
This is Part 2 of a two-part blog series on building a semantic search application for finding Foursquare venues in NYC. We'll leverage Streamlit, Snowflake, OpenAI, and Foursquare's free NYC venue data from Snowflake Marketplace.
In Part 1, we explored building a semantic search engine powered by Snowflake. We delved deep into data wrangling, compared different cosine similarity implementations, and evaluated their performance.
In this second part, I'll guide you through the remaining steps to complete the app.
Before we proceed, let's quickly discuss…
How does the app work?
The app works as follows:
- Users search for venues by selecting up to five neighborhoods in an NYC borough and entering a search query (e.g., "Epic Night Out").
- The application:
- Uses OpenAI's Embeddings API to generate embeddings for the search query
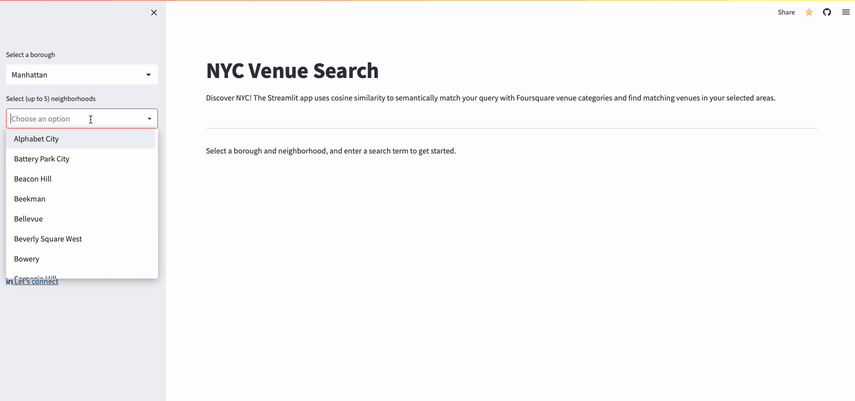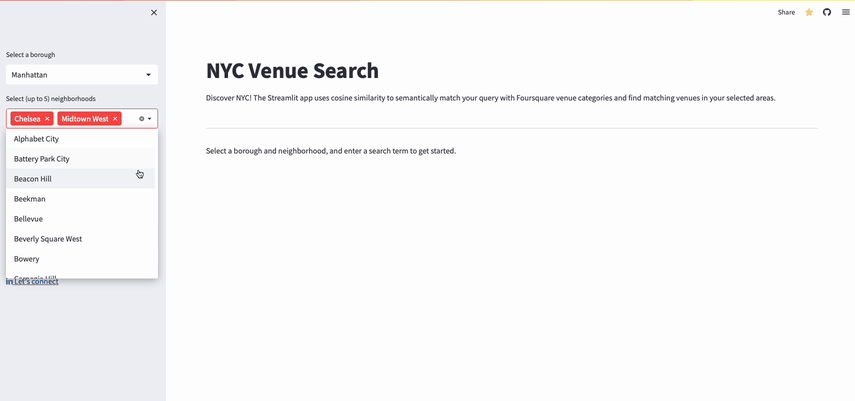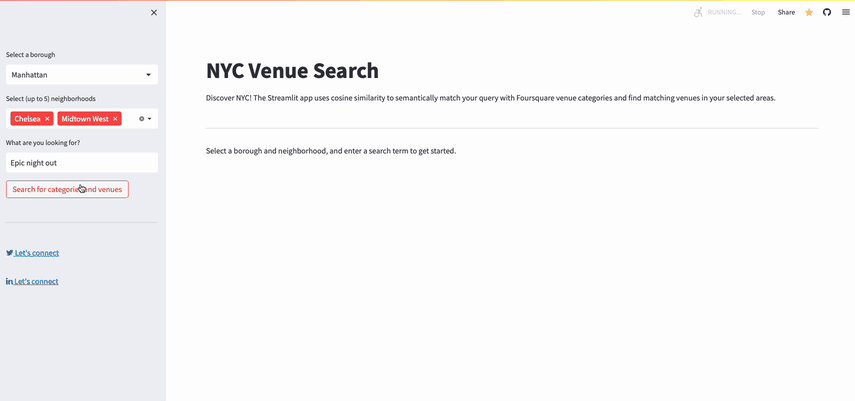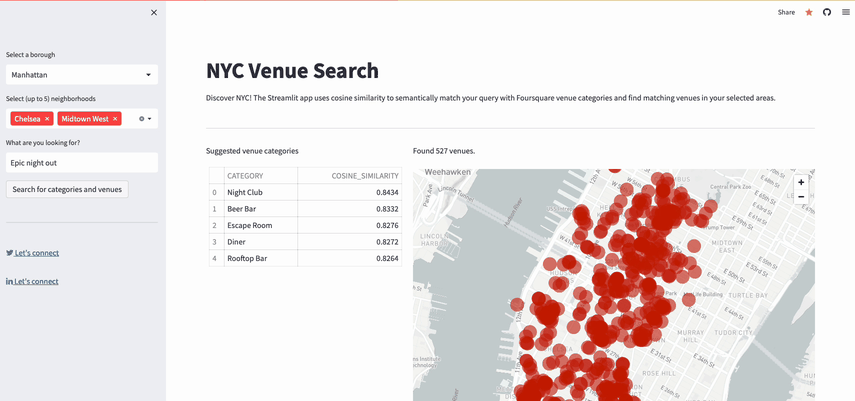
- Uses Snowflake to retrieve up to five Foursquare venue categories with embedding vectors that most closely match the user query embeddings
- Uses Snowflake to search for venues within the suggested categories in the chosen neighborhoods
- Displays the venues on a map view and in a data frame
Now that we understand the app, let's proceed with the remaining steps!
Step 1. Safeguard your Snowflake account
Ensuring the security of your Snowflake account is essential. To mitigate security risks, provide the least amount of access necessary to all users and applications.
To limit Streamlit's Snowflake access, follow these steps:
1. Create a user account for the Streamlit application (for example, svc_streamlit)
2. Create a scoped-down role with read-only access to the Foursquare data, the new schema and tables, and a warehouse:
CREATE ROLE foursquare_read;
GRANT usage on database foursquare to role foursquare_read;
GRANT usage on schema foursquare.main to role foursquare_read;
GRANT SELECT ON ALL tables in schema foursquare.main to role foursquare_read;
GRANT SELECT ON FUTURE tables in schema foursquare.main to role foursquare_read;
GRANT SELECT ON FUTURE views in schema foursquare.main to role foursquare_read;
GRANT IMPORTED PRIVILEGES on database foursquare_nyc to role foursquare_read;
GRANT usage on warehouse [YOUR_WAREHOUSE_NAME] to role foursquare_read;
3. Set the Streamlit user's default role and warehouse to be the assigned role and warehouse.
With a Streamlit user set up, let's work on connecting Streamlit to Snowflake.
Step 2. Write backend functions to get data from Snowflake
