Generative AI is moving at lightning speed ⚡️, and you don't want to blink. New LLMs brimming with exciting features consistently seize the headlines of my news feeds.
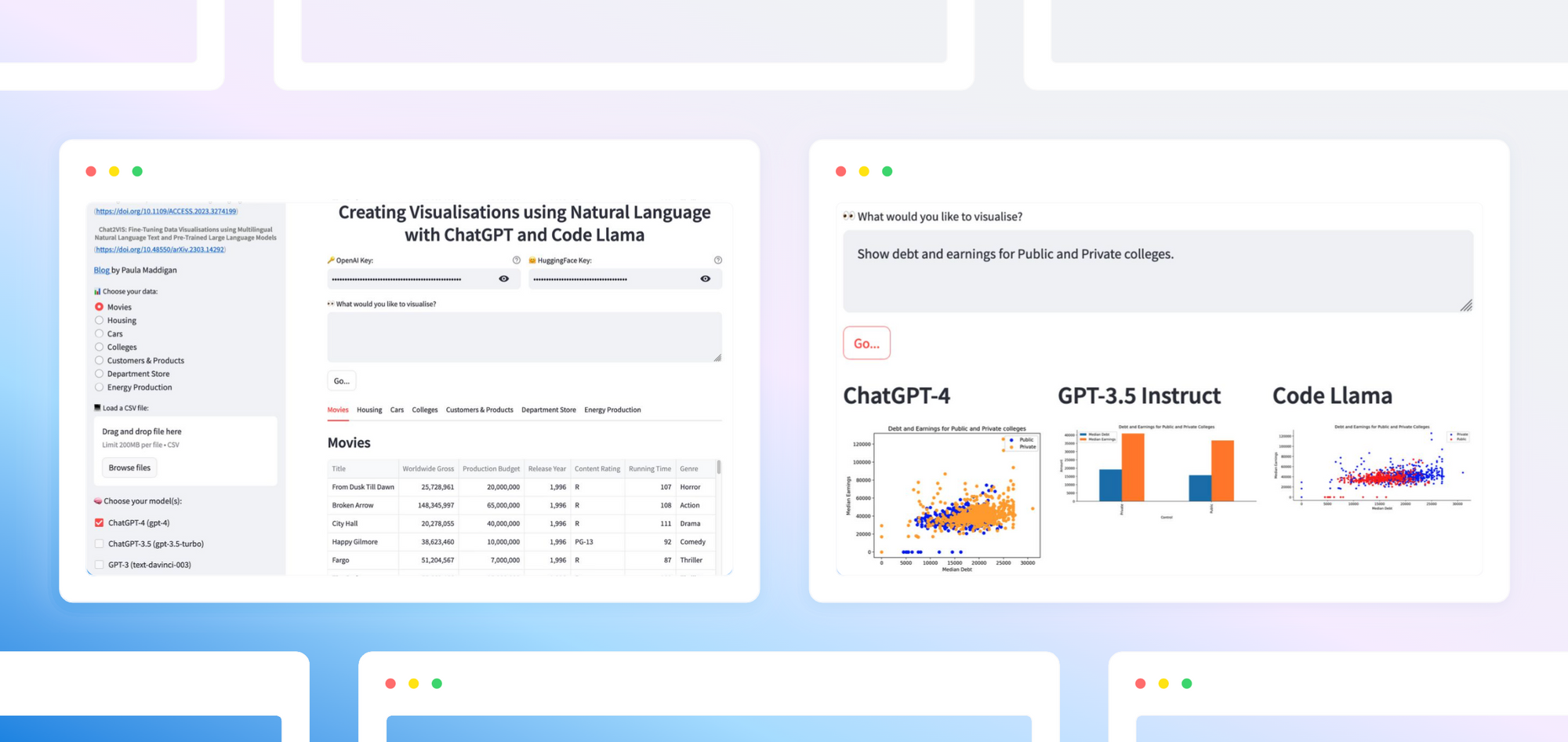
With Chat2VIS, you can use natural language to prompt up to 5 LLMs to generate Python code that builds plots from a dataset. (Learn more about why I built Chat2VIS from my journal article.)
