
Hey, community! 👋
My name is Kevin Soderholm, and I'm a data scientist in the banking industry. My two favorite things about data science are:
- Brainstorming. I enjoy breaking down pain points and identifying analytical solutions. It's like a game that keeps me coming back for more.
- Building. Whether it's an ML model, a data dashboard, or a Streamlit app, I love starting with nothing and bringing something to life with every line of code.
Recently, I've been searching for a bigger home in a suburb around the Twin Cities (Minneapolis/St. Paul) for my growing family. After spending hours on it, I realized I didn't know how to find the perfect location. I could describe what I wanted down to the square footage and the number of bedrooms, but I wasn't sure WHERE I wanted to go or HOW to decide.
None of the apps out there helped me pick a place on a map, so I decided to build my own. I called it SimiLo (for Similar Locations) and realized that it could also be used to search for vacation spots, do market research, and learn in general!
In this post, I'll show you how I built SimiLo step-by-step:
- Wrangle your data
- Strategize in users' shoes
- Methods to your madness
- Delight with your design
- Don't forget your ethics!
1. Wrangle your data
If you worked in analytics outside of academia, you know how long it takes to wrangle data. You have to do data cleaning, integration, and transformation—all crucial for analysis. Plus, sourcing data for a personal project can be frustrating. No one will guide you to a database, table, or field. You must determine the type of data that fits your solution and search for it. And unless you have a budget, you'll need to find a free, publicly available source, which can limit your options.
Fortunately, there is plenty of government data available at various geographic levels. And you can also use ChatGPT.
For example:

Sometimes ChatGPT may lead to broken links or outdated information, but other times it'll point you exactly to what you need. Once you gather enough datasets, combine them across geographic levels of zip, city, and county.
There are two ways to do it:
- Use the U.S. Department of Housing and Urban Development's "Cross-walk" files for mapping zip codes to counties. It's challenging since zip codes cross county lines, resulting in a many-to-many merge that can be handled using population density for tie-breakers (read more here).
- Map zip codes to cities using the U.S. Postal Service city designations. USPS cities often lump together nearby municipalities. For example, some suburbs around the Minneapolis—St. Paul metro area all roll up to the USPS city of St. Paul. This is the only clean way to roll up zip codes to cities, and the city is an important design component. Why? Because people think about cities, not zip codes.
Have you got your datasets? It's time to explore, clean, and create! (This is the most fun part of data wrangling.)
Start by examining your datasets from top to bottom and inside and out—view the distributions of all relevant fields, interpret the values, explore relationships, etc. In the real world, data is rarely clean and requires many small changes such as feature engineering, missing imputations, potential outlier treatment, data transformations, and so on (the list may never end until you throw in the towel and call it good enough).
Here is an example of data wrangling:
#read and clean water file
wf = pd.read_csv('/folder/water.txt', delimiter=None, dtype={'GEOID': str})
# remove extra blank space from last column of dataframe
wf.iloc[:, -1] = wf.iloc[:, -1].str.strip()
#assign delimiter
wf = wf.iloc[:, -1].str.split('\\t', expand=True)
#rename cols
wfcols=['ZCTA5','ALAND','AWATER','ALAND_SQMI','AWATER_SQMI','LAT','LON']
wf = wf.rename(columns=dict(zip(wf.columns, wfcols)))
#change data type to float (numeric with decimal precision)
wf['ALAND'] = wf['ALAND'].astype(float)
wf['AWATER'] = wf['AWATER'].astype(float)
wf['ALAND_SQMI'] = wf['ALAND_SQMI'].astype(float)
wf['AWATER_SQMI'] = wf['AWATER_SQMI'].astype(float)
#create features
wf['Pct_Water']=wf['AWATER']/wf['ALAND']
wf['Tot_Area']=wf['ALAND_SQMI']+wf['AWATER_SQMI']
#filter cols
wf=wf[['ZCTA5','LAT','LON','Pct_Water','Tot_Area']]
Now your datasets are clean, curated, and ready for Streamlit ingestion. But first… you'll need to strategize.
2. Strategize in users' shoes
Before building your app, do a strategy session. Brainstorm. Think about the user's perspective. This will shape the app's functionality and design.
This is what changed SimiLo. Initially, I wanted the user to select the location criteria so the app would give them a ranked locations list. But it was clunky and confusing. What criteria combination would help them find a specific type of location? I was selecting values that were too extreme and produced unsatisfactory results. This led me to COMPARE locations rather than FILTER them. It was more effective to start with a location I knew and see similar locations across the U.S.
