
Hello, community! 👋
My name is Mısra Turp, and I work as a developer educator at AssemblyAI.
We partner with YouTube creators to make helpful content for the AI community. Our creators make videos about technology, AI, deep learning, and machine learning. We screen the videos for sensitive or harmful content, which can take a long time. So I made an AI-powered app that can analyze video content automatically (yay!).

In this post, I'll share with you how to build and use the content analyzer app step-by-step:
- Create an AssemblyAI account
- Collect user input with Streamlit
- Submit the video to AssemblyAI for analysis
- Receive analysis results from AssemblyAI
- Present analysis results in 3 sections: summary, topics, sensitive content
But before we start, let's talk about...
What's a content analyzer app?
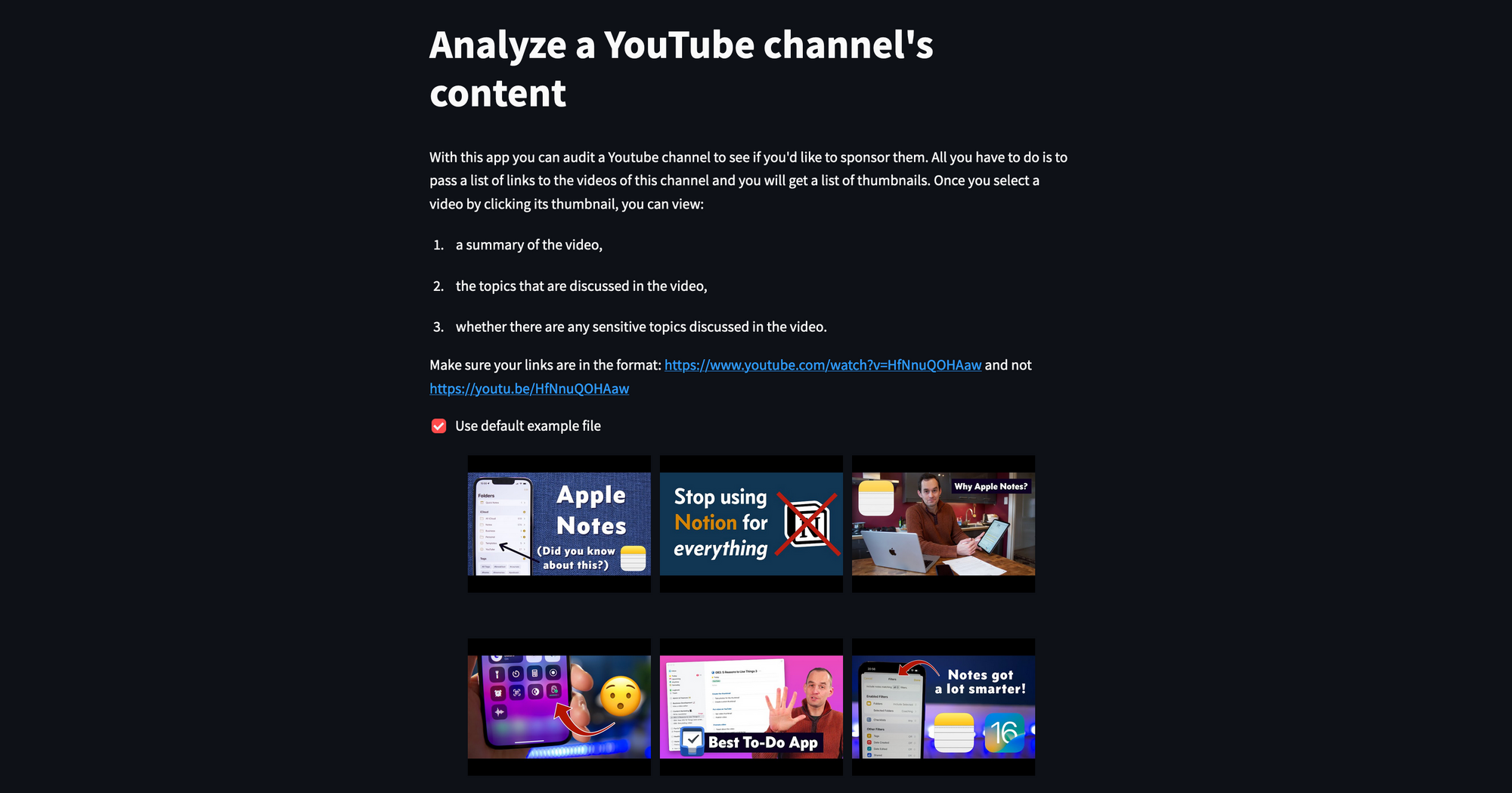
The content analyzer app helps you evaluate the videos of a given channel very quickly. Given a list of videos in a TXT file, the app gives the user the option to select a video to analyze by visualizing the video's thumbnails:
Once a video is selected, the app reports a summary of the video, a list of sensitive topics (if any), and all the topics that were discussed:

Step 1. Create an AssemblyAI account
To start, create a free AssemblyAI account and get a Free API key. Then install Streamlit, pandas, requests, and pytube Python libraries:
pip install streamlit
pip install pandas
pip install requests
pip install pytube
Step 2. Collect user input
Next, build the skeleton of the Streamlit app by including instructions and headlines:
import streamlit as st
st.title("Analyze a YouTube channel's content")
st.markdown("With this app you can audit a Youtube channel to see if you'd like to sponsor them. All you have to do is to pass a list of links to the videos of this channel and you will get a list of thumbnails. Once you select a video by clicking its thumbnail, you can view:")
