
Hey, community! 👋
My name is Gaurav Kaushik, and I’m the Co-Founder of ScienceIO.
Since 2019 we’ve been working on a model that could accurately mine medical records for critical patient information.
In the past, finding key medical conditions, procedures, and therapies required a fleet of models. We wanted to replace it with an elegant system that could be easily trained, deployed, and fine-tuned. But we needed hundreds of millions of training data labels!
It took us a year to create a training dataset for large healthcare language models with over 2.3 billion labels—the most expansive and comprehensive in existence. Yes! Then a new issue came up. 😩 Could these models understand billions of rows of data, perform quality control, and plan data improvements? We got to work and developed a Streamlit + Snowflake search engine to see what was in our data, what wasn’t, and how we could improve it.

In this post, I’ll share with you why we turned to Streamlit + Snowflake and how you can build your own working example to search for papers from a database of COVID-19 research papers. You’ll learn:
- How to query billions of rows of data
- How to set up a search engine
- How to build a fully working app example
Let’s get started.
How to query billions of rows
The usual business intelligence (BI) tools wouldn’t allow us to ask a question, test a hypothesis, or create a new look at the data (and repeat this process). That’s why we built a Streamlit + Snowflake search engine. We went from question to answer much faster!
Streamlit really came to life after being paired with a global data platform like Snowflake. We could store and query billions of rows of data in Snowflake. But it’s the Streamlit apps that let us investigate it—write queries, build dashboards, and ask and answer questions fast.
To better understand 2.3 billion labels for training large language models, we built a multi-page Streamlit app. Each page has a different data view or a way to search it:
- Concept search: Search for labels that relate to a particular medical concept (specific medical condition or drug).
- Text search: Search for specific words or phrases that are tagged as a label.
- Counts: Provide a dashboard with summary statistics of the whole dataset.
By combining Streamlit and Snowflake into a single application, we could add new views, data analyses, and new search capabilities to be served in minutes:

Streamlit’s text bar is connected to a query that runs on a data warehouse like Snowflake. The status bar feature lets the user know their search is running (a query on billions of rows can take up to a minute).
How to set up a search engine