I wanted to put 3 of the latest LLMs to the test, comparing their performance in generating code for various visualisations. From creating bar charts and time series data, to handling misspelled words and ambiguous prompts, I uncover how each model responds.
The results provide interesting insights into the strengths and limitations of these models, with a focus on Code Llama’s potential and the benefits of GPT-3.5 Instruct and GPT-4.
In this post, you'll discover:
- Why I chose to compare Code Llama vs. OpenAI models
- Six scenarios where Chat2VIS compares Code Llama, GPT-3.5 Instruct, and GPT-4 models
- Tip to improve success with open-source models
Why I chose to compare Code Llama and GPT models
Open source models, like Code Llama, are free to use, and easier to fine-tune on your own data. OpenAI models are easy to use “out of the box”, with some now available to fine-tune, but come with a cost. Historically, I’ve faced challenges using open source models, finding they often misunderstood the request or failed completely to generate accurate Python code.
When Code Llama was released, an LLM tuned for code generation, I was keen to see how it compared to the OpenAI models.
I've been impressed with Code Llama, which shows great potential for this task without incurring the cost associated with the OpenAI models (read more here).
I have opted for the "Instruct" fine-tuned variation of Code Llama. It aligns well with the existing prompt style, which issues instructions in natural language followed by the beginning of a Python code script.
Let's see how it stacks up against OpenAI's GPT-4 and their recent release of GPT-3.5 Instruct.
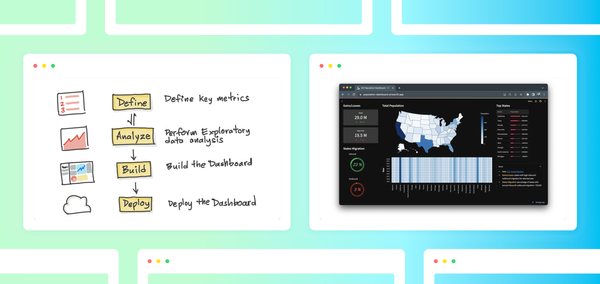
Quick overview of Chat2VIS
Before we begin comparing LLMs, here’s a look again at how Chat2VIS works (check out the full blog post to learn more.)
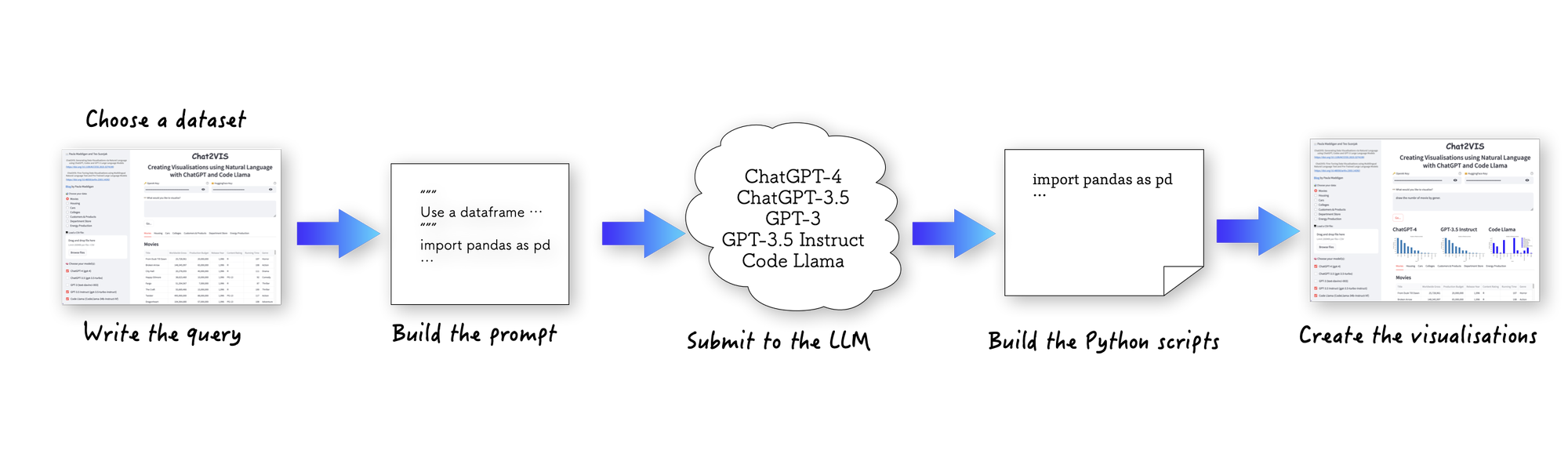
6 case studies using Chat2VIS to compare Code Llama vs. GPT-3.5 Instruct and GPT-4
Using Chat2VIS, I tested how each model performed based on 6 different scenarios.