st.markdown("1. a summary of the video,")
st.markdown("2. the topics that are discussed in the video,")
st.markdown("3. whether there are any sensitive topics discussed in the video.")
st.markdown("Make sure your links are in the format: <https://www.youtube.com/watch?v=HfNnuQOHAaw> and not <https://youtu.be/HfNnuQOHAaw>")
Now you need a list of URLs from the user. They can upload it through the Streamlit file_uploader. If the user doesn't have anything yet and wants to play around with the app, they can select a checkbox to use a default TXT file:
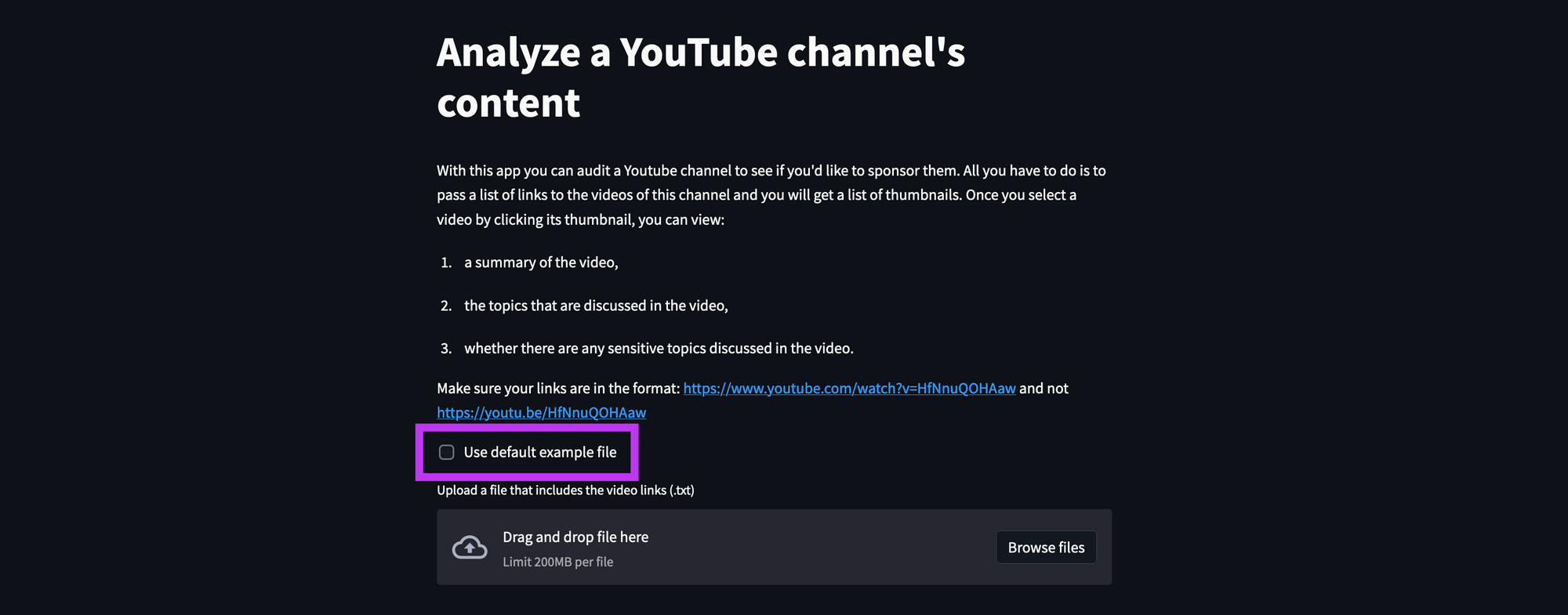
default_bool = st.checkbox('Use default example file', )
if default_bool:
file = open('./links.txt')
else:
file = st.file_uploader('Upload a file that includes the video links (.txt)')
Next, download the audio of this video from YouTube by casting the given TXT file into a Python list and passing each URL through a function called save_audio:
if file is not None:
print(file)
dataframe = pd.read_csv(file, header=None)
dataframe.columns = ['video_url']
urls_list = dataframe["video_url"].tolist()
titles = []
locations = []
thumbnails = []
for video_url in urls_list:
video_title, save_location, thumbnail_url = save_audio(video_url)
titles.append(video_title)
locations.append(save_location)
thumbnails.append(thumbnail_url)
# ... (continued if file is not None:)
This function returns the video title, the location where the audio is saved, and the thumbnail. The information is saved in separate lists:
from pytube import YouTube
import os
@st.experimental_memo
def save_audio(url):
yt = YouTube(url)
video = yt.streams.filter(only_audio=True).first()
out_file = video.download()
base, ext = os.path.splitext(out_file)
file_name = base + '.mp3'
os.rename(out_file, file_name)
print(yt.title + " has been successfully downloaded.")
print(file_name)
return yt.title, file_name, yt.thumbnail_url
