
To learn more about Rasalit, check out the article on the Rasa blog.
Rasa Open Source is a machine learning framework for building text- and voice-based virtual assistants. It’s a Python library with tools that can understand messages, reply to users, and connect to different messaging channels and APIs.
In this post, we'll do a deep dive into the Rasalit project, which is an integration between Rasa and Streamlit, but here's a sample app if you want to test it out right away!
Challenges
Rasa actively researches and shares practical algorithms that can handle natural language tasks, but exploring algorithms in this space brings a few unique challenges.
For starters, we can only benchmark on datasets that are openly available. If there is any private data in a conversation, it can’t be shared - which excludes a lot of meaningful datasets.
Privacy isn’t the only constraint we face, another limitation is the languages we can use in our benchmarking datasets. We’ve done our best to integrate many open-source tools for non-English deployments, but we still actively rely on our community for feedback.
To address this, we’ve been looking for a meaningful tool to give to our community that makes it easy to explore and investigate trained Rasa models interactively. If we can make it easy for users to inspect their pipelines, we also make it easier for people to give feedback on specific parts.
Enter Rasalit
Rasalit’s first iteration was a simple demo in a Jupyter notebook. To use it, you would declare an utterance text for a pre-trained Rasa pipeline to classify and then you could see the prediction’s confidence values in a bar chart.
In theory, we had a meaningful visualization. But it became clear this approach wouldn’t work in practice for many reasons:
- Sharing notebooks over GitHub tends to be a painful experience.
