user input, and correction."""
message = self.get_message()
formatted_symbols = "".join(list(self.symbols)).strip()
st.markdown(f"*Available symbols:* **{formatted_symbols}**")
with st.form(key=self.label, clear_on_submit=True):
user_input = st.text_input("**:blue[Type what you hear] 👇**")
if st.form_submit_button("Submit"):
user_input = user_input.upper()
answer = message.upper()
output = ""
for i in range(len(user_input)):
if i >= len(answer):
output += f":red[{user_input[i:]}]"
break
if user_input[i] == answer[i]:
output += f":green[{user_input[i]}]" if user_input[i] != " " else " "
else:
output += f":red[{user_input[i]}]" if user_input[i] != " " else " "
st.markdown(f"***Your Answer:*** {output}")
st.markdown(f"*Comparison:* {answer}")
self.reset_message()
reset = st.button(f"Reset {self.label}")
if reset:
self.reset_message()
st.experimental_rerun()
My three biggest takeaways from this application are:
- Functions can act like components. Call the function anywhere you want a copy of it. It's a cheap way to bundle Streamlit components into a package.
- Use
:color[your text here]and replacecolorto create colored text. - If you want to keep information between reloads, you must cache it.
The trickiest part was establishing persistence because Streamlit reloads the page when input is passed. To keep a piece of data and not generate a new one every time, we need to store it in the st.session_state. For this project, it's necessary to compare what the user enters and the correct sequence after the input is submitted.