For each example, choose the dataset from the sidebar radio button options, select the models using the checkboxes, and enter your API keys for OpenAI and HuggingFace.
Case study 1: Generate code for bar chart
This example uses the pre-loaded "Department Store" dataset.
Run the following query: "What is the highest price of product, grouped by product type? Show a bar chart, and display by the names in desc.”
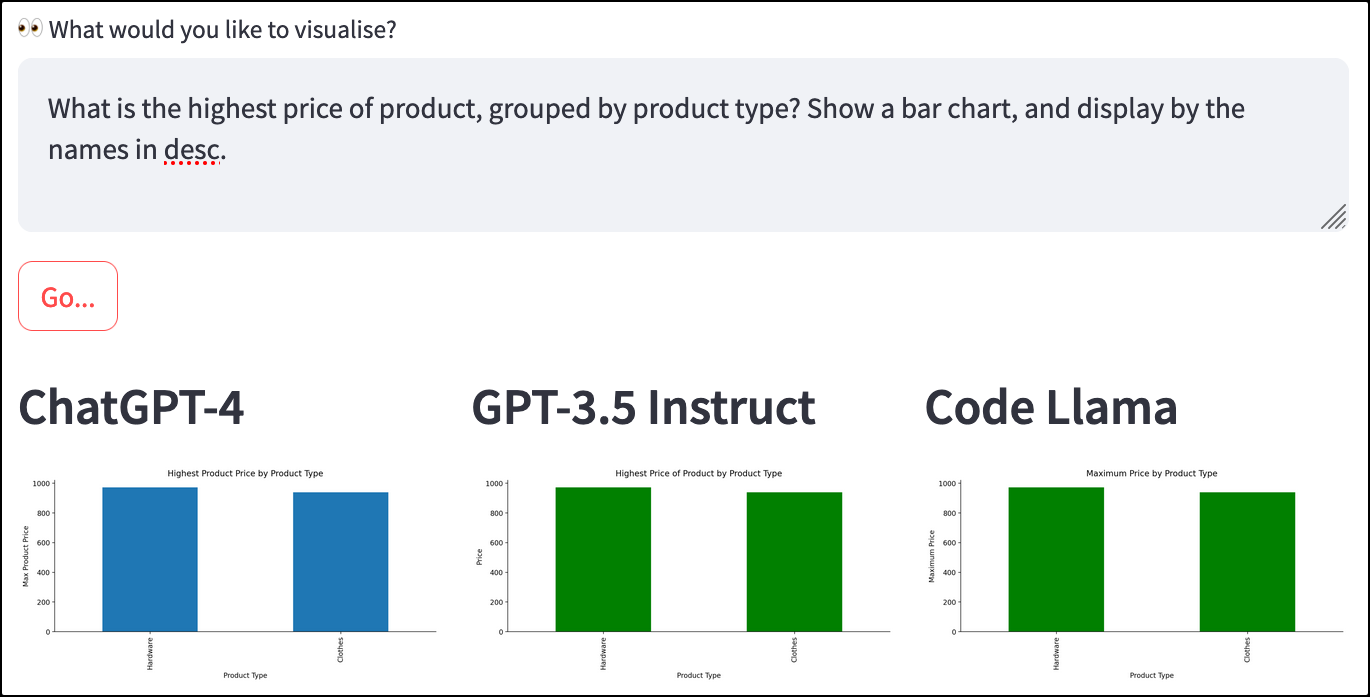
Kudos to all three models for producing the same results! (Even though they may have different labels and titles.)
- GPT-4 ✅
- Code Llama ✅
- GPT-3.5 Instruct ✅
Case study 2: Generate code for time series
Using the "Energy Production" dataset, run the query: "What is the trend of oil production since 2004?”
