
Retrieval Augmented Generation (RAG) is essential for enhancing large language models (LLMs) in app development. It supplements LLMs with external data sources, helping arrive at more relevant responses by reducing errors or hallucinations. RAG determines what info is relevant to the user’s query through semantic search, which searches data by meaning (rather than just looking for literal matches of search terms). RAG is particularly effective for LLM apps that need to access domain-specific or proprietary data.
However, RAG alone isn’t always enough to build powerful, context-aware LLM apps. Enhancing RAG with time-aware retrieval, which finds semantically relevant vectors within specific time and date ranges, can significantly improve its effectiveness.
Before vs. after time-aware retrieval
When dealing with a date-heavy knowledge base, time-aware RAG can help you build LLM apps that excel at generating relevant answers to user queries.
In this example, see how time-aware retrieval improves the quality of LLM responses:
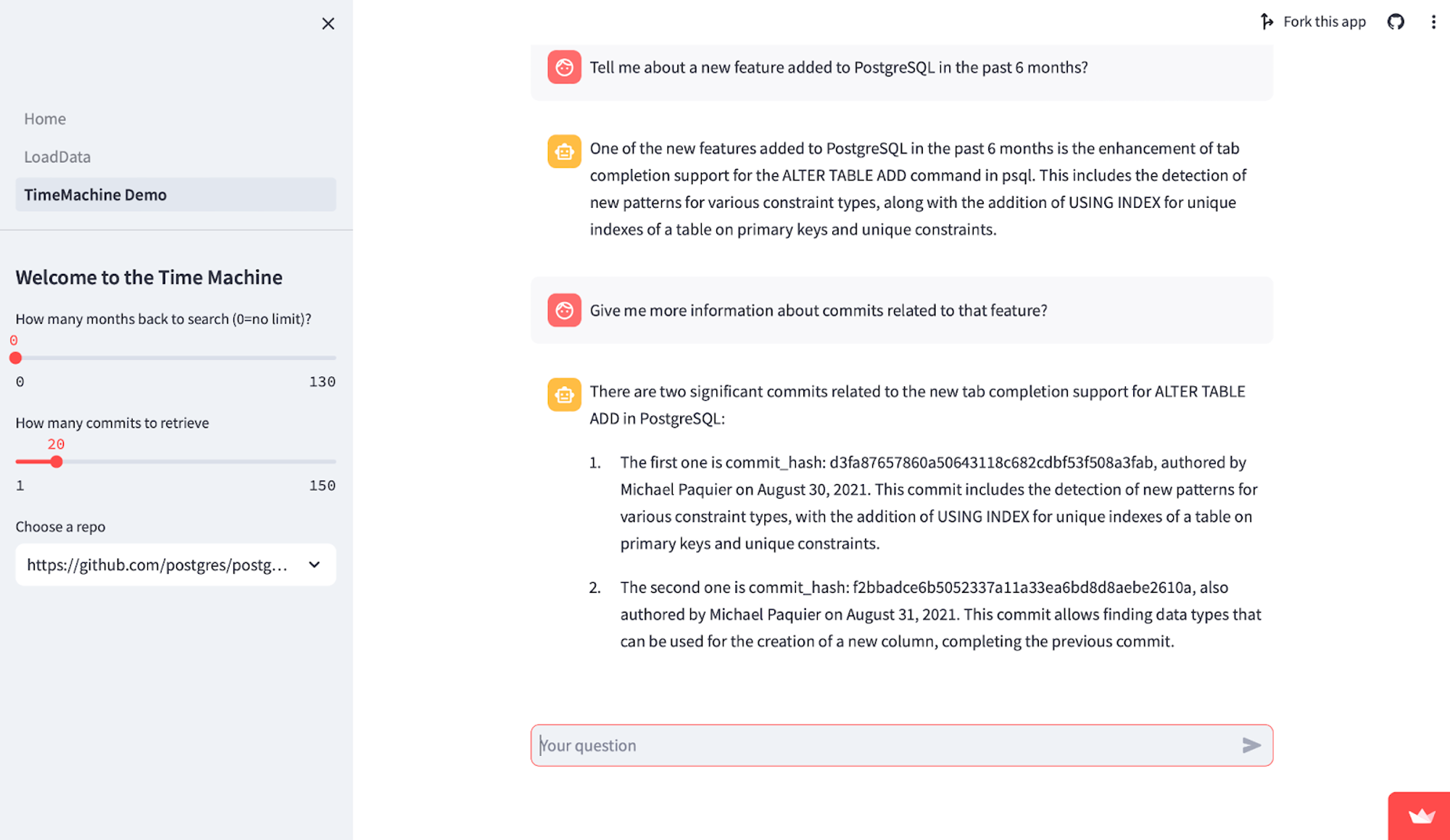
Alice is a developer that wants to learn about specific changes to a GitHub repo (in this case, the TimescaleDB repo). Rather than manually inspect the code or commit history, she finds a “Chat with my GitHub repo” application and uses it to expedite her research. Alice wants to learn about recent changes to a feature named “continuous aggregates” and asks the following question on 29 November 2023:
What's new with the continuous aggregates feature in the past 6 months?LLM response without time-aware RAG 👎
The feature named continuous aggregates has undergone some changes. The most recent change was made by Sven Klemm on January 24, 2020. This change added a new mode called real-time aggregates, which combines materialized data with new data received after the last refresh. This new mode is now the default behavior for newly created continuous aggregates. To upgrade existing continuous aggregates to the new behavior, a specific command needs to be run.
LLM response with time-aware RAG ✅
In the past 6 months, there have been two changes made to the feature named continuous aggregates. The first change was made on August 7, 2023, by Fabrízio de Royes Mello. This change relaxed the strong table lock when refreshing a continuous aggregate, allowing the refresh procedure to be executed in multiple sessions with fewer locks. The second change was made on August 29, 2023, by Jan Nidzwetzki. This change made the up/downgrade test deterministic by adding an ORDER BY specification to two queries in post.continuous_aggs.v3.sql.