This workflow was more fun, the results clearer, and the approach more intuitive:
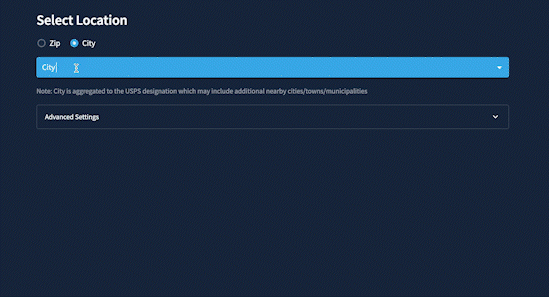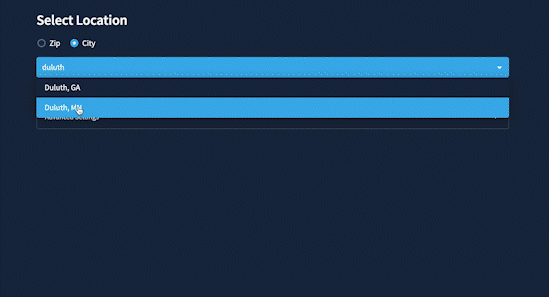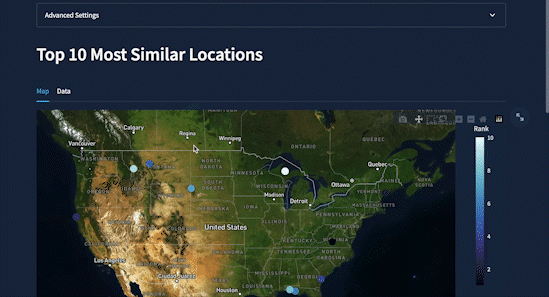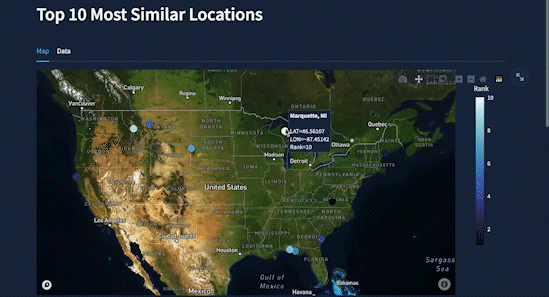
I also added the ability to save searches and carry out further research. While the app generates similar locations, it makes a table with a free-form text field. You can manipulate it and download it as a CSV file.
To implement this feature, use the experimental data editor function:
edited_df=st.experimental_data_editor(df)
save=edited_df[edited_df['SAVE']==True].reset_index()
csv = convert_df(save[cols+['SAVE','NOTES']])
st.download_button(label="Download Selections as CSV",data=csv,file_name='SIMILO_SAVED.csv',mime='text/csv',)

Now let's find and apply the analytical methods to make the machine work!
3. Methods to your madness
If you love learning new methods and adding them to your tool belt, you'll enjoy this step the most. I most definitely did, as I had to learn similarity scoring methods to answer these two questions:
Which key metrics represented a location and could be used for comparison? I combed through my datasets, selected 20, and split them into four categories: People, Home, Work, and Environment.
How to prepare the data, calculate similarity, and present the results to the user? I tried many iterations with different data transformations and similarity methods, including Euclidean distance, Cosine, and Jaccard similarity, and settled on a 3-step process for each:
- Normalize the values for each metric, putting them on the same scale.
- Calculate the Euclidean distance between those values for a selected location and the values for every other location in your dataset.
- Scale the calculated distances into a score from 1-100, creating an easy-to-interpret similarity ranking for each data category.
#Columns to normalize
people_cols_to_norm = [‘A’,’B’,’C’,’D’,’E’]
#New columns
scaled = ['A_sc','B_sc','C_sc','D_sc','E_sc']
#Normalization
scaler = StandardScaler()
df[scaled] = scaler.fit_transform(df[people_cols_to_norm])
#Calculate the euclidian distance between the selected record and the rest of the dataset
people_dist = euclidean_distances(df.loc[:,scaled], selected_record[scaled].values.reshape(1, -1))
#Create a new dataframe with the similarity score and the corresponding index of each record
df_similarity = pd.DataFrame({'PEOPLE_SIM': people_dist [:, 0], 'index': df.index})
#scale distance to 1-100 score
people_max=df_similarity['PEOPLE_SIM'].max()
df_similarity['PEOPLE_SCORE'] = 100 - (100 * df_similarity['PEOPLE_SIM'] / people_max)
At this point, you have four similarity scores ranging from 1-100 for each data category and location: People, Home, Work, and Environment.