I solved this problem by adding the following functions:
def initalize_message(self, sequence):
if "sequence" not in st.session_state:
st.session_state.sequence = ""
if st.session_state.sequence == "":
st.session_state.sequence = sequence
def get_message(self):
return st.session_state.sequence
def reset_message(self):
st.session_state.sequence = ""
initalize_messagecreates a new key-value pair to store the generated sequence asst.session_state.sequence.get_messagegets the current sequence stored in the session state.reset_messageclears the session state.
Step 4. Levels
I quickly realized that I was structuring all the levels in a similar way:
- Introduction to two new symbols: their Morse code and mnemonics.
- Audio example of each symbol separately.
- An audio sample of the symbols used together showing the plaintext solution.
- A practice sequence using only the new symbols.
- A practice sequence of all the symbols learned.
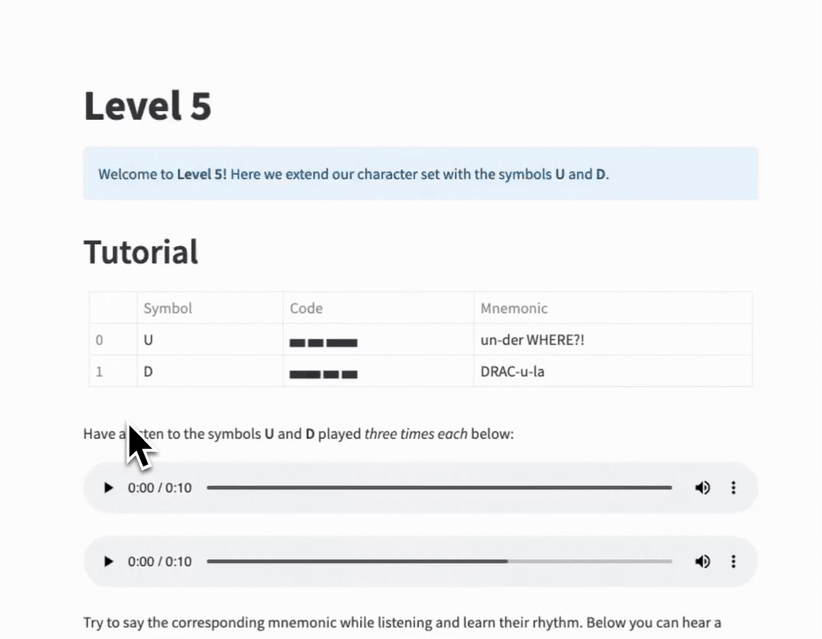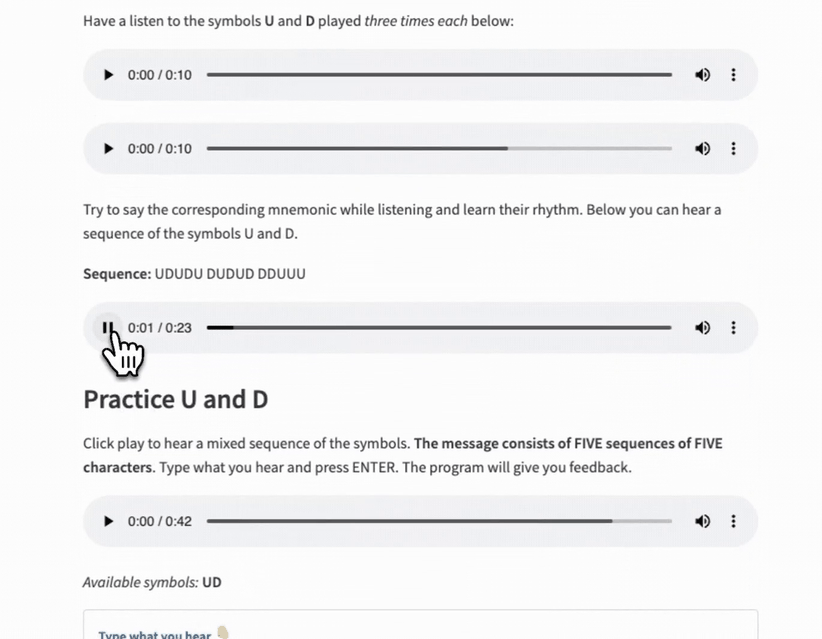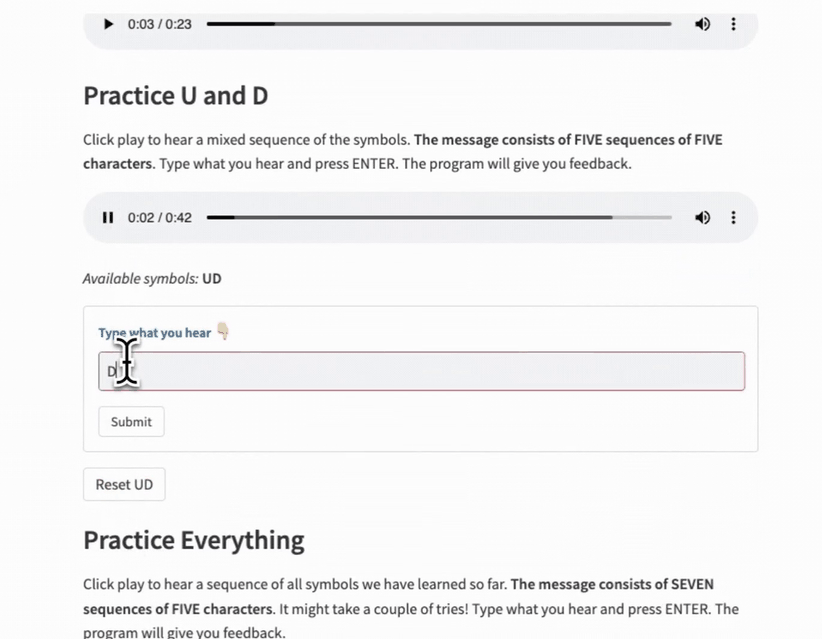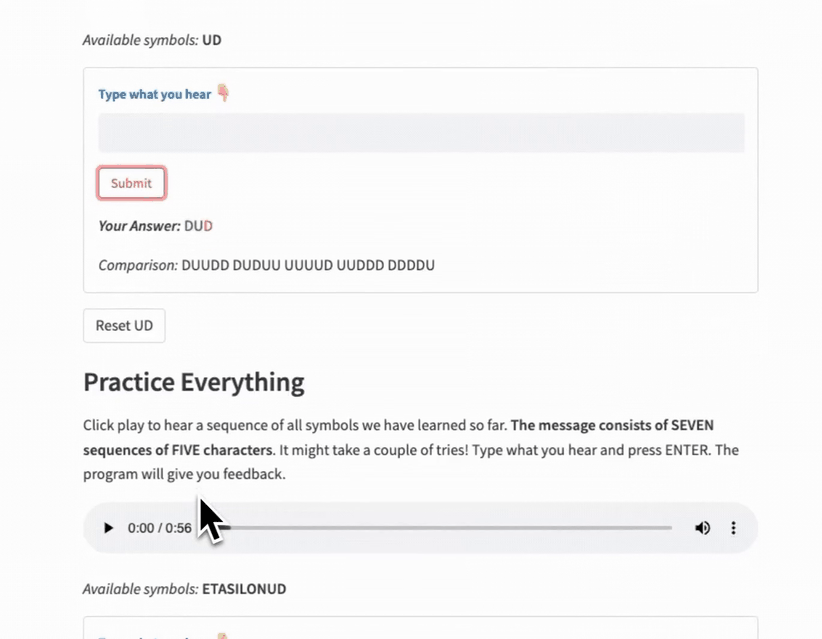
Instead of copying and pasting, I created a template file with a configuration dictionary as input. Then I could import this file, specify the parameters in each level file, and call the template function.
