
Do you see this page instead of your beautiful Streamlit app? 👇
Sorry! This message means you've hit the 1GB resource limit of apps hosted with Streamlit Community Cloud. Luckily, there are a few things you can change to make your app less resource-hungry, as well as a number of other platforms that you can use to host your Streamlit app.
In this post, we'll go through some tips on how to fix the most common issues.
What are the resource limits?
As of August 2021, apps on the free Community tier of the Streamlit Cloud are limited by:
- Memory (RAM)
- CPU
- Disk storage
Based on our research, most of the time apps run over the resource limits because of memory. In particular, you might have a memory leak.
Let's look at some tips for how to handle those leaks.
Tip 1: Reboot your app (temporary fix)
If you need to restore access to your app immediately, reboot your app. This resets all memory, CPU, and disk usage. While logged into Streamlit Cloud, visit your app and click on Manage app in the bottom right corner. Now click on the three dots in the sidebar and then on Reboot app.
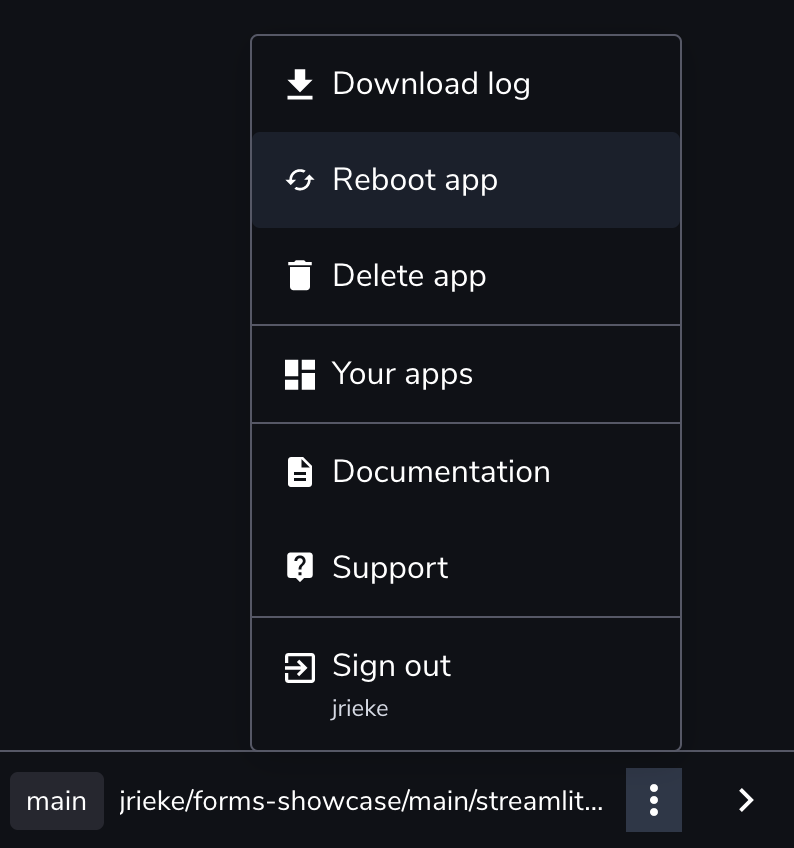
NOTE: Rebooting can only fix your app temporarily!
If there's a problem or memory leak in your app, it will soon run over the resource limits again. So make sure you read the tips below to fix any deeper issues!
Tip 2: Use st.cache to load models or data only once
This is by far the most common issue we see. Apps load a memory-intensive machine learning model or dataset directly in the main Python script, e.g. like this:
import streamlit as st
import torch
# Load the model.
model = torch.load("path/to/model.pt")
# Perform a prediction.
question = st.text_input("What's your question?")
answer = model.predict(question)
st.write("Predicted answer:", answer)
Recall that in Streamlit's execution model, the script is rerun each time a viewer interacts with an app. That means the model above is loading from scratch every time!
In most cases, this isn't a huge problem (old objects are regularly cleared from memory, and we recently introduced a fix to do this even better!) – it just makes your app a bit slower. However, we find that some libraries that manage their memory outside of Python (e.g. Tensorflow) do not release memory in a timely manner, especially in a threaded environment like Streamlit. Old objects add up in memory, and you hit the resource limits. 😕
But there's a trivial fix. You can use st.cache to ensure memory-intense computations run only once. Here's how you would fix the code above:
import streamlit as st
import torch
# Load the model (only executed once!)
# NOTE: Don't set ttl or max_entries in this case
@st.cache
def load_model():
return torch.load("path/to/model.pt")
model = load_model()
# Perform a prediction.
question = st.text_input("What's your question?")
answer = model.predict(question)
st.write("Predicted answer:", answer)
Now, the model is only loaded the first time your app runs. This saves memory and also makes your app a bit faster. You can read more about caching in the docs.
There is one caveat. For proper caching, Streamlit needs to hash the input and output values of the cached function. But ML models, database connections, and similar objects are often not easily hashable! This can result in an UnhashableTypeError. For our use case (i.e. loading a complex object at startup), you can disable hashing for this object byusing the hash_funcs argument (more info here):
@st.cache(hash_funcs={"MyUnhashableClass": lambda _: None}
If this sounds daunting, fear not! We're working on improvements to caching that will make the above steps obsolete through a new caching API. In the meantime, if you need help setting this up, feel free to ask us in our forums.