The response using time-aware RAG is much more useful — it’s within Alice’s specified time period and is topically relevant. The difference between the two responses is the retrieval step.
Tutorial: Build a chatbot about GitHub commit history
Now it's your turn! In the rest of this post, we'll walk through the process of building TSV Time Machine: a time-aware RAG chatbot that enables you to go back in time and chat with the commit history of any GitHub repository.
Each Git commit has an associated timestamp, a natural language message, and other metadata, meaning that both semantic and time-based search are needed to answer questions about the commit history.
Overview of TSV Time Machine app
To power TSV Time Machine, we use the following:
- LlamaIndex is a powerful LLM data framework for RAG applications. LlamaIndex ingests, processes, and retrieves data. We’ll use the LlamaIndex autoretriever to infer the right query to run on the vector database, including both the query string and metadata filters.
- Timescale Vector is our vector database. Timescale Vector has optimizations for similarity and time-based search, making it ideal to power the time-aware RAG. It does this through automatic table partitioning to isolate data for particular time ranges. We will access it through LlamaIndex’s Timescale Vector Store.
The TSV Time Machine sample app has three pages:
- Home: homepage of the app that provides instructions on how to use the app.
- Load Data: page to load the Git commit history of the repo of your choice.
- Time Machine Demo: interface with chat with any of the GitHub repositories loaded.
Since the app is ~600 lines of code, we won’t unpack it line by line (although you can ask ChatGPT to explain any tricky parts to you!). Let’s take a look at the key code snippets involved in:
- Loading data from the GitHub repo you want to chat with
- Powering chat via time-aware retrieval augmented generation
Part 1: Load time-based data with Timescale Vector and LlamaIndex
Input the URL of a GitHub repo you want to load data for and TSV Time Machine uses LlamaIndex to load the data, create vector embeddings for it, and store it in Timescale Vector.