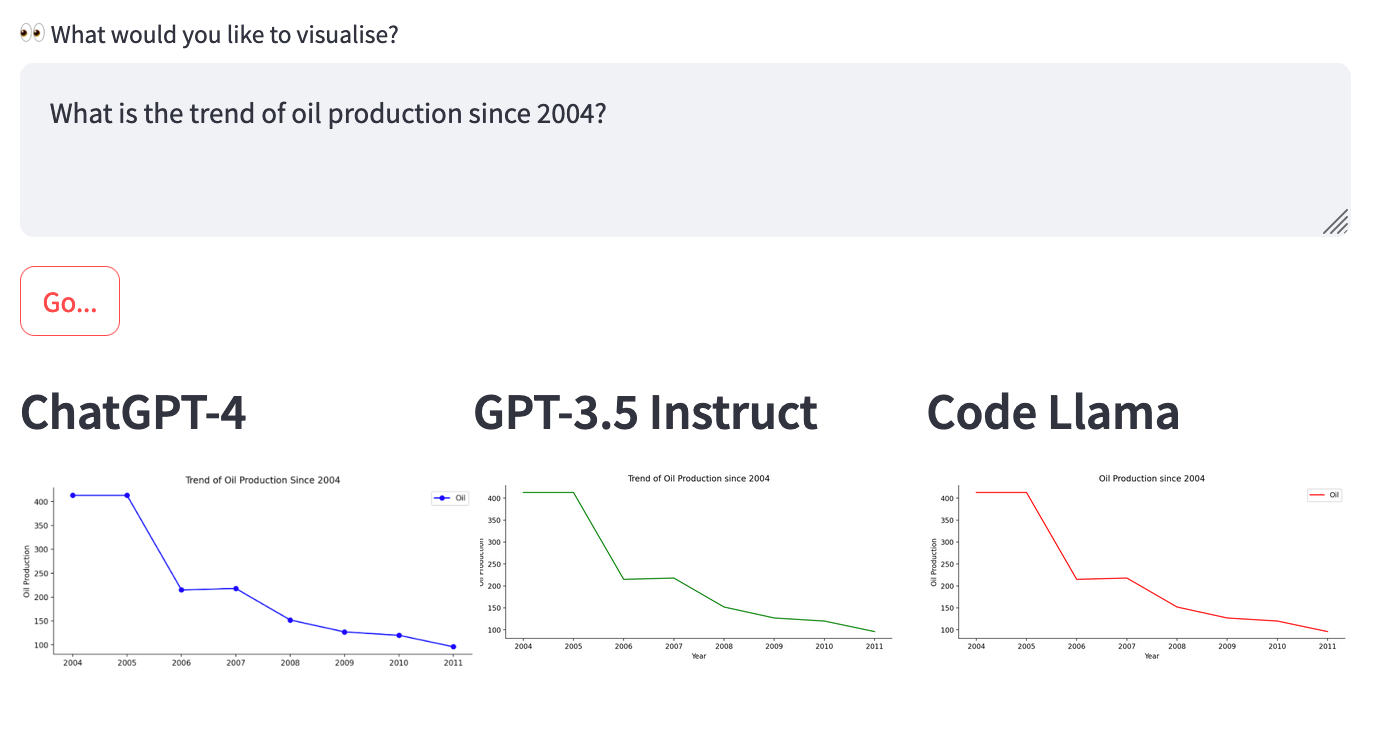
Results
Impressive! All three models generated almost identical plots, showing data from 2004 onwards.
- GPT-4 ✅
- Code Llama ✅
- GPT-3.5 Instruct ✅
Case study 3: Plotting request with an unspecified chart type
Here, I’m using the pre-loaded "Colleges" dataset in the sidebar radio button.
Run the query: "Show debt and earnings for Public and Private colleges."