To have a single comparison metric create an overall similarity score calculated as a weighted average of the individual category distances, scaled to a score from 1-100. Now you have an easy-to-interpret way to rank locations based on their similarity to the user's selected location:
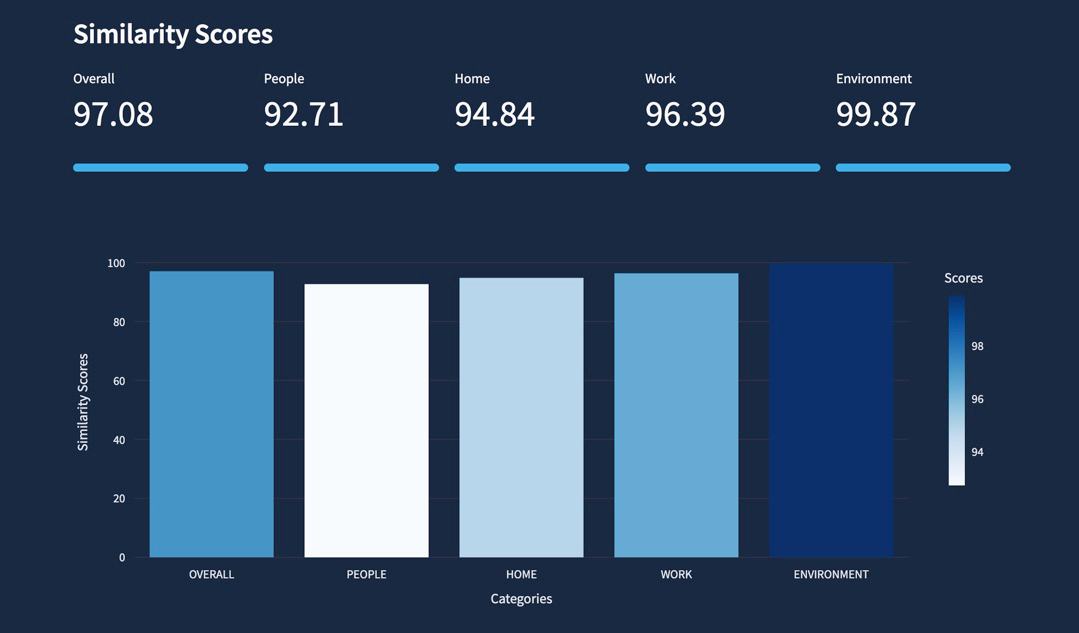
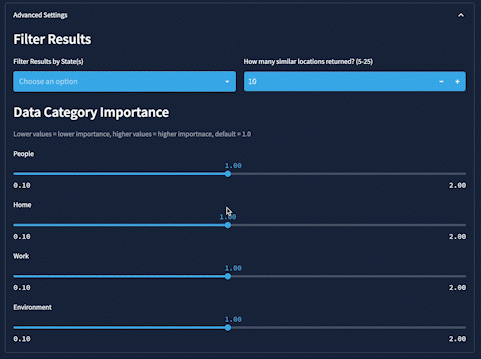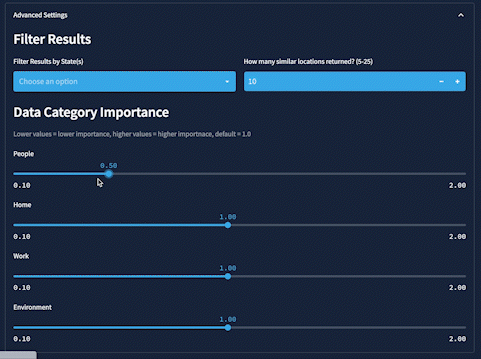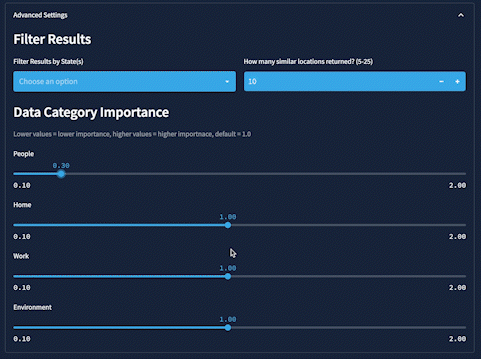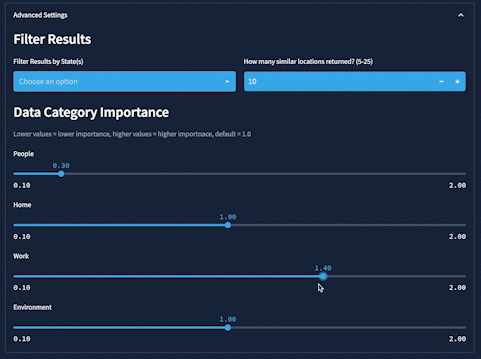
Oh, and one more thing. In Advanced Settings, in the Data Category Importance section, users can increase or decrease the impact of any individual data category using slider widgets. These adjustments dynamically update the weights of each category, which are used to calculate the overall similarity score:
Well done! You have learned how to build the app. But don't forget about design.
