
Hey, community! 👋
My name is Sebastián Flores. I’m a Chief Data Officer at uPlanner and a Streamlit Creator.
At uPlanner, we develop cloud solutions to help higher education institutions be more efficient on Smart Campus, Academic Management, and Student Success. Most institutions use our standard data processing, but sometimes we need to create client-custom scripts for the data to be correct, consistent, and in the right format. This can turn into a nightmare as these scripts are hard to maintain and complicate the whole process.
So in this post, I’ll show you how Streamlit makes it easy and how you can build an app with a simple frontend for previously created scripts.
TL;DR? Check out the app and the repo.
Let’s get started.
Simplifying user experience
Not everyone knows how to run a Python script—or how to install it. If you work with multiple data files, using the terminal to process files can be error-prone. And updating the scripts can be tedious. Oh, the anxiety of Git conflicts!
We used to pass the clients’ files to implementation engineers, then to data engineers. The data engineers executed the scripts on the inputs and returned the outputs. This took a lot of back-and-forth communication.
Streamlit allows you to create a frontend for your code. Clients can see if their data meets all the requirements. And they see it in a familiar interface: a website. All the hard parts—installation, versioning, data processing—are hidden behind a beautiful UI.
And the best part?
It’s super-fast to develop. Streamlit has a huge collection of useful input and output widgets so even junior engineers can produce stunning pages in no time.
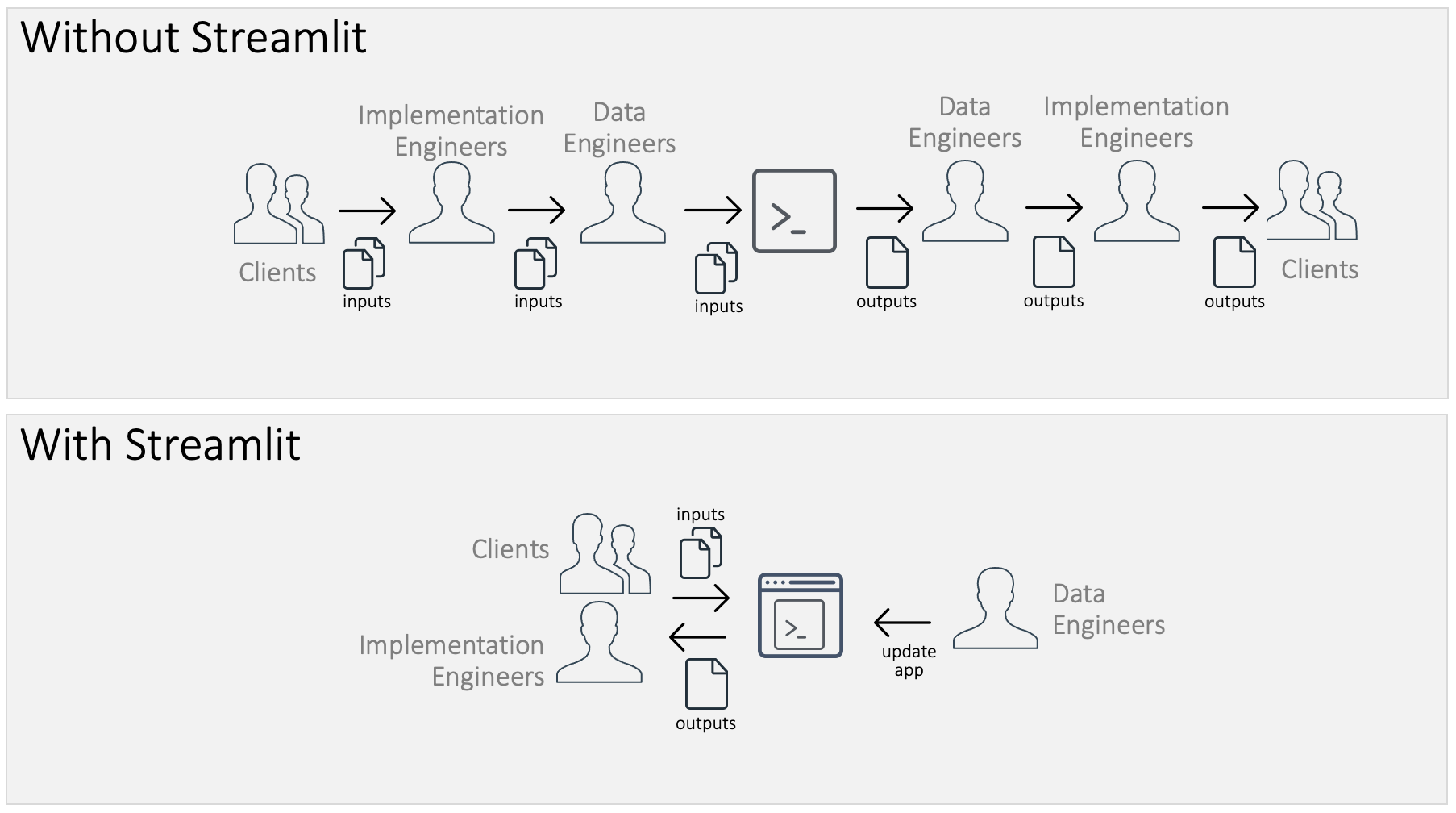
How we did it
Our first Streamlit app allowed the users to pick between six different data processing scripts. Yay to multipaging! The scripts had very different interfaces, but they made the utilization intuitive and easy to follow.