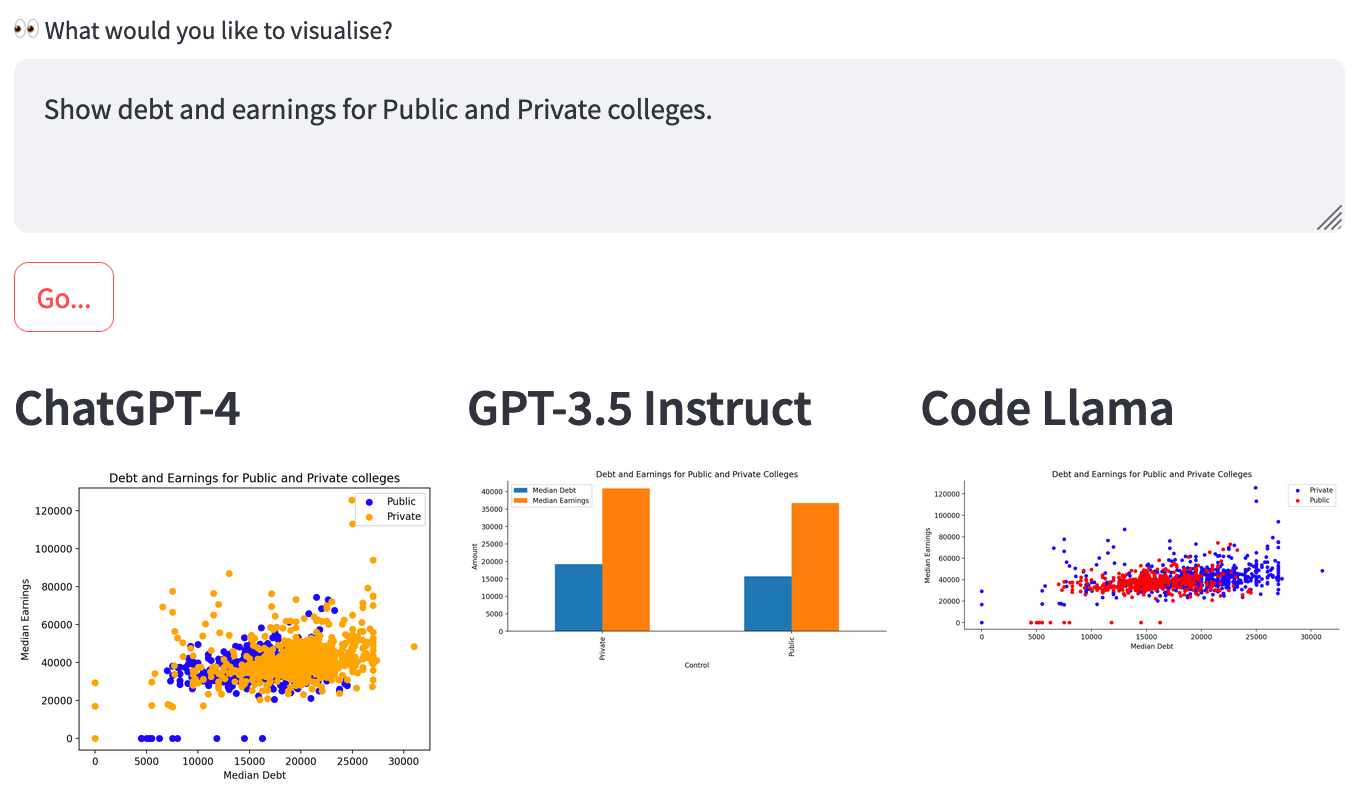
Results
- GPT-4 ✅
- Code Llama 🤔
- During the initial runs of this example, I discovered that Code Llama had some limitations similar to other legacy OpenAI models. It repeatedly attempted to generate scatter plot code assigning invalid values to the function’s c parameter, as also mentioned in this article. As a result, the code failed to execute. To improve its success rate, I made a slight adjustment to the prompt (for the exact wording, delve into the prompt engineering within this code).
- GPT-3.5 Instruct 🤔 plotted average values, maybe not quite as informative as the other models.
Case study 4: Parsing complex requests
Let's examine a more complex example where the models need to select a subset of the data. Using the Customers & Products dataset, run the query: "Show the number of products with price higher than 1000 or lower than 500 for each product name in a bar chart, and could you rank y-axis in descending order?”