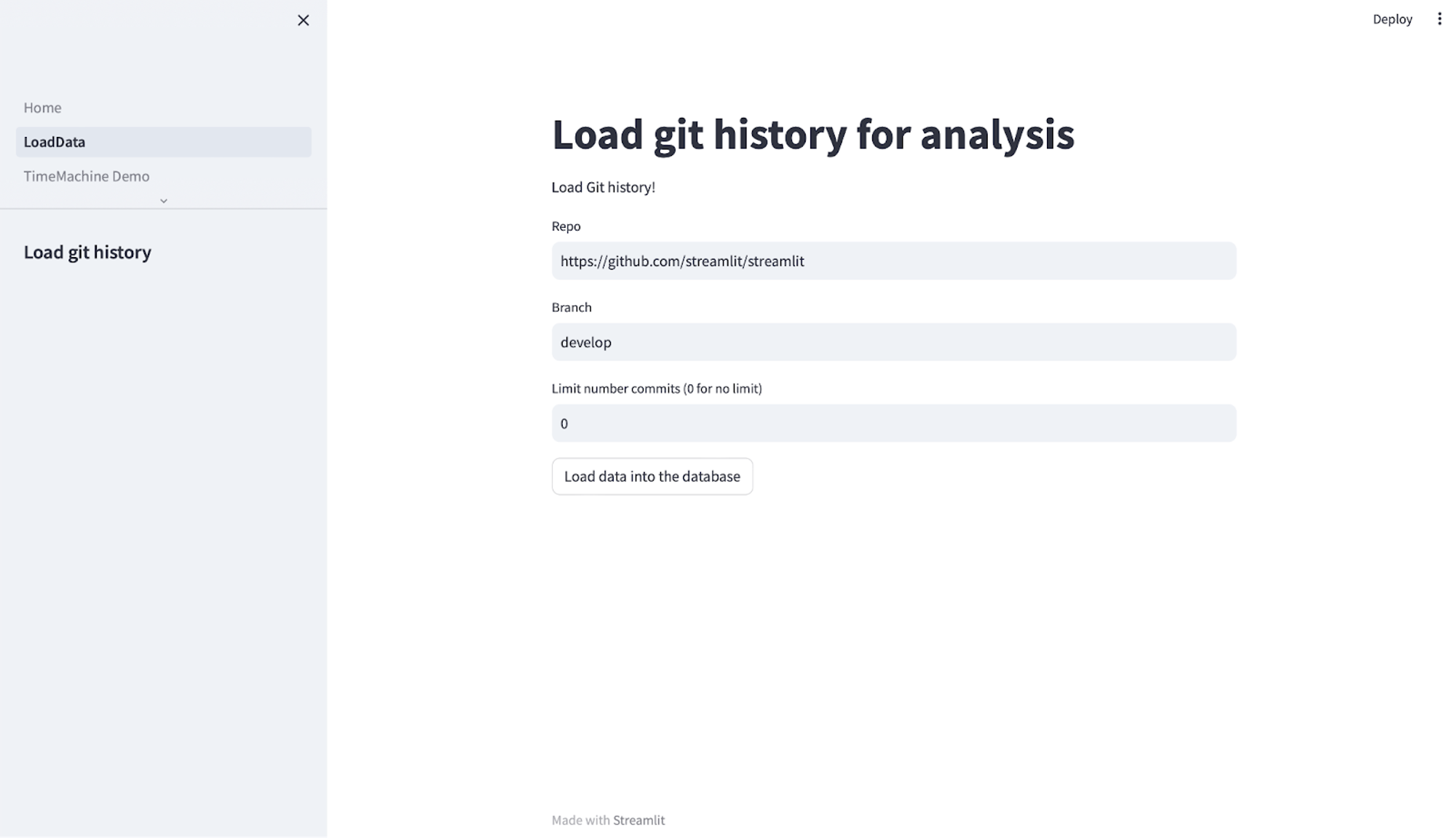
In the file 0_LoadData.py , we fetch data from a GitHub repository of your choice, create embeddings for it using OpenAI’s text-embedding-ada-002 model and LlamaIndex, and store it in tables in Timescale Vector. The tables contain the vector embedding, the original text, and metadata associated with the Git commit, including a UUID which reflects the timestamp of the commit.
First, we define a load_git_history() function. This function will ask the user to input the GitHub repo URL, branch, and number of commits to load via a st.text_input element. Then it will will fetch the Git commit history for the repo, use LlamaIndex to embed the commit history text and turn them into LlamaIndex nodes, and insert the embeddings and metadata into Timescale Vector:
# Load git history into the database using LlamaIndex
def load_git_history():
repo = st.text_input("Repo", "<https://github.com/postgres/postgres>")
branch = st.text_input("Branch", "master")
limit = int(st.text_input("Limit number commits (0 for no limit)", "1000"))
if st.button("Load data into the database"):
df = get_history(repo, branch, limit)
table_name = record_catalog_info(repo)
load_into_db(table_name, df)
Function for loading Git history from a user defined URL. Defaults to the PostgreSQL project.