Here is an example from level five:
from template import *
# Configuration
level = {
"level": "Level 5",
"new_symbols": "UD",
"new_label": "UD",
"all_label": "ETASILONUD",
"length_unit": 5,
"num_units_tutorial": 5,
"num_units_all": 7,
}
generate_level(level)
So if I want to change something on all levels, I only have to change it in one place!
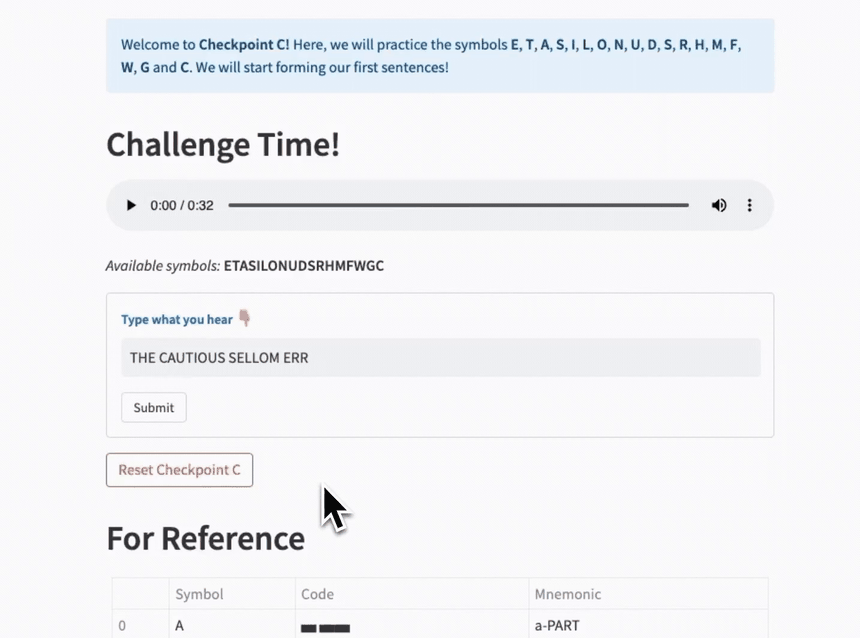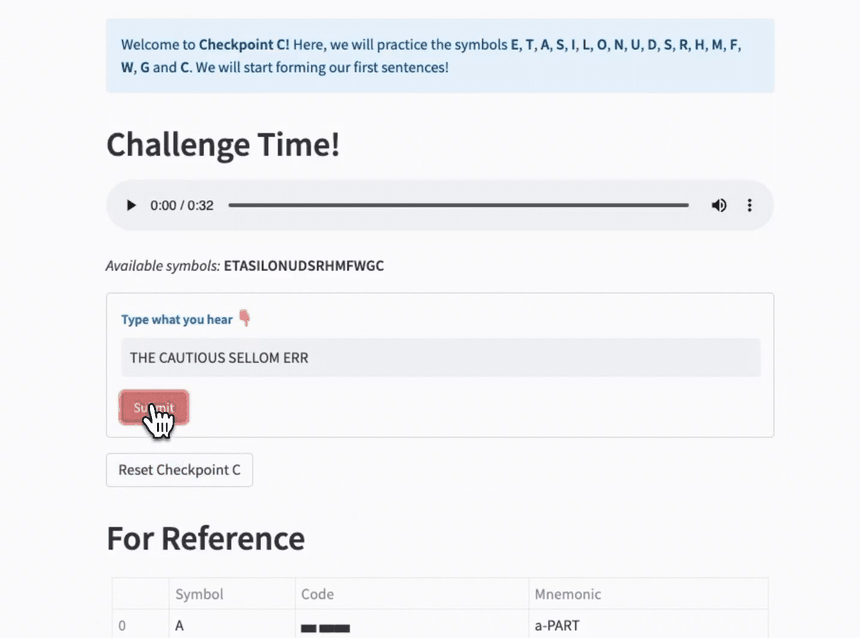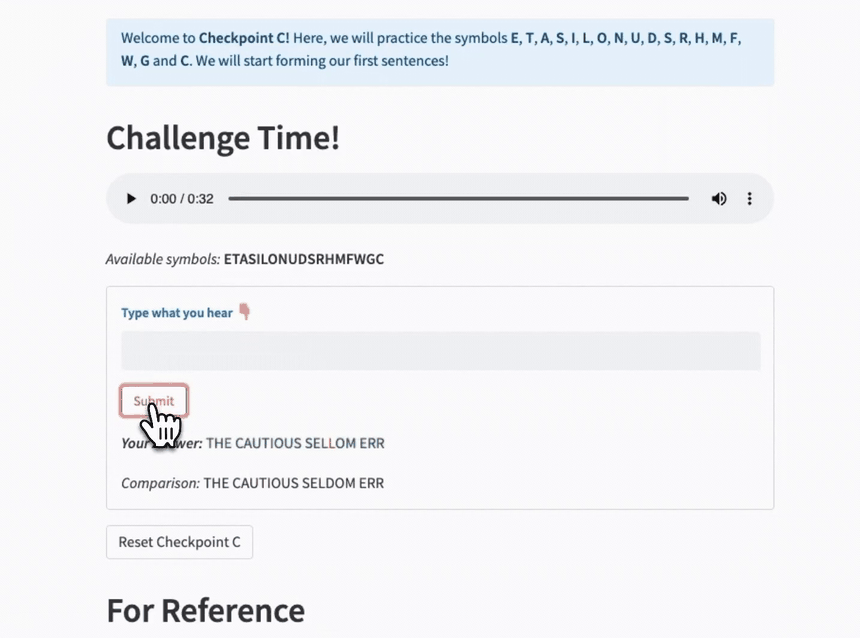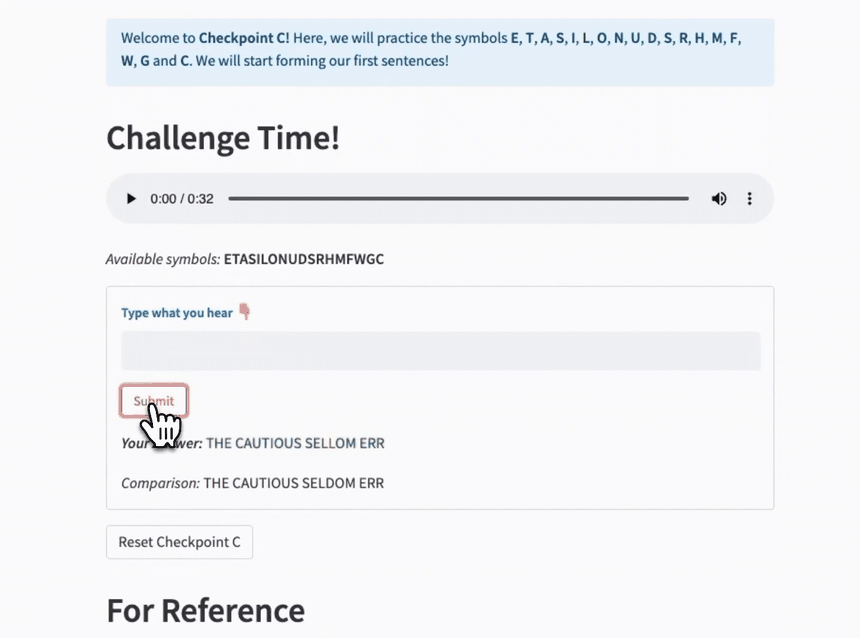
Step 5. Checkpoints and Playground
The purpose of the checkpoints is to make practicing more fun and to get a sense of progress.
I downloaded a list of English words and inspirational quotes. Then I created an algorithm that calculated the order in which to learn all the characters to form the maximum number of sentences from the start.
In this version, a checkpoint has two variations:
WORDS, where you practice random word sequences without grammatical structure. These are generated from thegenerate_anagramsandgenerate_word_sequencefunctions of the game module explained earlier.QUOTES, where a random quote is chosen from a list based on the current known symbol set.
Each challenge ends with a reference to the characters of the levels leading up to the current checkpoint.
I created the Playground to let you freely enter your messages, experiment with speeds, and even get daily news snippets to practice on! I chose "Nature Daily Briefing," but you can customize it to whatever text sources you like best!
Wrapping up
Thanks for reading! The great thing about Morse is its simplicity. Any two things that look, feel, or sound different can carry information. In this post, I showed you how to create playable audio samples with arrays, wrap Streamlit components into functions, cache data between reloads, and create template files to generate pages with similar functionality.
If you have any questions, please leave them in the comments below, contact me on Twitter or email me.