- Not every Rasa user is familiar with Python, which means a Jupyter notebook can be intimidating for some.
- Hosting a Jupyter notebook on a server involves security risks. You can’t run a Jupyter notebook in read-only mode and still allow users to change settings, which means you can’t host our visualizations securely on a private server.
- Jupyter is excellent when writing code, but code can distract us from our visualizations. We wanted users to focus on the model views.
That’s why, instead of going with Jupyter, we decided to package our views with Streamlit. Streamlit allows us to control what users can interact with and keep distractions away.
We ended up creating several Streamlit apps that proved valuable, and we bundled them all together into a package called Rasalit.
Here’s what it looks like when you run it from the terminal.
> python -m rasalit
Options:
--help Show this message and exit.
Commands:
overview Gives an overview of all `rasa train nlu` results.
live-nlu Select a trained Rasa model and interact with it.
spelling Check the effect of spelling on NLU predictions.
nlu-cluster Cluster a text file to look for clusters of intents.
version Prints the current version
Each command represents a separate Streamlit application. When passing arguments in Rasalit, we can translate them into appropriate arguments for Streamlit.
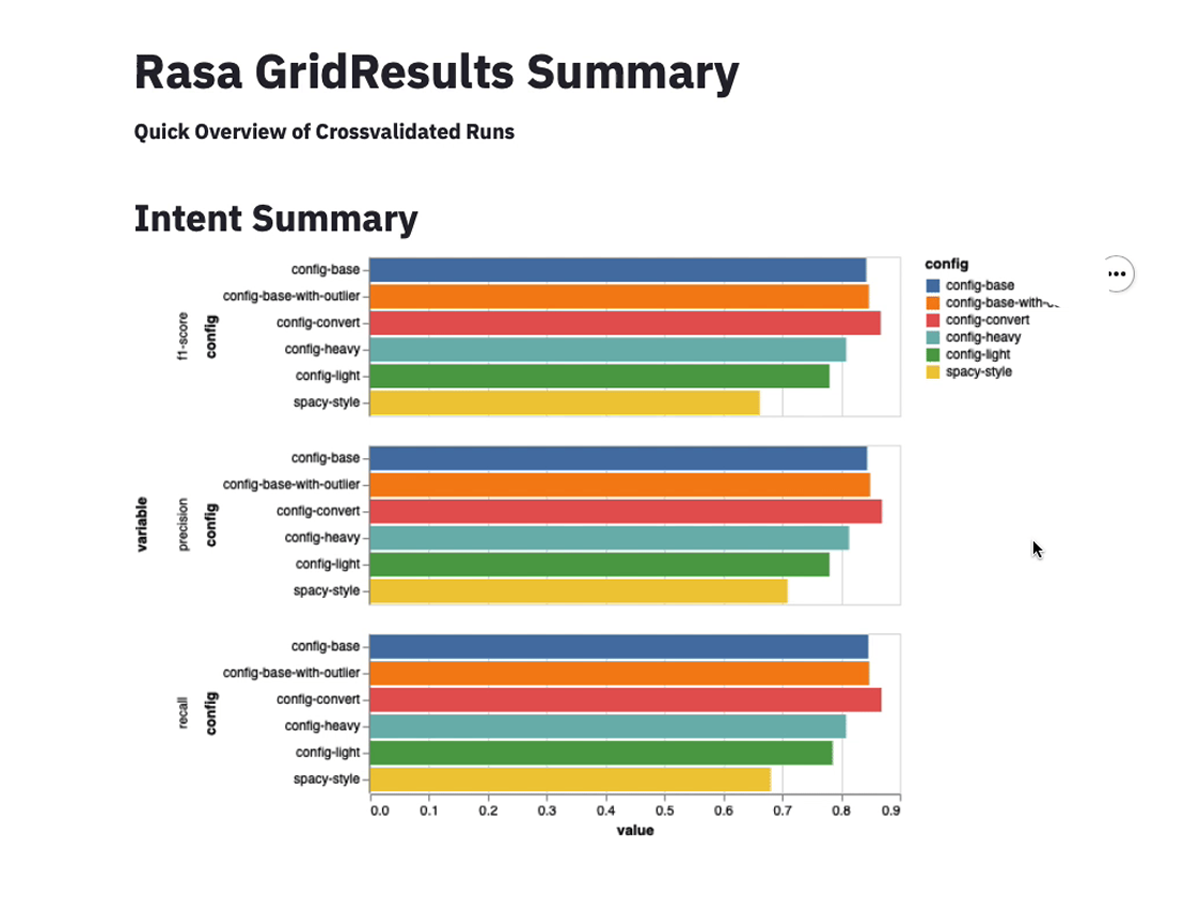
GridSearch Overview
One tool in Rasalit handles visualizing grid-search results. You can run cross-validation from the command line in Rasa, but our plugin now makes it easy to get an overview of the scores too.
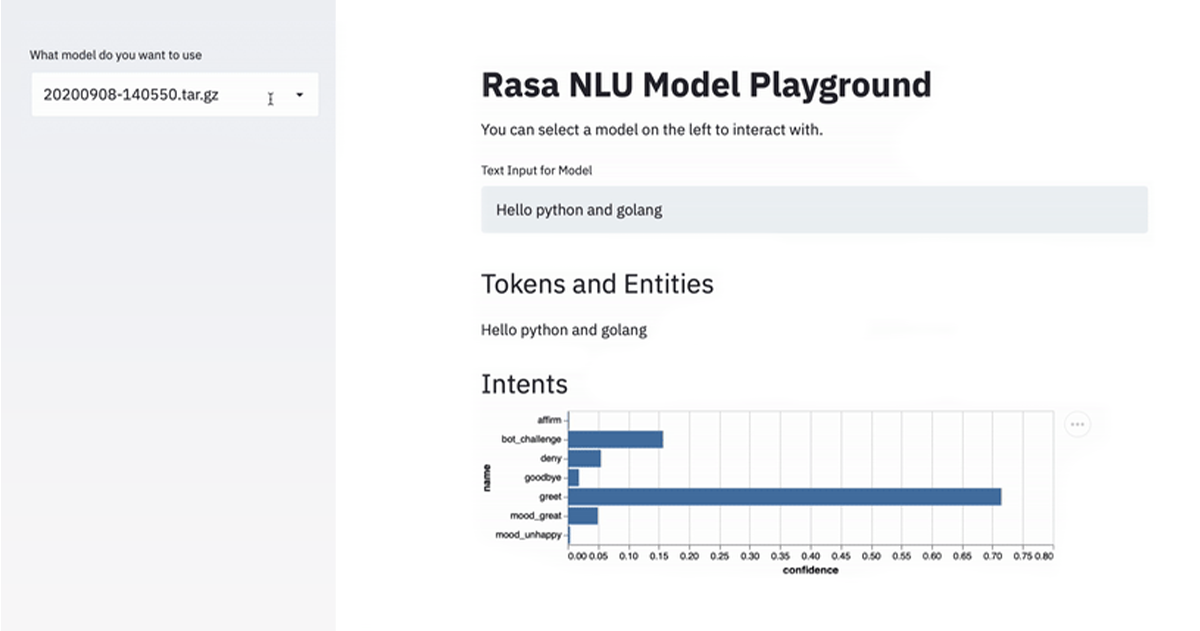
Rasa NLU Playground
The second app allows users to interact directly with a pre-trained Rasa model. You get an overview of the intent confidence and any detected entities.