While the full code for the helper functions get_history(), record_catalog_info(), and load_into_db() is in the sample app repo, here’s an overview:
get_history(): fetches the repo’s Git history and stores it in a Pandas DataFrame. We fetch the commit hash, author name, date of commit, and commit message.record_catalog_info(): creates a relational table in our Timescale Vector database to store the information of the loaded GitHub repositories. The repo URL and the name of the table commits are stored in the database.load_into_db(): creates a TimescaleVectorStore in LlamaIndex to store our embeddings and metadata for the commit data.- We set the
time_partition_intervalparameter to 365 days. This parameter represents the length of each interval for partitioning the data by time. Each partition will consist of data for the specified length of time.
# Create Timescale Vectorstore with partition interval of 1 year
ts_vector_store = TimescaleVectorStore.from_params(
service_url=st.secrets["TIMESCALE_SERVICE_URL"],
table_name=table_name,
time_partition_interval=timedelta(days=365),
)This example uses 365 days as the partition interval, but pick the value that makes sense for your app’s queries.
For example, if you frequently query recent vectors, use a smaller time interval (e.g. one day). If you query vectors over a decade-long time period, use a larger interval (e.g. six months or one year).
Most queries should touch only a couple of partitions and your full dataset should fit within 1,000 partitions.
Once we’ve created our TimescaleVectorStore, we create LlamaIndex TextNodes for each commit and create embeddings for the content of each node in batches.
create_uuid() creates a UUID v1 from the commit’s datetime associated with the node and vector embedding. This UUID enables us to efficiently store the nodes in partitions by time and query embeddings according to their partition.
# Create UUID based on time
def create_uuid(date_string: str):
datetime_obj = datetime.fromisoformat(date_string)