Streamlit components make it easy to put together a text-based search engine:
import streamlit as st
# app title
st.title("Text Search 📝")
# search box
with st.form(key='Search'):
text_query = st.text_input(label='Enter text to search')
submit_button = st.form_submit_button(label='Search')
In five lines of code, we imported the Streamlit package, gave our app a title, and set up a search box. Next, we needed our app to do something when we clicked the button. So we set up a spinner for the user to see that a search was happening while we retrieved the results:
if submit_button:
with st.spinner("Searching (this could take a minute...) :hourglass:"):
# cool search stuff happens here
Once the spinner was done, we used success to show that the search was complete:
st.success(f"Search is complete :rocket:")
Not everyone on our team knows Python or how to query and visualize data, but they rely on this information to help customers or build new tools. The Streamlit search engine gives them a simple place to get what they need and start building. Over time, this freed up our data scientists to work on other high-value projects.
How to build a fully working app example
To show how to include real search logic in an application, we’ve created a repo using the NCBI COVID-19 literature database. In this fully working example, we demonstrate how to load a dataframe of articles, search for keywords in the titles, and display the results:
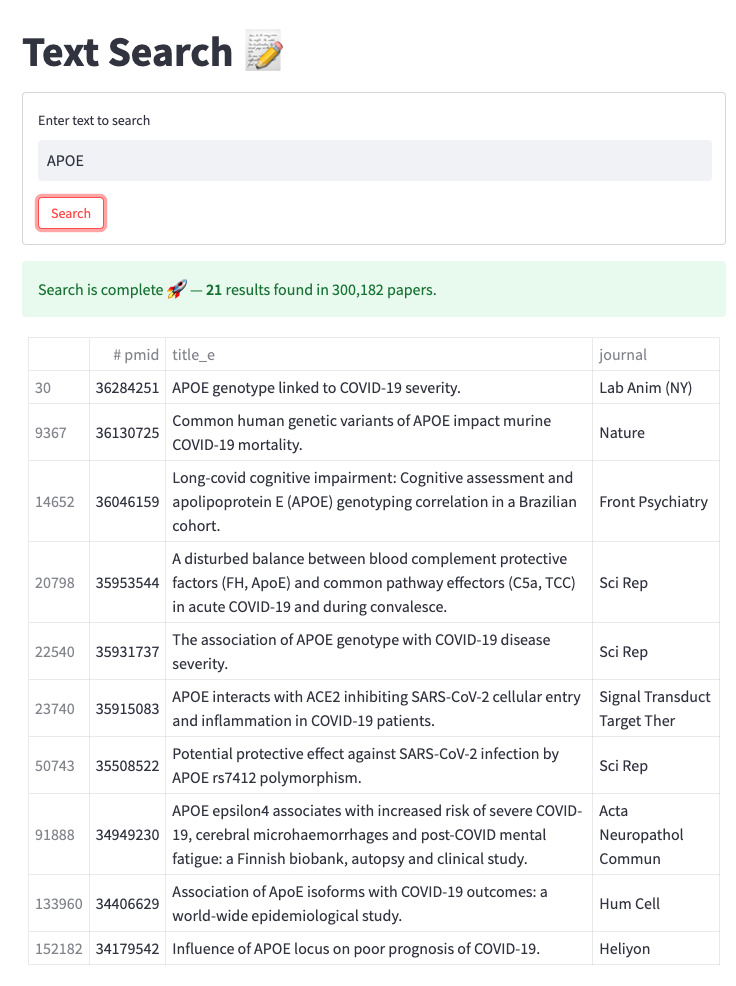
First, we load a TSV as a dataframe and cache the data:
@st.cache
def load_data(filepath:str) -> pd.DataFrame:
""" Load data from local TSV """
return pd.read_csv(filepath, sep="\\t", skiprows=33).fillna("")
Next, we create a function to search the dataframe. This is done by checking to see if a column has rows where our search term is a substring:
def search_dataframe(df:pd.DataFrame, column:str, search_str:str) -> pd.DataFrame:
""" Search a column for a substring and return results as df """
results = df.loc[df[column].str.contains(search_str, case=False)]
return results
Finally, we want to load the data once the application starts:
# env variable
DATA_FILEPATH = "litcovid.export.all.tsv"
# within app(): load data from local tsv as dataframe
df = load_data(DATA_FILEPATH)
Now when we click on st.form_submit_button, we’ll run the search, notify the user of the number of results found, and display the first ten hits:
# if button is clicked, run search
if submit_button:
with st.spinner("Searching (this could take a minute...) :hourglass:"):
# search logic goes here! - search titles for keyword
results = search_dataframe(df, "title_e", text_query)