In this step, we'll write the backend functions required to fetch data from the Snowflake database.
1. Import the necessary packages:
import snowflake.connector
from snowflake.connector import DictCursor
import streamlit as st
2. Create base functions to connect to Snowflake and execute Snowflake queries:
def _init_connection():
return snowflake.connector.connect(**st.secrets["snowflake"])
@st.cache_data(ttl=10, show_spinner=False)
def _run_query(query_str):
with _init_connection() as conn:
with conn.cursor(DictCursor) as cur:
cur.execute(query_str)
return cur.fetchall()
The _init_connection function utilizes the snowflake-connector-python library and Streamlit's secret management to connect to Snowflake. The _run_query function establishes a new connection to Snowflake, executes a query, and returns the results. The DictCursor returns column names alongside the data. It also uses st.cache_data to avoid re-running the same queries within 10 seconds.
3. Create functions to get boroughs and neighborhoods within a borough:
def get_boroughs():
sql = """SELECT * FROM borough_lookup"""
boroughs = _run_query(sql)
return boroughs
def get_neighborhoods(borough_name):
sql = """
SELECT n.*
FROM neighborhood_lookup n
INNER JOIN borough_neighborhood bn ON n.id = bn.neighborhood_id
INNER JOIN borough_lookup b ON bn.borough_id = b.id
WHERE b.name IN ('{0}')
ORDER BY b.name, n.name
""".format(borough_name)
neighborhoods = _run_query(sql)
return neighborhoods
4. Create a function to get a list of categories that semantically match the user's query:
def get_categories(search_embeddings):
sql = """
WITH base_search AS (
SELECT '{0}' embedding
)
, search_emb AS (
SELECT
n.index
, n.value
from base_search l
, table(flatten(input => parse_json(l.embedding))) n
ORDER BY n.index
)
, search_emb_sqr AS (
SELECT index, value, value*value value_sqr
FROM search_emb r
)
, result AS (
SELECT
v.category_id
, SUM(s.value * v.value) / SQRT(SUM(s.value * s.value) * SUM(v.value * v.value)) cosine_similarity
FROM search_emb_sqr s
INNER JOIN category_embed_value v ON s.index = v.index
GROUP BY v.category_id
ORDER BY cosine_similarity DESC
LIMIT 5
)
SELECT c.category, r.cosine_similarity
FROM result r
INNER JOIN category_lookup c ON r.category_id = c.category_id
WHERE r.cosine_similarity > 0.81
ORDER BY r.cosine_similarity DESC
""".format(search_embeddings)
recommended_categories = _run_query(sql)
return recommended_categories
This query builds upon the cosine similarity query discussed in Part 1. It takes user query embeddings as input and performs a final lookup to return the category names.