We’ve also added charts that visualize the classifier’s internal attention mechanism.
To keep the overview simple, we’ve hidden these details. An excellent feature from Streamlit is you can hide details via the expander component. That means we can add detailed features for our Research team while still keeping the app distraction-free for the general community.
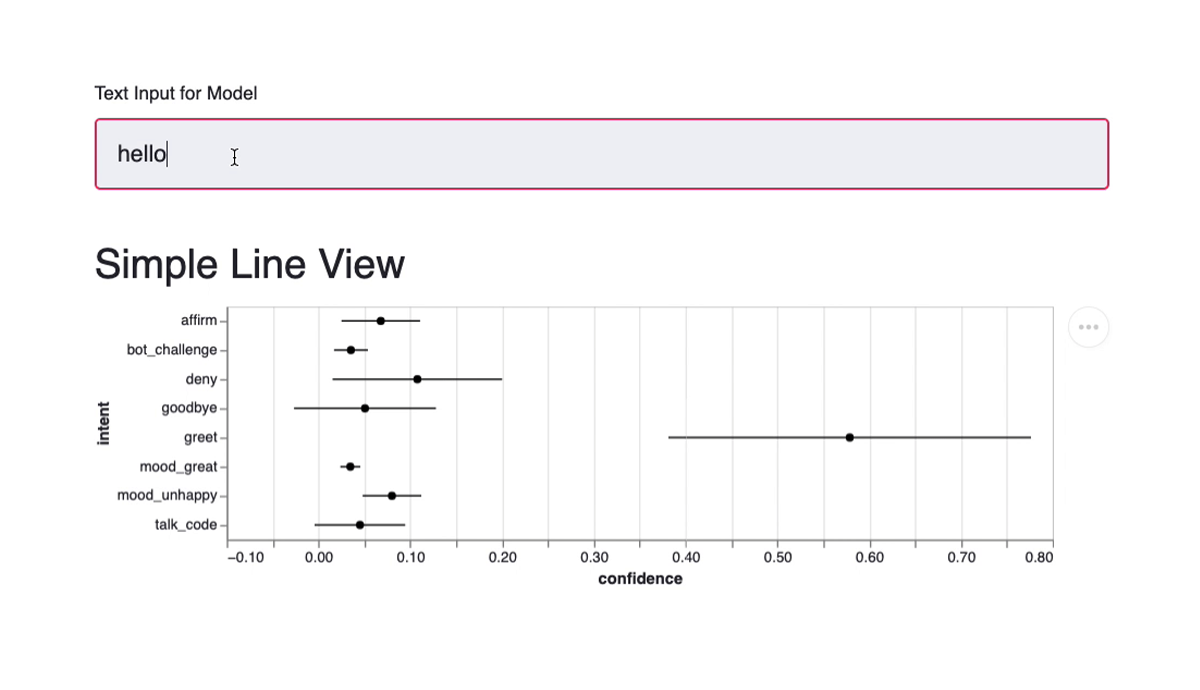
Spelling Effects
There’s also a spelling robustness checker in Rasalit, which simulates spelling errors on a text that you give it. It will show you how robust your trained models are against typos.