# notify when search is complete
st.success(f"Search is complete :rocket: — **{len(results)}** results found")
# now display the top 10 results
st.table(results.head(n=10))
One of the best features of Streamlit is interactive plotting and visualization. At ScienceIO, we love to use Altair plots which are easily converted from static to dynamic. Let’s add an interactive bar plot that shows the top journals in our search results.
# we can use altair to turn our results dataframe into a bar chart of top journal
import altair as alt
alt.Chart(results).transform_aggregate(
count='count()',
groupby=['journal']
).transform_window(
rank='rank(count)',
sort=[alt.SortField('count', order='descending')]
).transform_filter(
alt.datum.rank < 10
).mark_bar().encode(
y=alt.Y('journal:N', sort='-x'),
x='count:Q',
tooltip=['journal:N', 'count:Q']
).properties(
width=700,
height=400
).interactive()
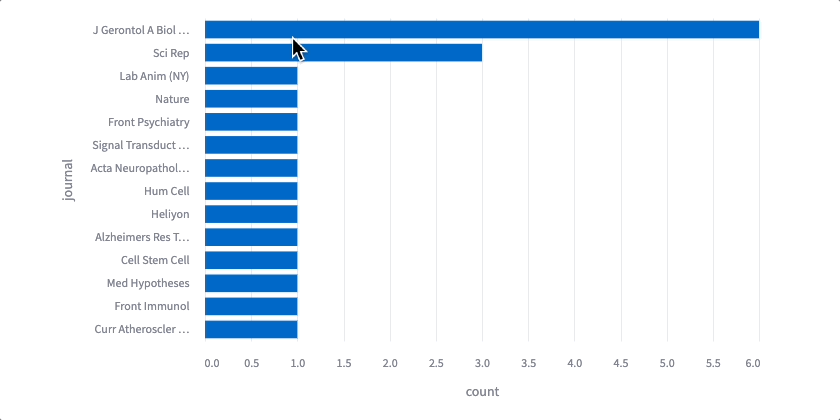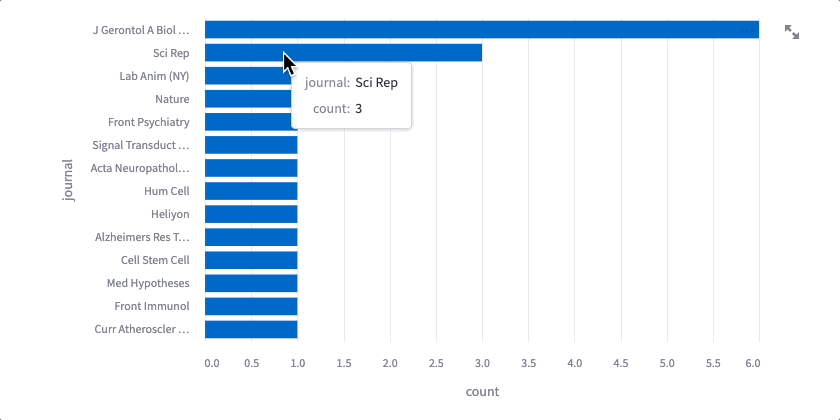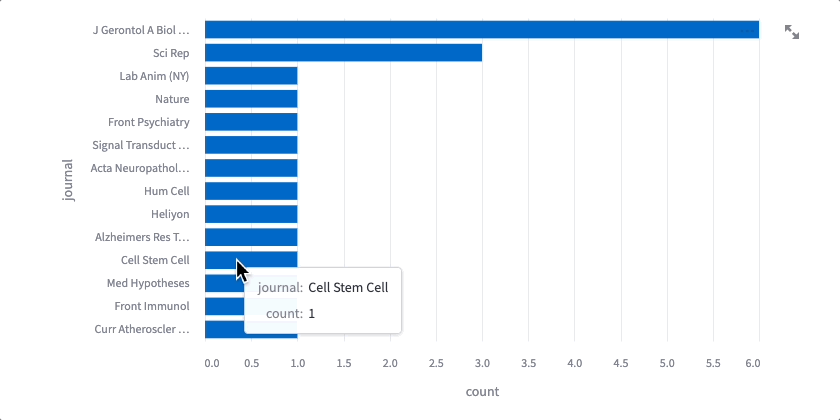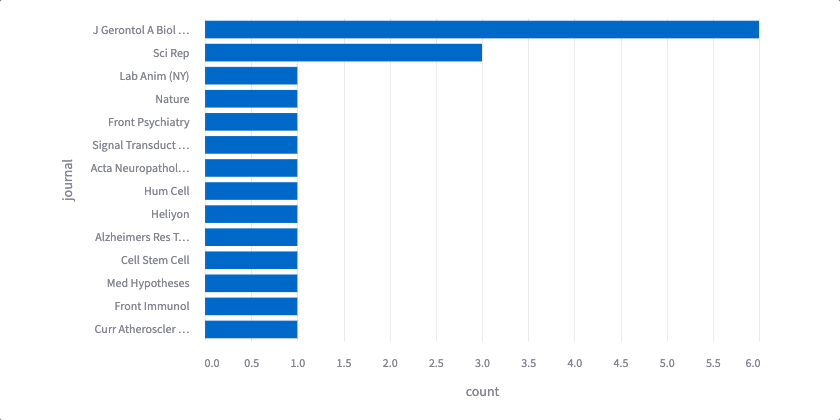
The code might seem intimidating, but don’t worry. You got this! Altair lets you chain functions together to make changes to data and charts that are each straightforward. The first set of functions aggregate, sort, and filter the data — transform_aggregate() groups the results and counts the number of times each value appears; transform_window() ranks/sorts each row by its count; transform_filter() removes all rows below a certain rank (for example, below 10th place). Now that our data is appropriately transformed, we can plot — mark_bar() creates a bar chart, we declare our x- and y-axes and a tooltip with encode(), and we can specify chart width and height using properties(). Finally, we add interactive() — now, we can hover over each bar to see the journal and the total number of publications that match your search terms.
And now we have a fully working example app of search app. In this example, we use a basic dataframe, but you can replace that with anything—a database, a data warehouse, or an API call. The only limit is your imagination!
You can find the code for this app on GitHub and try the app yourself here.
Wrapping up
Now you know how to set up a search tool with Streamlit! We hope you better understand how Streamlit applications can act as fast and flexible tools on top of large datasets and that you’ll build more cool things and share them in turn with the community!
If you have any questions or want to learn more about industrial-scale AI for healthcare, please post them below.
Happy coding! 🧑💻



Comments
Continue the conversation in our forums →