Now that you have the information on every video, you can display it in a grid for the user to select one. There is no default Streamlit widget for this, but Streamlit user vivien made a custom component that displays clickable images in a grid.
To create this widget, pass the list of thumbnails, the list of video names (to show when hovered over the thumbnail), and the styling details to the constructor. If there are too many URLs, the display might take up too much space. To avoid that, in the div_style set "overflow-y":"auto" to have a scroll bar.
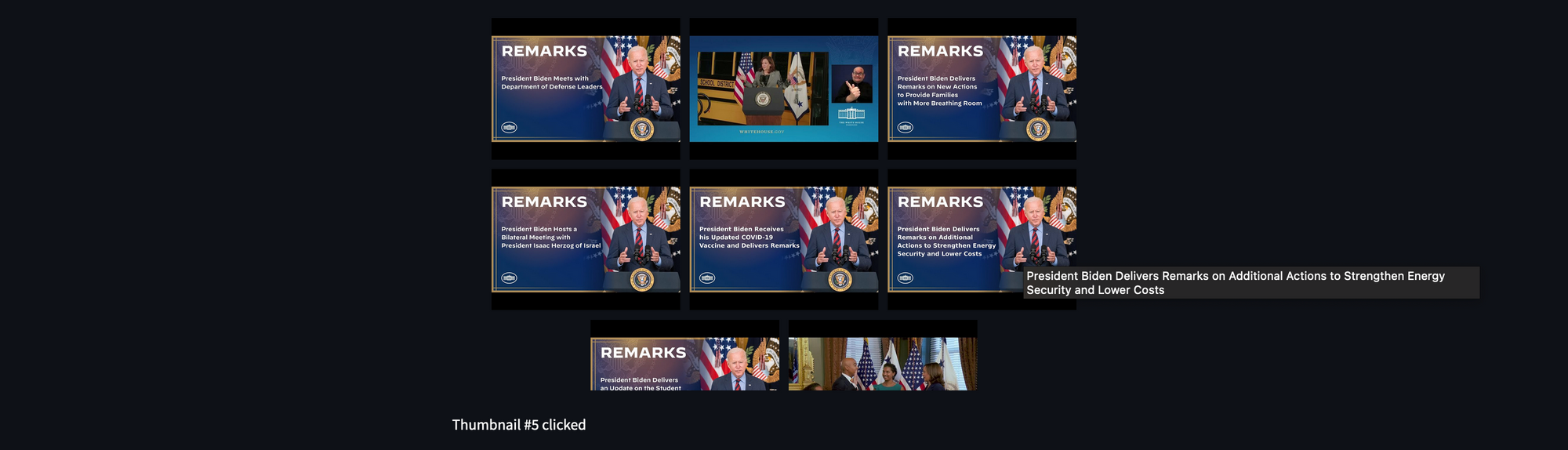
Whichever thumbnail the user clicks, that video will be selected for the analysis:
from st_clickable_images import clickable_images
# ... (continued if file is not None:)
selected_video = clickable_images(thumbnails,
titles = titles,
div_style={"height": "400px", "display": "flex", "justify-content": "center", "flex-wrap": "wrap", "overflow-y":"auto"},
img_style={"margin": "5px", "height": "150px"}
)
st.markdown(f"Thumbnail #{selected_video} clicked" if selected_video > -1 else "No image clicked")
# ... (continued if file is not None:)
Step 3. Submit the video to AssemblyAI for analysis
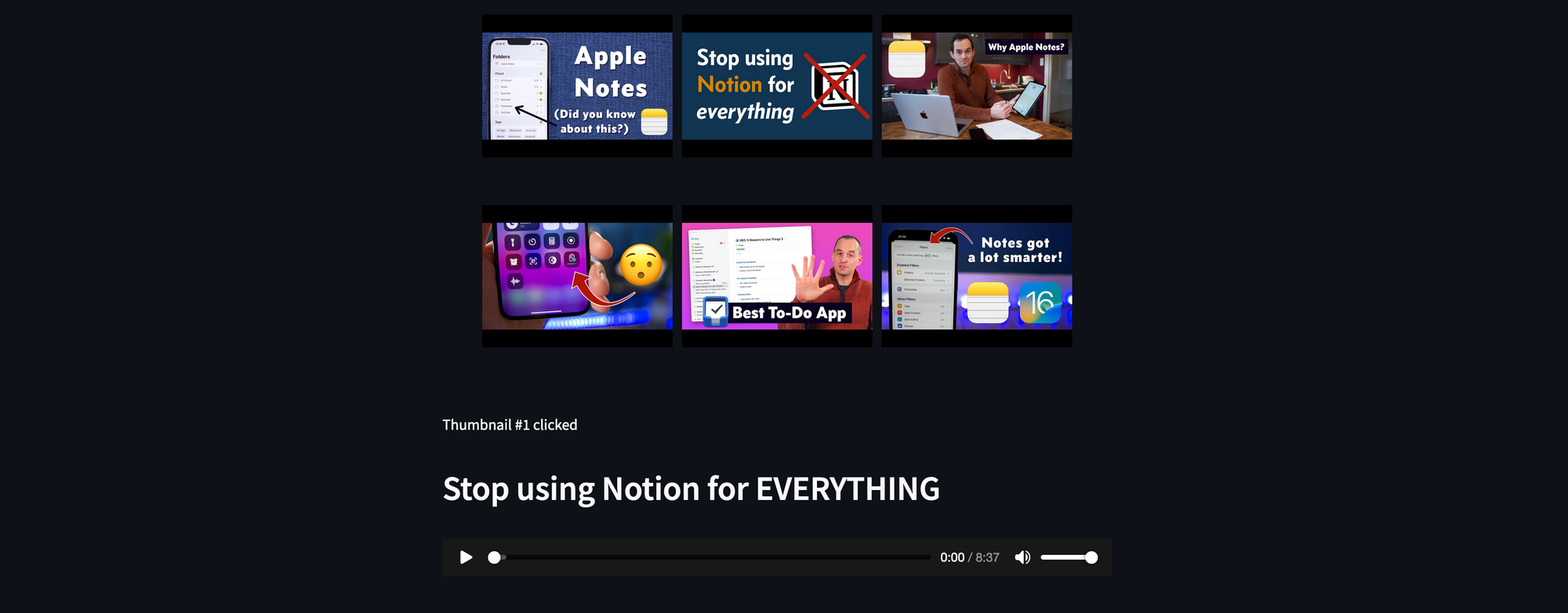
If the user doesn't select a video, the widget will return -1. If the user selects a video from the grid, the widget will return the video's number starting from 0. Using this number, we can also get the video's URL, title, and location from the lists we previously created. The app will display the title of the selected video and an audio player:
# ... (continued if file is not None:)
if selected_video > -1:
video_url = urls_list[selected_video]
video_title = titles[selected_video]
save_location = locations[selected_video]
st.header(video_title)
st.audio(save_location)
# ... (continued if selected_video > -1:)
Once a video is selected, you need to:
- Upload the audio to AssemblyAI;