5. Create a function to get places within specific categories and in a list of neighborhoods:
def get_places(borough_name, neighborhood_list, category_list):
sql = """
WITH base_neighborhoods AS (
SELECT n.id
FROM borough_lookup b
INNER JOIN borough_neighborhood bn on b.id = bn.borough_id
INNER JOIN neighborhood_lookup n ON bn.neighborhood_id = n.id
WHERE b.name = '{0}'
AND n.name IN ({1})
)
, neighborhood_places AS (
SELECT pn.fsq_id
FROM place_neighborhood pn
WHERE pn.neighborhood_id IN (SELECT id FROM base_neighborhoods)
ORDER BY pn.fsq_id
)
, base_categories AS (
SELECT c.category_id
FROM category_lookup c
WHERE c.category IN ({2})
)
, category_places AS (
SELECT pc.fsq_id
FROM category_place pc
WHERE pc.category_id IN (SELECT category_id FROM base_categories)
ORDER BY pc.fsq_id
)
, places AS (
SELECT
fsq_id
, name
, latitude
, longitude
, concat(COALESCE(address,''), COALESCE(address_extended,'')) address
, fsq_category_labels
, n1.value::string category
FROM place_lookup l
, table(flatten(l.fsq_category_labels)) n
, table(flatten(n.value)) n1
WHERE fsq_id IN (
SELECT fsq_id FROM neighborhood_places
INTERSECT
SELECT fsq_id FROM category_places
)
AND latitude IS NOT NULL
AND longitude IS NOT NULL
QUALIFY row_number() OVER (PARTITION BY fsq_id, n.seq, n.index, n1.seq ORDER BY n1.index DESC) = 1
)
SELECT
fsq_id
, ANY_VALUE(name) name
, ANY_VALUE(latitude) latitude
, ANY_VALUE(longitude) longitude
, ANY_VALUE(address) address
, listagg(category, ', ') categories
FROM places
GROUP BY fsq_id
ORDER BY fsq_id
""".format(borough_name, _list_to_str(neighborhood_list), _list_to_str(category_list))
places = _run_query(sql)
return places
In the query above, we first filter the venues by narrowing them down to specific categories within a list of neighborhoods and venues. Next, we intersect these two lists to produce a final list of venues. For UI display purposes, we extract the latitude, longitude, street address, and leaf categories of each venue. The QUALIFY statement extracts the last category in the inner list of each category list found in the fsq_category_labels column.
Step 3: Implement OpenAI endpoints
Our Streamlit app uses OpenAI's Python SDK to create embeddings of user queries and to moderate user queries (to ensure user queries don't violate OpenAI's Content Policy).
import openai
import streamlit as st
openai.api_key = st.secrets['openai']['api_key']
def get_embedding(category_str):
try:
response = openai.Embedding.create(
input=category_str,
model="text-embedding-ada-002"
)
embeddings = response['data'][0]['embedding']
return embeddings
except Exception as e:
raise e
def get_moderation(user_query):
try:
moderation = openai.Moderation.create(
input=user_query
)
moderation_result = moderation['results'][0]
flagged_categories = [category for category, value in moderation_result['categories'].items() if value]
return {'flagged': moderation_result['flagged'], 'flagged_categories':flagged_categories}
except Exception as e:
raise e
Exceptions are caught and then passed to the front-end application for the sake of simplicity.
Step 4. Write the frontend Streamlit app
Now that we have our backend functions in place, let's move on to creating the front-end Streamlit app that users will interact with.