Happy Streamlit-ing! 🎈
Appendix: Complete Morse code
Here is the complete Morse code symbol table used for this project (it gives the character, its Morse equivalent, and a mnemonic to remember its sequence):
mnemonics = {
"A": ("A", "▄ ▄▄", "a-PART"),
"B": ("B", "▄▄ ▄ ▄ ▄", "BOB is the man"),
"C": ("C", "▄▄ ▄ ▄▄ ▄", "CO-ca CO-la"),
"D": ("D", "▄▄ ▄ ▄", "DRAC-u-la"),
"E": ("E", "▄", "Eh?!"),
"F": ("F", "▄ ▄ ▄▄ ▄", "Fi-tti-PAL-di"),
"G": ("G", "▄▄ ▄▄ ▄", "GOOD GRAV-y"),
"H": ("H", "▄ ▄ ▄ ▄", "hip-pi-ty hop"),
"I": ("I", "▄ ▄", "did it"),
"J": ("J", "▄ ▄▄ ▄▄ ▄▄", "in JAWS JAWS JAW"),
"K": ("K", "▄▄ ▄ ▄▄", "KAN-dy KID"),
"L": ("L", "▄ ▄▄ ▄ ▄", "los AN-ge-les"),
"M": ("M", "▄▄ ▄▄", "MA-MA"),
"N": ("N", "▄▄ ▄", "NAV-y"),
"O": ("O", "▄▄ ▄▄ ▄▄", "HO HO HO"),
"P": ("P", "▄ ▄▄ ▄▄ ▄", "a PIZ-ZA pie"),
"Q": ("Q", "▄▄ ▄▄ ▄ ▄▄", "GOD SAVE the QUEEN"),
"R": ("R", "▄ ▄▄ ▄", "a RABB-it"),
"S": ("S", "▄ ▄ ▄", "sí-sí-sí"),
"T": ("T", "▄▄", "TALL"),
"U": ("U", "▄ ▄ ▄▄", "un-der WHERE?!"),
"V": ("V", "▄ ▄ ▄ ▄▄", "vic-tor-y VEE"),
"W": ("W", "▄ ▄▄ ▄▄", "the WORLD WAR"),
"X": ("X", "▄▄ ▄ ▄ ▄▄", "CROSS at the DOOR"),
"Y": ("Y", "▄▄ ▄ ▄▄ ▄▄", "YELL-ow YO-YO"),
"Z": ("Z", "▄▄ ▄▄ ▄ ▄", "ZU-ZU pe-tal"),
"0": ("0", "▄▄ ▄▄ ▄▄ ▄▄ ▄▄", ""),
"1": ("1", "▄ ▄▄ ▄▄ ▄▄ ▄▄", ""),
"2": ("2", "▄ ▄ ▄▄ ▄▄ ▄▄", ""),
"3": ("3", "▄ ▄ ▄ ▄▄ ▄▄", ""),
"4": ("4", "▄ ▄ ▄ ▄ ▄▄", ""),
"5": ("5", "▄ ▄ ▄ ▄ ▄", ""),
"6": ("6", "▄▄ ▄ ▄ ▄ ▄", ""),
"7": ("7", "▄▄ ▄▄ ▄ ▄ ▄", ""),
"8": ("8", "▄▄ ▄▄ ▄▄ ▄ ▄", ""),
"9": ("9", "▄▄ ▄▄ ▄▄ ▄▄ ▄", ""),
".": (".", "▄ ▄▄ ▄ ▄▄ ▄ ▄▄", "a STOP a STOP a STOP"),
",": (",", "▄▄ ▄▄ ▄ ▄ ▄▄ ▄▄", "COM-MA, it's a COM-MA"),
"?": ("?", "▄ ▄ ▄▄ ▄▄ ▄ ▄", "it's a QUES-TION, is it?"),
":": (":", "▄▄ ▄▄ ▄▄ ▄ ▄ ▄", "HA-WA-II stan-dard time"),
"/": ("/", "▄▄ ▄ ▄ ▄▄ ▄", "SHAVE and a HAIR-cut"),
'"': ('"', "▄ ▄▄ ▄ ▄ ▄▄ ▄", "six-TY-six nine-TY-nine"),
"'": ("'", "▄ ▄▄ ▄▄ ▄▄ ▄▄ ▄", "and THIS STUFF GOES TO me"),
";": (";", "▄▄ ▄ ▄▄ ▄ ▄▄ ▄", ""),
"=": ("=", "▄▄ ▄ ▄ ▄ ▄▄", ""),
"+": ("+", "▄ ▄▄ ▄ ▄▄ ▄", ""),
"-": ("-", "▄▄ ▄ ▄ ▄ ▄ ▄▄", ""),
}




Comments
Continue the conversation in our forums →