- Start the analysis;
- Read the results;
For each of these steps, there is a separate function. To use these functions:
- Import requests library to send requests to AssemblyAI;
- Set up transcription and uploading endpoints (addresses) to communicate with AssemblyAI;
- Set up a header to specify the
content-typeand authenticate your app with the API key that you created earlier;
I've uploaded this app to Streamlit Community Cloud and am specifying st.secrets["auth_key"] as the location of the API key. If you'd like, you can also directly pass your API key there:
import requests
transcript_endpoint = "<https://api.assemblyai.com/v2/transcript>"
upload_endpoint = "<https://api.assemblyai.com/v2/upload>"
headers = {
"authorization": st.secrets["auth_key"],
"content-type": "application/json"
}
The first step is to upload this audio file to AssemblyAI with the function upload_to_AssemblyAI. Using the helper function read_file, the function reads the audio file in the given location (save_location) in chunks. This is used in the post request that is sent to the upload_endpoint of AssemblyAI together with the header for authentication.
As a response, you get the URL to where the audio file is uploaded:
@st.experimental_memo
def upload_to_AssemblyAI(save_location):
CHUNK_SIZE = 5242880
def read_file(filename):
with open(filename, 'rb') as _file:
while True:
print("chunk uploaded")
data = _file.read(CHUNK_SIZE)
if not data:
break
yield data
upload_response = requests.post(
upload_endpoint,
headers=headers, data=read_file(save_location)
)
print(upload_response.json())
audio_url = upload_response.json()['upload_url']
print('Uploaded to', audio_url)
return audio_url
Next, you pass the audio_url to the start_analysis function. This function sends another post request to AssemblyAI to start the analysis.