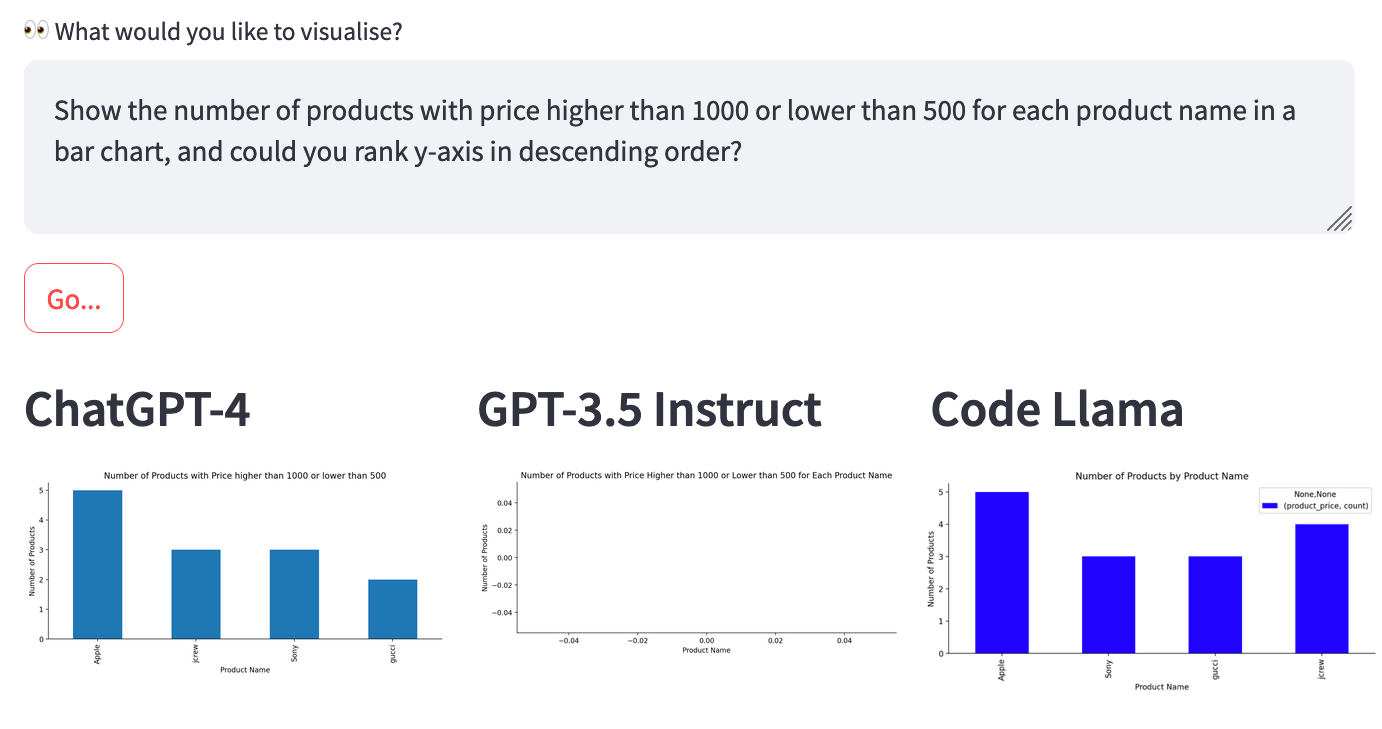
Results
- GPT-4 succeeded in this case ✅
- GPT-3.5 Instruct produced an empty plot ❌
- It's surprising that GPT-3.5 Instruct didn't succeed, as this query has previously worked for ChatGPT3.5, GPT-3, and Codex.
- Code Llama also failed ❌ for several reasons.
- It did not filter the data to include only prices higher than $1000 or lower than $500.
- It didn’t sort the data as requested.
- I encountered these kinds of limitations frequently while exploring Code Llama's capabilities.
Case study 5: Misspelled prompts
Returning to the "Movies" dataset, let's see how Code Llama handles misspelled words. Run the query: “draw the numbr of movie by gener.”