uuid = client.uuid_from_time(datetime_obj)
return str(uuid)Creating a UUID v1 with a time component helps power similarity search on time. We use the uuid_from_time() function found in the Timescale Vector Python client to help us.
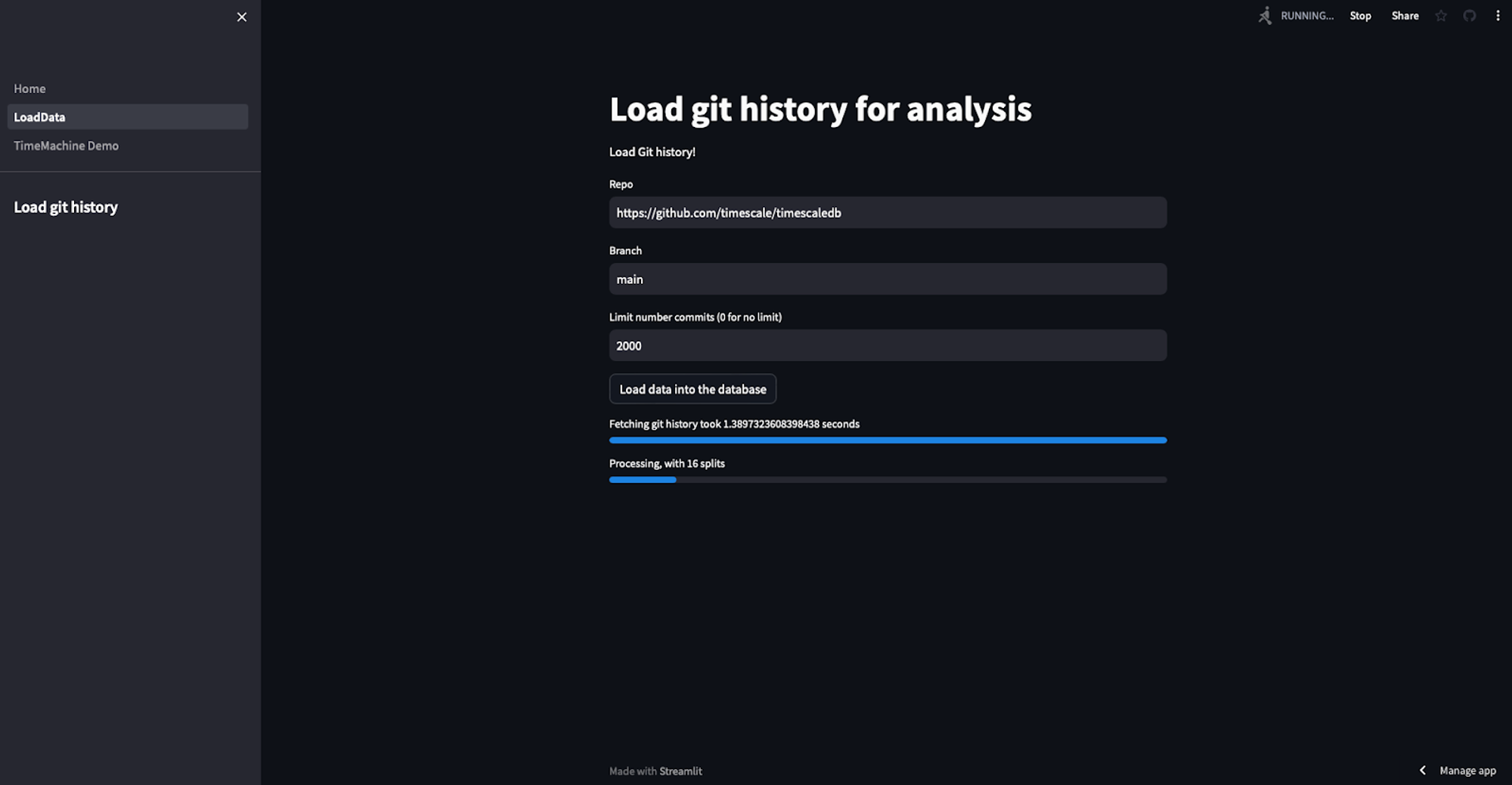
Finally, we create a TimescaleVectorIndex, which will allow us to do fast similarity search and time-based search for time-aware RAG. We use st.spinner and st.progress to show load progress.
st.spinner("Creating the index...")
progress = st.progress(0, "Creating the index")
start = time.time()
ts_vector_store.create_index()
duration = time.time()-start
progress.progress(100, f"Creating the index took {duration} seconds")
st.success("Done")Part 2: Build the chatbot
In the file 1_TimeMachineDemo.py, we use LlamaIndex’s auto-retriever to answer user questions by fetching data from Timescale Vector to use as context for GPT-4.
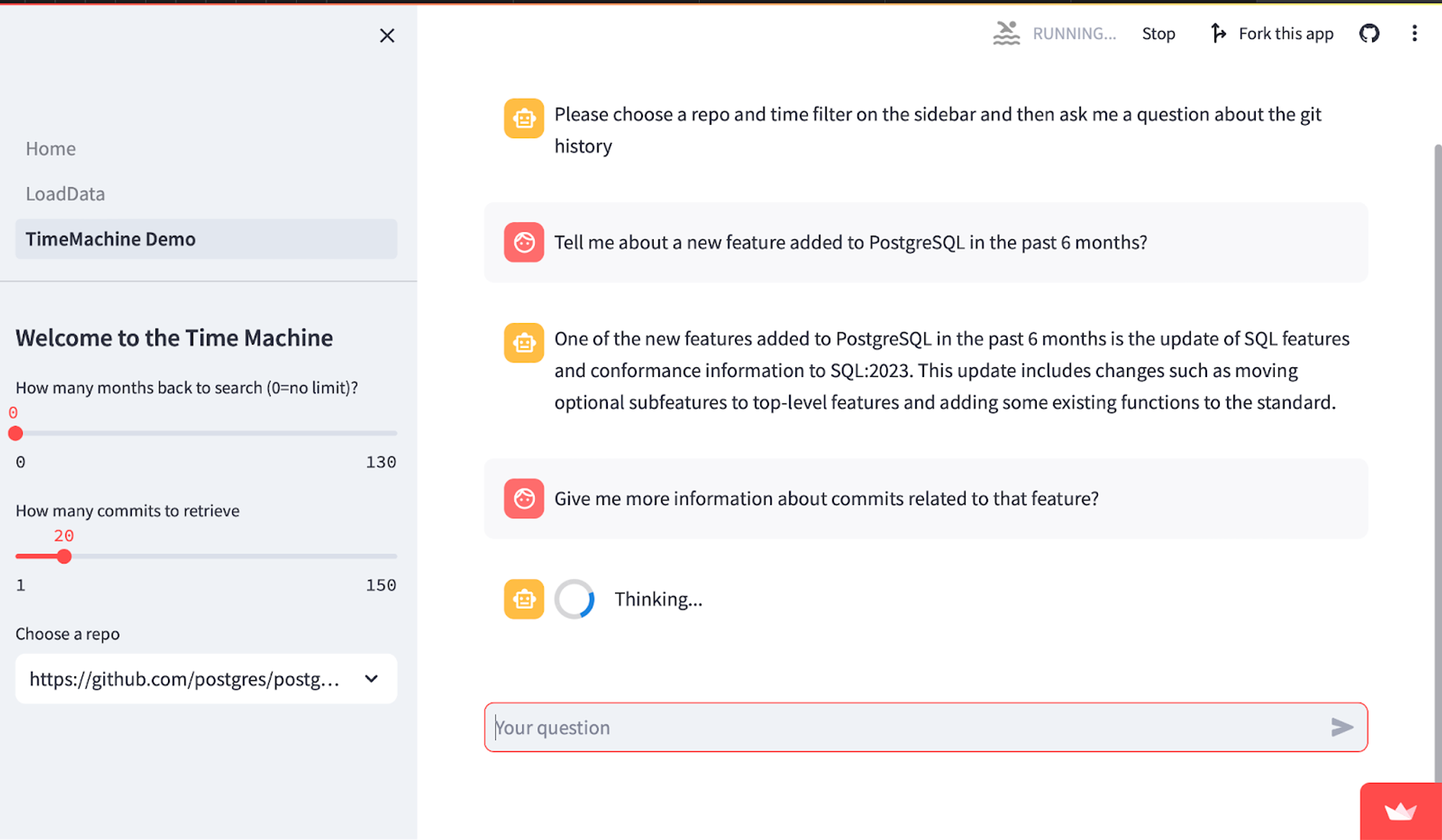
Here’s an overview of the key functions:
get_repos(): Fetches list of available GitHub repos you’ve loaded that you can chat with, so you can easily switch between them in the side bar.get_autoretriever(): Creates a LlamaIndex auto-retriever from the TimescaleVectorStore, which gives GPT-4 the ability to form vector store queries with metadata filters. This enables the LLM to limit answers to user queries to a specific timeframe.- For example, the query: “What new features were released in the past 6 months” will only search partitions in Timescale Vector that contain data between now and 6 months ago, and fetch the most relevant vectors to be used as context for RAG.
# Creates a LlamaIndex auto-retriever interface with the TimescaleVector database
def get_auto_retriever(index, retriever_args):
vector_store_info = VectorStoreInfo(
# Note: Modify this to match the metadata of your data
content_info="Description of the commits to PostgreSQL. Describes changes made to Postgres",
metadata_info=[
MetadataInfo(
name="commit_hash",
type="str",
description="Commit Hash",