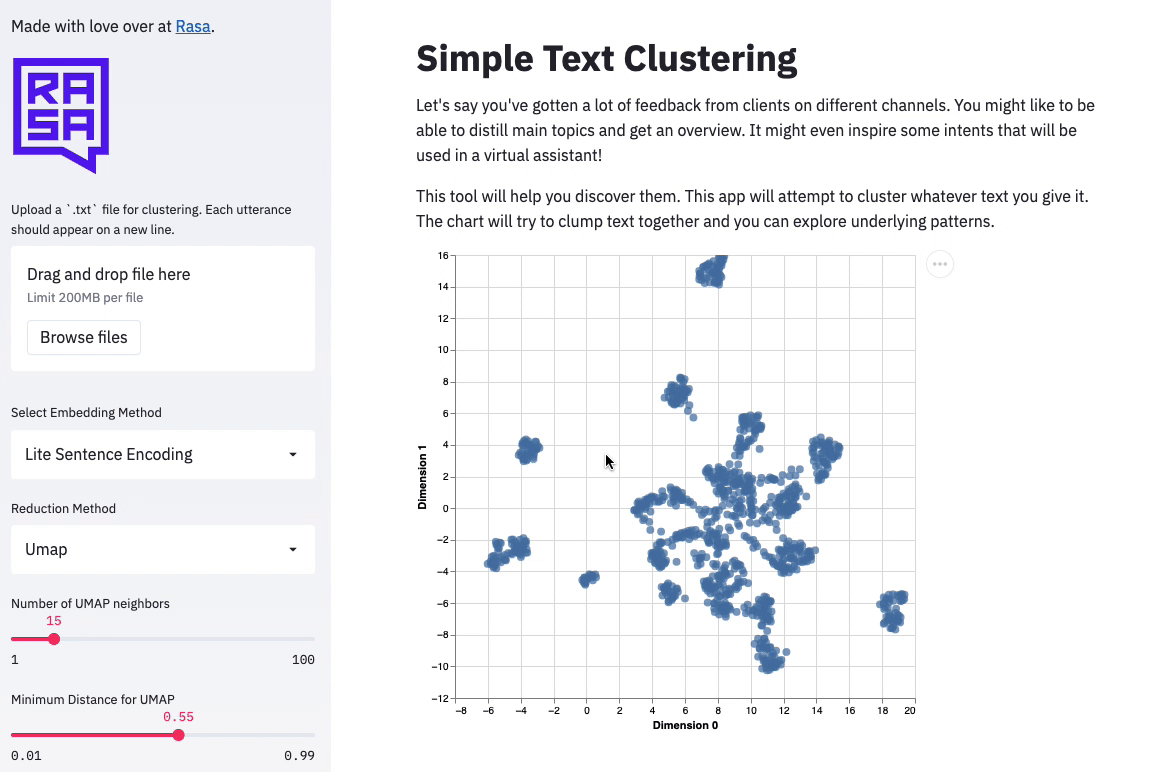
Text Clustering
Finally, we’ve also added a tool for folks who are just getting started with their virtual assistants. Some users might already have some unlabelled training data and might just be curious to explore the clusters in them.
For this use case, we’ve built a text clustering demo. It uses a light version of the universal sentence encoder to cluster text together. This result can be explored interactively.
Steps Going Forward
Streamlit has turned out to be a surprisingly flexible communication tool. Our research team and community members all use Rasalit. It’s also been getting us great feedback! We’re proud to report it has surpassed 100 Github stars.
Rasalit has been so successful we’ve also started using it in other places. We host a training data repository where users can find training data to help get them started with their first virtual assistant.
Before, users had to search inside the many YAML files to find the training data that fits their use cases. Now we’ve simply attached a hosted Streamlit app that makes it easy for users to find the relevant training data. It’s a great experience!
We’re excited to see what you all think of Rasalit and what new applications we find for Streamlit, both for our Research team and across the Rasa open source community.
Resources
Rasa
Streamlit




Comments
Continue the conversation in our forums →