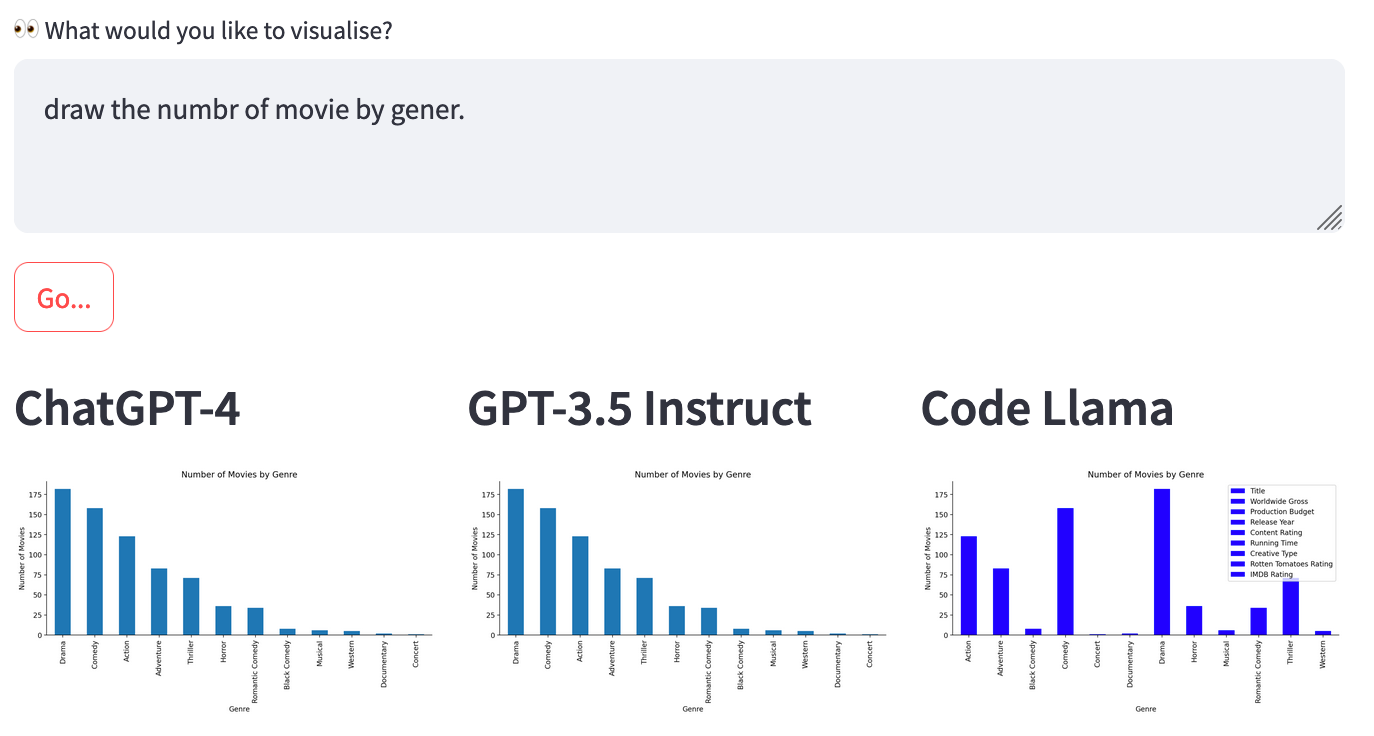
Look at that! Each model overlooked my spelling mistakes!
- GPT-4 ✅
- GPT-3.5 Instruct ✅
- Code Llama ✅
- While it didn’t sort the results in the same order as the OpenAI models, the prompt didn't specify any sorting.
- Code Llama, that uninformative legend is not very helpful!
Case study 6: Ambiguous prompts
Continuing with the "Movies" dataset, let's submit the single word “tomatoes” and observe how the models process it.