When I started developing the Streamlit app, I used the typical nested if-else scripting approach, where UI and backend operations were combined. But I quickly found it difficult to track what would cause parts of the UI to re-render. To address this, I eventually settled on the following pattern that allows for better control over app refreshes:
- Create functions to group UI elements
- Create UI element handlers to change session state variables and make backend calls
- Use session state variables to maintain user selections, control UI renderings, and avoid unnecessary calls to backend functions
By using session state variables and handlers, we ensure only the affected parts of the application are refreshed, avoiding full-page reloads or unnecessary backend calls. As a result, we can create a more efficient and responsive app. The lightweight structure also contains less overhead than an object-oriented approach to developing Streamlit apps.
In the rest of this section, we'll use these patterns to develop our Streamlit app.
1. Import the necessary libraries and backend functions:
import streamlit as st
import api_snowflake as api
import api_openai as oai
2. Set the page configuration:
st.set_page_config(page_title="NYC Venue Search", layout="wide", initial_sidebar_state="expanded")
3. Create a function to render the call-to-action (CTA) links:
def render_cta_link(url, label, font_awesome_icon):
st.markdown('<link rel="stylesheet" href="<https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css>">', unsafe_allow_html=True)
button_code = f'''<a href="{url}" target=_blank><i class="fa {font_awesome_icon}"></i> {label}</a>'''
return st.markdown(button_code, unsafe_allow_html=True)
This function uses the Markdown element to display clickable links with Font Awesome icons.
4. Create a function to lay out the search options in the sidebar:
def render_search():
"""
Render the search form in the sidebar.
"""
search_disabled = True
with st.sidebar:
st.selectbox(label=borough_search_header, options=(
[b['NAME'] for b in boroughs]), index=2, key="borough_selection", on_change=handler_load_neighborhoods)
if "neighborhood_list" in st.session_state and len(st.session_state.neighborhood_list) > 0:
st.multiselect(label=neighborhood_search_header, options=(
st.session_state.neighborhood_list), key="neighborhoods_selection", max_selections=5)
st.text_input(label=semantic_search_header,
placeholder=semantic_search_placeholder, key="user_category_query")
if "borough_selection" in st.session_state and st.session_state.borough_selection != "" \\
and "neighborhoods_selection" in st.session_state and len(st.session_state.neighborhoods_selection) > 0 \\
and "user_category_query" in st.session_state and st.session_state.user_category_query != "":
search_disabled = False
st.button(label=search_label, key="location_search",
disabled=search_disabled, on_click=handler_search_venues)
st.write("---")
render_cta_link(url="<YOUR TWITTER HANDLE URL>",
label="Let's connect", font_awesome_icon="fa-twitter")
render_cta_link(url="<YOUR LINKEDIN PROFILE URL",
label="Let's connect", font_awesome_icon="fa-linkedin")
The sidebar of the application has four primary UI elements: a select box to choose a borough, a multi-select box to choose neighborhoods, a text input for user queries, and a search button to initiate a venue search. We can store user data across application runs by assigning keys to these UI elements. Streamlit's session state documentation states that every UI widget with a key is automatically added to the session state:
- The
borough_selectionselectbox widget stores users' borough selections. When the selection changes, thehandler_load_neighborhoodsfunction fetches the list of neighborhoods in the selected borough and stores it in theneighborhood_listsession state variable. - The
neighborhoods_selectionmultiselect widget stores users' neighborhood selections. - The
location_searchbutton widget is disabled until users select a borough, then a list of neighborhoods, and enter a search query. When clicked, thehandler_search_venuesfunction handles the embedding of user queries, searches for semantically similar categories, and finds venues within those categories in the specified neighborhoods.
5. Create the function to render the search results:
def render_search_result():
"""
Render the search results on the main content area.
"""
col1, col2 = st.columns([1,2])
col1.write(category_list_header)
col1.table(st.session_state.suggested_categories)
col2.write(f"Found {len(st.session_state.suggested_places)} venues.")
if (len(st.session_state.suggested_places) > 0):
col2.map(st.session_state.suggested_places, zoom=13, use_container_width=True)
st.write(venue_list_header)
st.dataframe(data=st.session_state.suggested_places, use_container_width=True)
This function renders the suggested categories (stored in suggested_categories session state variable) and the recommended venues (stored in suggested_places session state variable) on the map. It also renders the list of venues in a dataframe.
Next, we'll move on to the handler functions.