Tip 3: Restrict the cache size with ttl or max_entries
Are you a Streamlit expert who already uses st.cache to run ML models or process API requests? That's fantastic! But did you remember to configure the cache's expiration policy? When not configured, the cache can fill up over time, using more and more memory. And you're back in "Over capacity" land. 😕
st.cache offers two parameters to prevent this:
ttlcontrols the cache's Time To Live, i.e. how long an object stays in the cache before it gets removed (in seconds).max_entriescontrols the maximum number of objects in the cache. If more elements get added, the oldest ones are automatically removed.
You can only set one of these at a time.
If your Streamlit app uses caching, it is best practice to set up one of these options. The main exception to this is the case shown in Tip 2, where you're using the cache to load a given object as a singleton (i.e. load it exactly once).
Here's an example of how you can use ttl:
import streamlit
# With `ttl`, objects in cache are removed after 24 hours.
@st.cache(ttl=24*3600)
def api_request(query):
return api.run(query)
query = st.text_input("Your query for the API")
result = api_request(query)
st.write("The API returned:", result)
Tip 4: Move big datasets to a database
Is your app using or downloading big datasets? This can quickly fill up memory or disk space and make your app slow for viewers. It's usually a good idea to move your data to a dedicated service, e.g.:
- A database like Firestore or BigQuery
- A file hosting service like AWS S3
- A Google Sheet (an easy option for prototypes with limited data!)
Our docs offer a range of guides on connecting to different data services, and we keep adding more! Spoiler alert: We're also thinking about having a built-in st.database in the future. 😉
Want to keep your data local but still save memory? There's good news. Streamlit recently introduced support for Apache Arrow. This means you can store your data on disk with Arrow and read it in the app directly from there. This consumes a lot less memory than reading from CSV or similar file types.
Tip 5: Profile your app's memory usage
Still struggling with memory usage? Then it may be time to start a deeper investigation and track your app's memory usage.
A helpful tool is the psrecord package. It lets you plot the memory & CPU usage of a process. Here's how to use it:
- Open the terminal on your local machine.
2. Install psrecord.
pip install psrecord
3. Start your Streamlit app.
streamlit run name_of_your_app.py
4. Find out the process ID (or PID) of the app, e.g. using the task manager in Windows or the activity monitor in OSX (the process running the app is usually called "Python").
On Mac or Linux, you can also run the command below. The PID is the first number you get:
ps -A | grep "streamlit run" | grep -v "grep"
5. Start psrecord, inserting the correct process ID from the step above for <PID>:
psrecord <PID> --plot plot.png
6. Interact with your Streamlit app. Trigger the most memory-consuming parts of your app (e.g. loading an ML model) and remember the sequence of the steps you took.
7. Kill the psrecord process (e.g. with ctrl + c).
This will write a plot like below to the file plot.png. You'll see how each action from step 6 affected your memory usage. It's helpful to do this a few times and test out different parts of your app to see where all that memory is going!
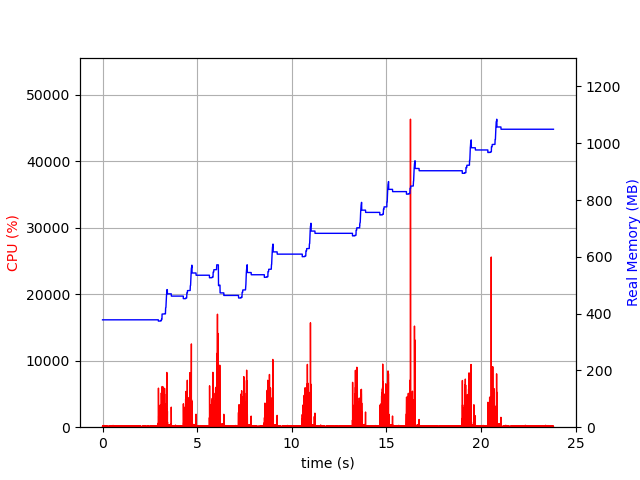
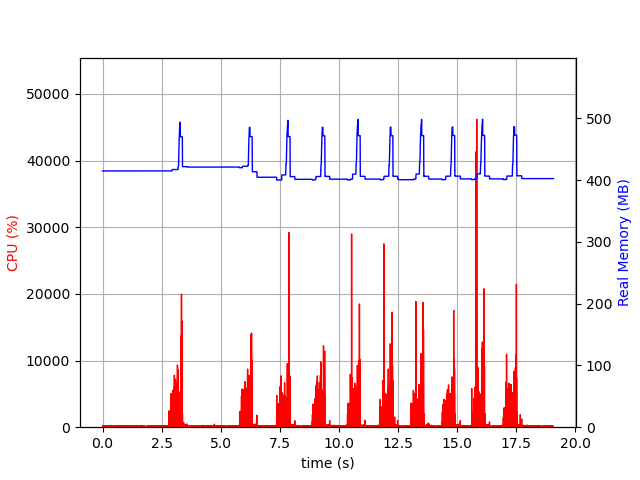
Here is what the memory profile of the app above looked like after applying Tip #2:
You can also use a more sophisticated memory profiler to show you exactly which line of code consumed the most memory. A great one for this purpose is Fil.
Nothing helps?
As with all debugging, sometimes you get stumped.
Maybe you have a use case that requires a lot of resources (e.g. you're loading an immense ML model). Or your app behaved well for a few concurrent users, but now it went viral. Or you think there's a bug somewhere, but can't figure out where. Or maybe you just need a rubber duck.
Please reach out! Post on the forum with a link to your app and what you've tried so far, and we'll take a look. 🎈
One more thing. If you have a special good-for-the-world case that needs more resources, submit this request form and we'll see about making an exception!


Comments
Continue the conversation in our forums →