By default, all submitted audio is transcribed at AssemblyAI. To start a transcription (or analysis) job, specify the audio file URL, the authentication details, and the kind of analysis you want (read our docs for a list of deep learning models).
Here you'll use three AssemblyAI models:
- The Summarization model—to return the summary of this audio file;
- The Content Moderation model—to flag potentially sensitive and harmful content on topics such as alcohol, violence, gambling, and hate speech;
- The Topic Detection model—to detect up to 700 topics (automotive, business, technology, education, standardized tests, inflation, off-road vehicles, and so on);
The summarization model can give you different summaries:
- A bullet list (
bullets) - A longer bullet list (
bullets_verbose) - A few words (
gist) - A sentence (
headline) - A paragraph (
paragraph)
The analysis will take a few seconds or minutes, depending on the length of the audio file. As a response to the transcription job, you'll get a job ID. Use it to create a polling endpoint to receive the analysis results:
@st.experimental_memo
def start_analysis(audio_url):
## Start transcription job of audio file
data = {
'audio_url': audio_url,
'iab_categories': True,
'content_safety': True,
"summarization": True,
"summary_type": "bullets"
}
transcript_response = requests.post(transcript_endpoint, json=data, headers=headers)
print(transcript_response)
transcript_id = transcript_response.json()['id']
polling_endpoint = transcript_endpoint + "/" + transcript_id
print("Transcribing at", polling_endpoint)
return polling_endpoint
Step 4. Receive analysis results from AssemblyAI
The last step is to collect the analysis results from AssemblyAI. The results are not generated instantaneously. Depending on the length of the audio file, the analysis might take a couple of seconds to a couple of minutes. To keep it simple and reusable, the process of receiving the analysis is wrapped in a function called get_analysis_results.