6. Create the handler function to load neighborhoods:
def handler_load_neighborhoods():
"""
Load neighborhoods for the selected borough and update session state.
"""
selected_borough = 'Manhattan'
if "borough_selection" in st.session_state and st.session_state.borough_selection != "":
selected_borough = st.session_state.borough_selection
neighborhoods = api.get_neighborhoods(selected_borough)
st.session_state.neighborhood_list = [n['NAME'] for n in neighborhoods]
This function receives a list of neighborhoods in a borough. The borough is set to Manhattan by default but is overwritten by the user's selection (stored in the borough_selection session state variable).
The function is called whenever the user selects a new borough from the borough_selection dropdown. It is also manually called when the application first runs (so that we can preload neighborhoods in Manhattan).
7. Create the handler function to handler venue search:
def handler_search_venues():
"""
Search for venues based on user query and update session state with results.
"""
try:
moderation_result = oai.get_moderation(st.session_state.user_category_query)
if moderation_result['flagged'] == True:
flagged_categories_str = ", ".join(moderation_result['flagged_categories'])
st.error(f"⚠️ Your query was flagged by OpenAI's content moderation endpoint for: {flagged_categories_str}. \\n \\nPlease try a different query.")
else:
embeddings = oai.get_embedding(st.session_state.user_category_query)
st.session_state.suggested_categories = api.get_categories(embeddings)
if len(st.session_state.suggested_categories) > 0 and len(st.session_state.neighborhoods_selection) > 0:
category_list = [s['CATEGORY'] for s in st.session_state.suggested_categories]
st.session_state.suggested_places = api.get_places(
st.session_state.borough_selection,
st.session_state.neighborhoods_selection,
category_list)
else:
st.warning("No suggested categories found. Try a different search.")
except Exception as e:
st.error(f"{str(e)}")
This function is responsible for the bulk of the application logic. It's triggered whenever users click on the location_search button widget. The following steps are carried out:
- For safety reasons, it checks the user's query against OpenAI's moderation endpoint
- It uses OpenAI's Embeddings API to embed the user's query
- It retrieves the list of semantically similar categories from Snowflake and stores it in the
suggested_categoriessession state variable - It retrieves the list of venues within the suggested categories in the selected neighborhoods from Snowflake. The
suggested_placessession state variable stores the final list of places
The function also handles the following edge cases:
- If OpenAI's moderation endpoint flags the user query, an error message is displayed
- If no categories are semantically similar to the user query, a warning message is displayed
- Any other exception message is displayed as an error message
With the UI element group functions and handler functions defined, the rest of the application can now be wired up.
8. Control UI renders with sessions state variables:
boroughs = [{'NAME':'Brooklyn'},{'NAME':'Bronx'},{'NAME':'Manhattan'},{'NAME':'Queens'},{'NAME':'Staten Island'}]
if "selected_borough" not in st.session_state:
st.session_state.selected_borough = "Manhattan"
if "neighborhood_list" not in st.session_state:
handler_load_neighborhoods()
render_search()
st.title(page_title)
st.write(page_helper)
st.write("---")
if "suggested_places" not in st.session_state:
st.write(empty_search_helper)
else:
render_search_result()
The list of NYC boroughs is hard-coded to eliminate an unnecessary Snowflake query. When the application loads for the first time, the selected borough is set to Manhattan. If users have not chosen any neighborhoods, the handler_load_neighborhoods function is called to fetch a list of Manhattan neighborhoods. The search bar is then displayed. Finally, the empty search helper text or search results are displayed based on the presence of suggested_places as a session state variable.
Wrapping up
In this two-part blog series, we successfully built a semantic location search application using Streamlit, Snowflake, OpenAI, and Foursquare's free NYC venue data. In the first part, we focused on building a Snowflake-powered semantic search engine. In this second part, we covered essential steps such as limiting the application's access to Snowflake, connecting Streamlit to Snowflake, writing optimized backend queries, implementing OpenAI endpoints, and wiring up the Streamlit application.
Given additional time (and data), I'd add the following enhancements:
- Order the recommended venues by popularity scores (Foursquare didn't make this available in their dataset).
- Call Foursquare's venue endpoints to display recent tips and photos for each venue.
I hope you enjoyed the article. Connect with me on Twitter or LinkedIn. I'd love to hear from you.
Happy Streamlit-ing! 🎈




Comments
Continue the conversation in our forums →