),
MetadataInfo(
name="author",
type="str",
description="Author of the commit",
),
MetadataInfo(
name="__start_date",
type="datetime in iso format",
description="All results will be after this datetime",
),
MetadataInfo(
name="__end_date",
type="datetime in iso format",
description="All results will be before this datetime",
)
],
)
retriever = VectorIndexAutoRetriever(index,
vector_store_info=vector_store_info,
service_context=index.service_context,
**retriever_args)
# build query engine
query_engine = RetrieverQueryEngine.from_args(
retriever=retriever, service_context=index.service_context
)
# convert query engine to tool
query_engine_tool = QueryEngineTool.from_defaults(query_engine=query_engine)
chat_engine = OpenAIAgent.from_tools(
tools=[query_engine_tool],
llm=index.service_context.llm,
verbose=True,
service_context=index.service_context
)
return chat_enginevector_store_infoprovides the LLM with info about the metadata so that it can create valid filters for fetching data in response to user questions. If you’re using your own data (different from Git commit histories), you’ll need to modify this method to match your metadata.__start_dateand__end_dateare special filter names used by Timescale Vector to support time-based search. If you’ve enabled time partitioning in Timescale Vector (by specifying thetime_partition_intervalargument when creating the TimescaleVectorStore), you can specify these fields in theVectorStoreInfoto enable the LLM to perform time-based search on each LlamaIndex Node’s UUID.- The
chat_enginereturned is an OpenAIAgent which can use the QueryEngine tool to perform tasks — in this case, answer questions about GitHub repo commits. tm_demo()handles the chat interaction between the user and LLM. It provides anst.sliderelement for the user to specify the time period and number of commits to fetch. It then prompts the user for input, processes that input usingget_autoretriever(), and displays the chat messages. Check out this method in the GitHub repo.