In a while loop, every 10 seconds, a get request will be sent to AssemblyAI through the polling endpoint that includes the transaction job ID. In response to this get request, you'll get the job status as, "queued", “submitted”, “processing”, or “completed”.
Once the status is "completed", the results are returned:
@st.experimental_memo
def get_analysis_results(polling_endpoint):
status = 'submitted'
while True:
print(status)
polling_response = requests.get(polling_endpoint, headers=headers)
status = polling_response.json()['status']
# st.write(polling_response.json())
# st.write(status)
if status == 'submitted' or status == 'processing' or status == 'queued':
print('not ready yet')
sleep(10)
elif status == 'completed':
print('creating transcript')
return polling_response
break
else:
print('error')
return False
break
Step 5. Display analysis results
You get three types of analysis on your audio:
- Summarization;
- Sensitive content detection;
- Topic detection;
Let's display them in order.
Extract the information with the “summary” keyword for the summarization results,“content_safety_labels” for content moderation and “iab_categories_result” for topic detection. Here is an example response:
{
"audio_duration": 1282,
"confidence": 0.9414384528795772,
"id": "oeo5u25f7-69e4-4f92-8dc9-f7d8ad6cdf38",
"status": "completed",
"text": "Ted talks are recorded live at the Ted Conference. This episode features...",
"summary": "- Dan Gilbert is a psychologist and a happiness expert. His talk is recorded live at Ted conference. He explains why the human brain has nearly tripled in size in 2 million years. He also explains the difference between winning the lottery and becoming a paraplegic.\\n- In 1994, Pete Best said he's happier than he would have been with the Beatles. In the free choice paradigm, monet prints are ranked from the one they like the most to the one that they don't. People prefer the third one over the fourth one because it's a little better.\\n- People synthesize happiness when they change their affective. Hedonic aesthetic reactions to a poster. The ability to make up your mind and change your mind is the friend of natural happiness. But it's the enemy of synthetic happiness. The psychological immune system works best when we are stuck. This is the difference between dating and marriage. People don't know this about themselves and it can work to their disadvantage.\\n- In a photography course at Harvard, 66% of students choose not to take the course where they have the opportunity to change their mind. Adam Smith said that some things are better than others. Dan Gilbert recorded at Ted, 2004 in Monterey, California, 2004.",
"content_safety_labels": {
"status": "success",
"results": [
{
"text": "Yes, that's it. Why does that happen? By calling off the Hunt, your brain can stop persevering on the ugly sister, giving the correct set of neurons a chance to be activated. Tip of the tongue, especially blocking on a person's name, is totally normal. 25 year olds can experience several tip of the tongues a week, but young people don't sweat them, in part because old age, memory loss, and Alzheimer's are nowhere on their radars.",
"labels": [
{
"label": "health_issues",
"confidence": 0.8225132822990417,
"severity": 0.15090347826480865
}
],
"timestamp": {
"start": 358346,
"end": 389018
}
},
...
],
"summary": {
"health_issues": 0.8750781728032808
...
},
"severity_score_summary": {
"health_issues": {
"low": 0.7210625030587972,
"medium": 0.2789374969412028,
"high": 0.0
}
}
},
"iab_categories_result": {
"status": "success",
"results": [
{
"text": "Ted Talks are recorded live at Ted Conference...",
"labels": [
{
"relevance": 0.0005944414297118783,
"label": "Religion&Spirituality>Spirituality"
},
{
"relevance": 0.00039072768413461745,
"label": "Television>RealityTV"
},
{
"relevance": 0.00036419558455236256,
"label": "MusicAndAudio>TalkRadio>EducationalRadio"
}
],
"timestamp": {
"start": 8630,
"end": 32990
}
},
...