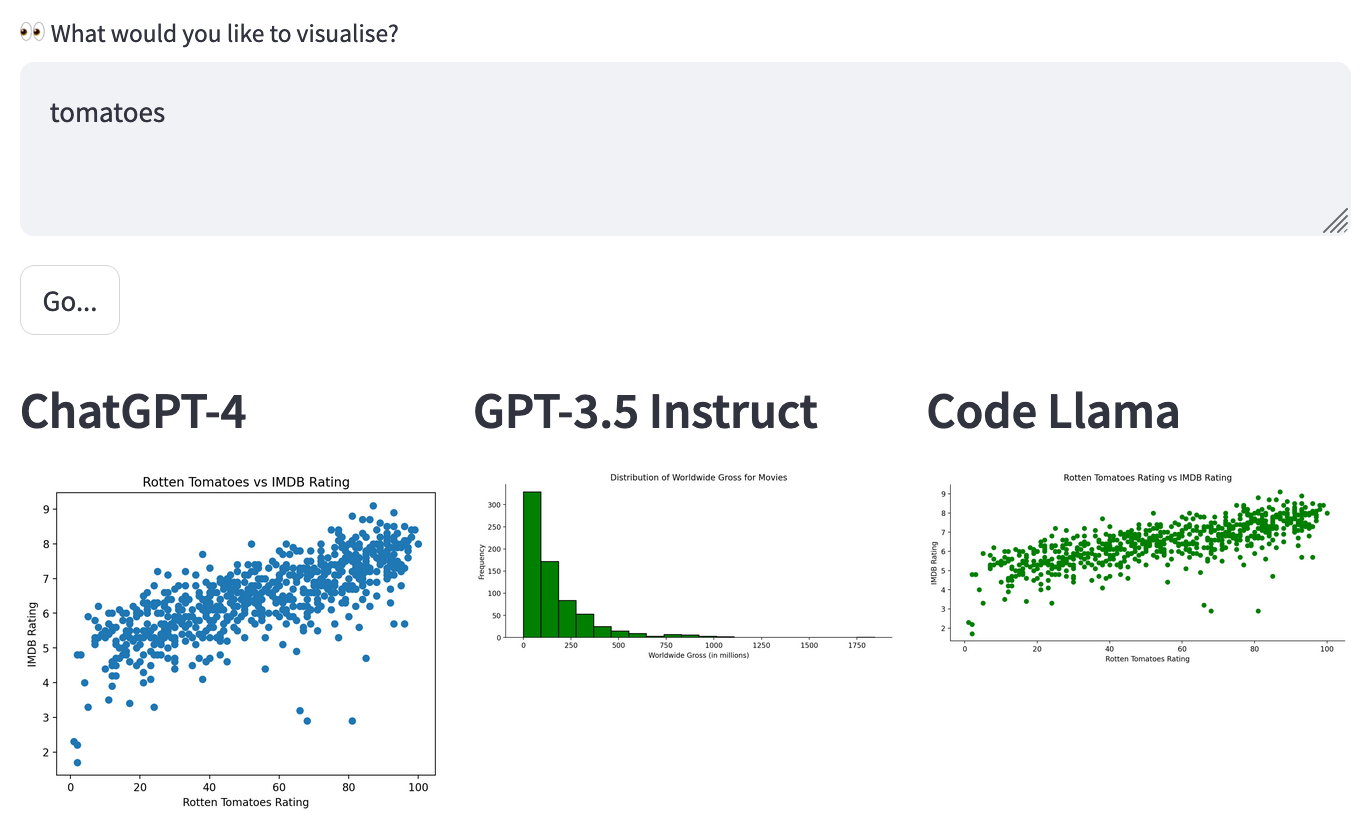
Results
- GPT-4 ✅
- Code Llama ✅
- GPT-3.5 Instruct ❌ This model did not identify a relevant “tomato” visualisation to the movie data set.
How to improve success with open-source models
I have compared the performance of Code Llama, GPT-3.5 Instruct, and ChatGPT-4 using examples from published research previously showcasing ChatGPT-3.5, GPT-3, and Codex.
Initial experiments show promise, but the OpenAI models still outperform Code Llama in several scenarios. I encourage you to experiment and share your opinions.
In the future, I plan to enhance the prompt further and explore various other prompting techniques to potentially improve Code Llama's accuracy. Although I want to avoid overcomplicating the instructions, I acknowledge its potential for improvement.
For this task, considering my prompting style, ChatGPT-4 is my preferred choice.
However, taking into consideration the comparable results of ChatGPT-3.5 in the journal article and previous blog, together with the lower cost of the GPT-3.5 models (costs here), I would ultimately still choose ChatGPT-3.5. Nonetheless, it may be worthwhile to fine-tune a Code Llama model to further explore its capabilities, as it offers a cost-effective solution for Chat2VIS.
Wrapping up
Thank you for reading my post!
I’d love to hear your opinions and the outcomes of your experiments. If you have any questions, please post them in the comments below or contact me on LinkedIn.
Happy Streamlit-ing! 🎈


Comments
Continue the conversation in our forums →