Deployment
☁️ On Streamlit Community Cloud
- Fork and clone this repository.
- Create a new cloud PostgreSQL database with Timescale Vector (sign up for an account here). Download the cheatsheet or
.envfile containing the database connection string. - Create a new OpenAI API key to use in this project, or follow these instructions to sign up for an OpenAI developer account to obtain one. We’ll use OpenAI’s embedding model to generate text embeddings and GPT-4 as the LLM to power our chat engine.
- In Streamlit Community Cloud:
- Click
New app, and pick the appropriate repository, branch, and file path. - Click
Advanced Settingsand set the following secrets:
OPENAI_API_KEY=”YOUR_OPENAI_API KEY”
TIMESCALE_SERVICE_URL=”YOUR_TIMESCALE_SERVICE_URL”
ENABLE_LOAD=1
- Hit
Deploy.
And you’re off to the races!
💻 On your local machine
- Create a new folder for your project, then follow steps 1-3 above.
- Install dependencies. Navigate to the
tsv-timemachinedirectory and run the following command in your terminal, which will install the python libraries needed:
pip install -r requirements.txt
- In the
tsv-timemachinedirectory, create a new.streamlitfolder and create asecrets.tomlfile that includes the following:
OPENAI_API_KEY=”YOUR_OPENAI_API KEY”
TIMESCALE_SERVICE_URL=”YOUR_TIMESCALE_SERVICE_URL”
ENABLE_LOAD=1
Example TOML file with Streamlit secrets. You’ll need to set these to embed and store data using OpenAI and Timescale Vector.
- To run the application locally, enter the following in the command line:
streamlit run Home.py
🎉 Congrats! Now you can load and chat with the Git commit history of any repo, using LlamaIndex as the data framework, and Timescale Vector as the vector database.
The Git commit history can be substituted for any time-based data of your choice. The result is an application that can efficiently perform RAG on time-based data and answer user questions with data from specific time periods.
How will you use time-based retrieval?
Building on the example above, here are a few examples of use cases unlocked by time-aware RAG:
- Similarity search within a time range: filter documents by create date, publish date, or update date when chatting with a corpus of documents.
- Find the most recent embeddings: find the most relevant and recent news or social media posts about a specific topic.
- Give LLMs a sense of time: leverage tools like LangChain’s self-query retriever or LlamaIndex’s auto-retriever to ask time-based and semantic questions about a knowledge base of documents.
- Search and retrieve chat history: search a user’s prior conversations to retrieve details relevant to the current chat.
Wrapping up
You learned that time-aware RAG is crucial to build powerful LLM apps that deal with time-based data. You also used Timescale Vector and LlamaIndex to construct a time-based RAG pipeline, resulting in a Streamlit chatbot capable of answering questions about a GitHub commit history or any other time-based knowledge base.
Learn more about Timescale Vector from our blog and dive even deeper on time-aware RAG in our webinar with LlamaIndex. Take your skills to the next level by creating your own Streamlit chatbot using time-based RAG and your data stored in Timescale.
Don't forget to share your creations in the Streamlit forum and on social media.
Happy Streamlit-ing! 🎈




Comments
Continue the conversation in our forums →