],
"summary": {
"MedicalHealth>DiseasesAndConditions>BrainAndNervousSystemDisorders": 1.0,
"FamilyAndRelationships>Dating": 0.7614801526069641,
"Shopping>LotteriesAndScratchcards": 0.6330153346061707,
"Hobbies&Interests>ArtsAndCrafts>Photography": 0.6305723786354065,
"Style&Fashion>Beauty": 0.5269057750701904,
"Education>EducationalAssessment": 0.49798518419265747,
"BooksAndLiterature>ArtAndPhotographyBooks": 0.45763808488845825,
"FamilyAndRelationships>Bereavement": 0.45646440982818604,
"FineArt>FineArtPhotography": 0.3921416699886322,
}
}
First, call each of the functions defined above and then parse results to get each part of the analysis:
# ... (continued if selected_video > -1:)
# upload mp3 file to AssemblyAI
audio_url = upload_to_AssemblyAI(save_location)
# start analysis of the file
polling_endpoint = start_analysis(audio_url)
# receive the results
results = get_analysis_results(polling_endpoint)
# separate analysis results
bullet_points = results.json()['summary']
content_moderation = results.json()["content_safety_labels"]
topic_labels = results.json()["iab_categories_result"]
# ... (continued if selected_video > -1:)
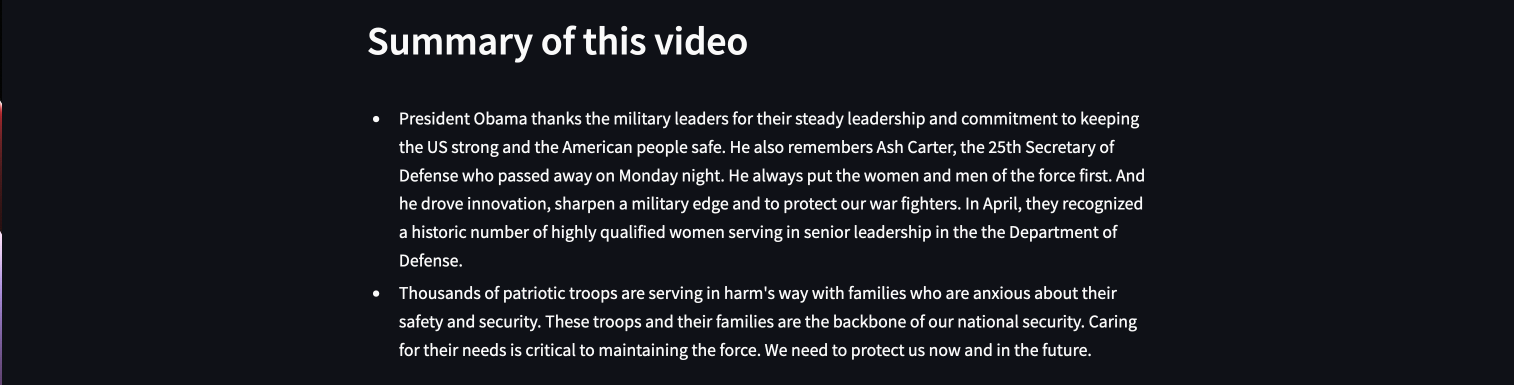
Video Summary
It's easy to display the summary since it comes in a nicely formatted bullet list. You only need to extract it from the JSON response and display it with st.write():
# ... (continued if selected_video > -1:)
st.header("Video summary")
st.write(bullet_points)
# ... (continued if selected_video > -1:)
Sensitive Topics
The content moderation model will give you detailed information on the following:
- The sentence that caused this audio to be flagged
- The timestamp of when it starts and ends
- The severity of this sensitive topic
- The confidence in this detection
In the context of this project, the user doesn't need to see this much detail, so let's display the summary of this analysis as a pandas dataframe:
# ... (continued if selected_video > -1:)
st.header("Sensitive content")
if content_moderation['summary'] != {}:
st.subheader('🚨 Mention of the following sensitive topics detected.')
moderation_df = pd.DataFrame(content_moderation['summary'].items())
moderation_df.columns = ['topic','confidence']
st.dataframe(moderation_df, use_container_width=True)
else:
st.subheader('✅ All clear! No sensitive content detected.')