4. Delight with your design
Let's face it. Many of us data scientists lack free-spirited creativity. We're logical and analytical and don't often use the right side of our brain. Streamlit allows you to flex those forgotten muscles and your artistic side. Plus, neat organization and minimalism will make your app look simple, even if it's hiding lots of information and complex algorithms.
4. 1. Keep it organized
To help users process different pieces of information one at a time and keep it organized, use containers and dividers:

4.2. Display minimal information
To avoid overwhelming the user, display minimal information on the main search page. The user will see the extended workflow ONLY after making a selection. Present the data in separate tabs with the options and the instructions hidden behind expanders so the user can uncover information in small increments vs. all at once.
4.3. Avoid redundant features
To avoid redundant features, mix up the input widgets: buttons, radio buttons, checkboxes, selectboxes, multiselects, sliders, and number inputs. Streamlit offers diverse components for creating a unique app—explore the different layouts and get creative!
4.4. Create a custom color scheme
Create a custom color scheme to delight users with your app's aesthetics. Using the same color scheme for multiple apps can make them look alike (for SimiLo, I experimented with dozens of hex color code combinations). Simply use config.toml file functionality to control the background, the chart color scales, and the font colors:
[theme]
primaryColor="#3fb0e8"
backgroundColor="#192841"
secondaryBackgroundColor="#3fb0e8"
textColor="#f9f9f9"
4.5. Improve your app's design
To improve your app's design even further, embed animations or videos. This adds a level of professionalism that doesn't go unnoticed. I embedded a tutorial video with animations from LottieFiles, an open-source animation file format that you can add to Streamlit (learn more here):
Now you have a fully functional, beautiful app. Time to publish? Not so fast. Don't forget to check your ethics!
5. Don't forget your ethics
You might wonder why you should check your ethics when you know you're a good person with good morals and intentions. Well, good for you. The question is not about YOUR ethics; it's about you mitigating the possibility of your app being USED unethically.
In the case of SimiLo, I made two critical decisions:
- App's functionality. Should I let the user hand-select the criteria and get a list of locations, or should I let them first pick a location and get a list of comparisons? Choosing the latter helped close the door to some unethical use cases. For example, I didn't want to create an app where someone could pick locations based on the race or income of its inhabitants.
- The data used in the app. I purposefully omitted some demographic data, such as race, because it didn't add value and opened the door for unethical use. I carefully considered what data to show and what elements to use in my similarity scoring process.
There is a lot of buzz about the ethical use of AI. I believe that data scientists are key players in promoting ethical use and preventing unethical use because they understand their product the best. Third-party risk teams often don't have the domain knowledge about the methods or data to properly evaluate ta data science solution'sfairness, bias, and ethics. So before you hit publish, think about how your app COULD be used, not just how it SHOULD be used—you might find some open doors worth shutting. 🚪
Wrapping up
Let's summarize the 5-step process I used to build SimiLo. Once I defined the problem (I wanted to move) and expanded my proposed solution (moving, vacationing, market research), I started with Step 1—data wrangling and data sourcing with ChatGPT, exploratory data analysis (EDA), cleaning, transformations, and feature engineering. In Step 2, I hit the whiteboard and strategized the app components from the users' perspective. Step 3 was researching and applying similarity scoring methods in a framework that worked best for my app. Step 4 was to make my app look and feel appealing through various design strategies. Finally, in Step 5, I checked the ethical considerations before publishing.
Just because this article is linear doesn't mean real life is. You don't need to do these steps in order. In some cases, you can do them in tandem, in others, as part of an iterative rotation, but in most cases, you'll revisit each step several times.
I hope this post helped you find a gem or two to take to your next app. If you have any questions, please post them in the comments below or contact me on LinkedIn or Twitter.
Happy Streamlit-ing! 🎈




Comments
Continue the conversation in our forums →