# ... (continued if selected_video > -1:)
The result will look like this:

Or like this:

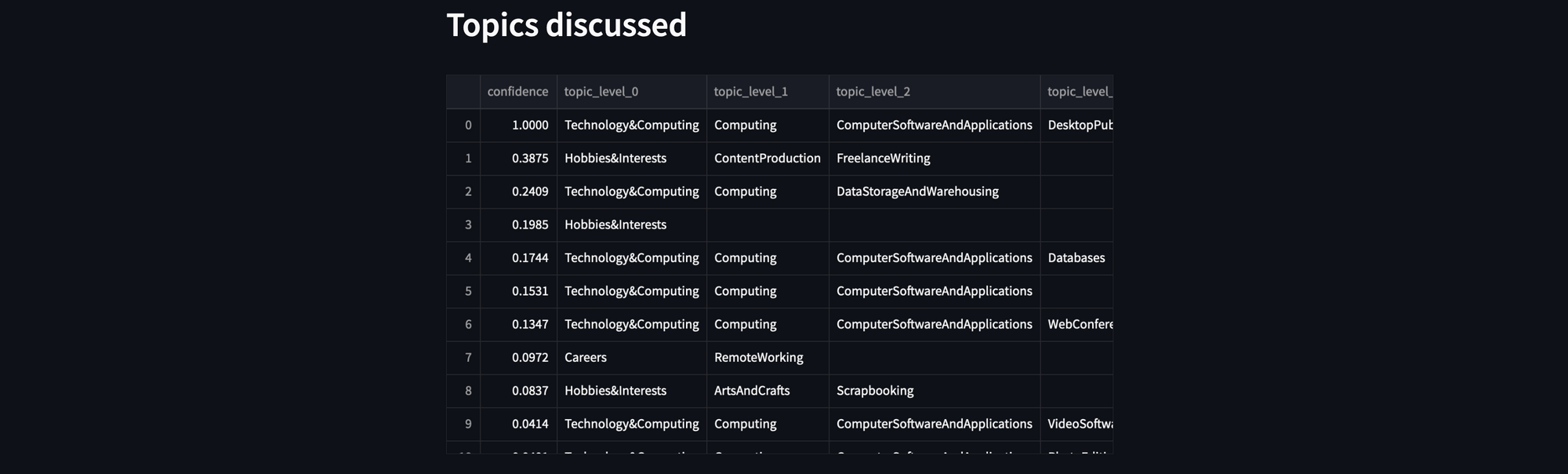
Topic Detection
The topic detection model will give you similar results. Once pasted into a pandas dataframe, structure it to have a separate column for each topic granularity level, then sort it with the confidence from the topic detection model:
# ... (continued if selected_video > -1:)
st.header("Topics discussed")
topics_df = pd.DataFrame(topic_labels['summary'].items())
topics_df.columns = ['topic','confidence']
topics_df["topic"] = topics_df["topic"].str.split(">")
expanded_topics = topics_df.topic.apply(pd.Series).add_prefix('topic_level_')
topics_df = topics_df.join(expanded_topics).drop('topic', axis=1).sort_values(['confidence'], ascending=False).fillna('')
st.dataframe(topics_df, use_container_width=True)
# ... (continued if selected_video > -1:)
Wrapping up
And that's a wrap! Whew. You did it.
This content analyzer app makes analyzing YouTube super easy, doesn't it? Once you connect to AssemblyAI, you can make more Streamlit apps. Check out our documentation to learn about our other state-of-the-art models and how to use them to get information from your audio or video files. Or watch my video tutorial, where I talk about this in detail.
If you have any questions about this app or if you build an app by using both AssemblyAI and Streamlit, please comment below or reach out to me on Twitter or YouTube.
Happy coding! 🧑💻




Comments
Continue the conversation in our forums →