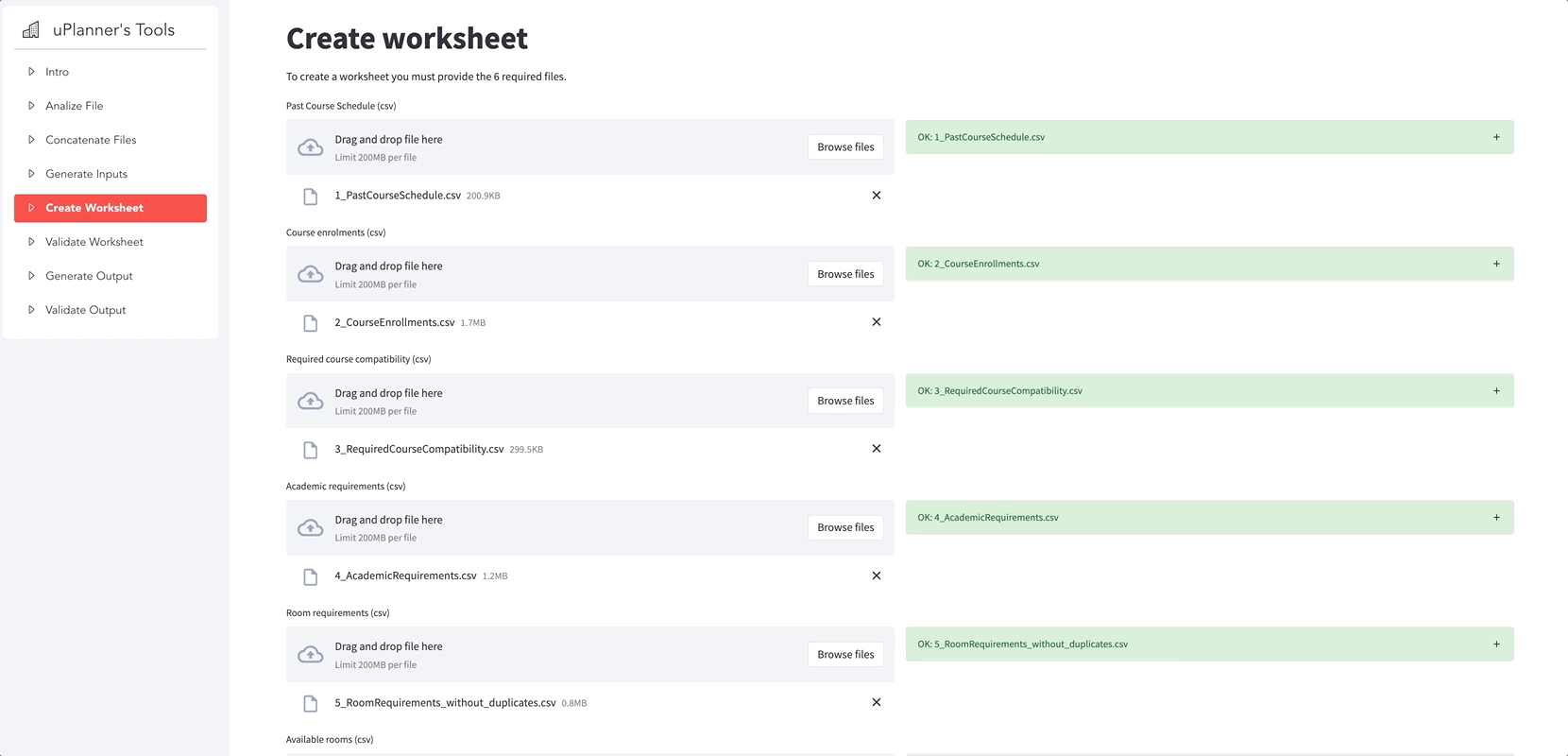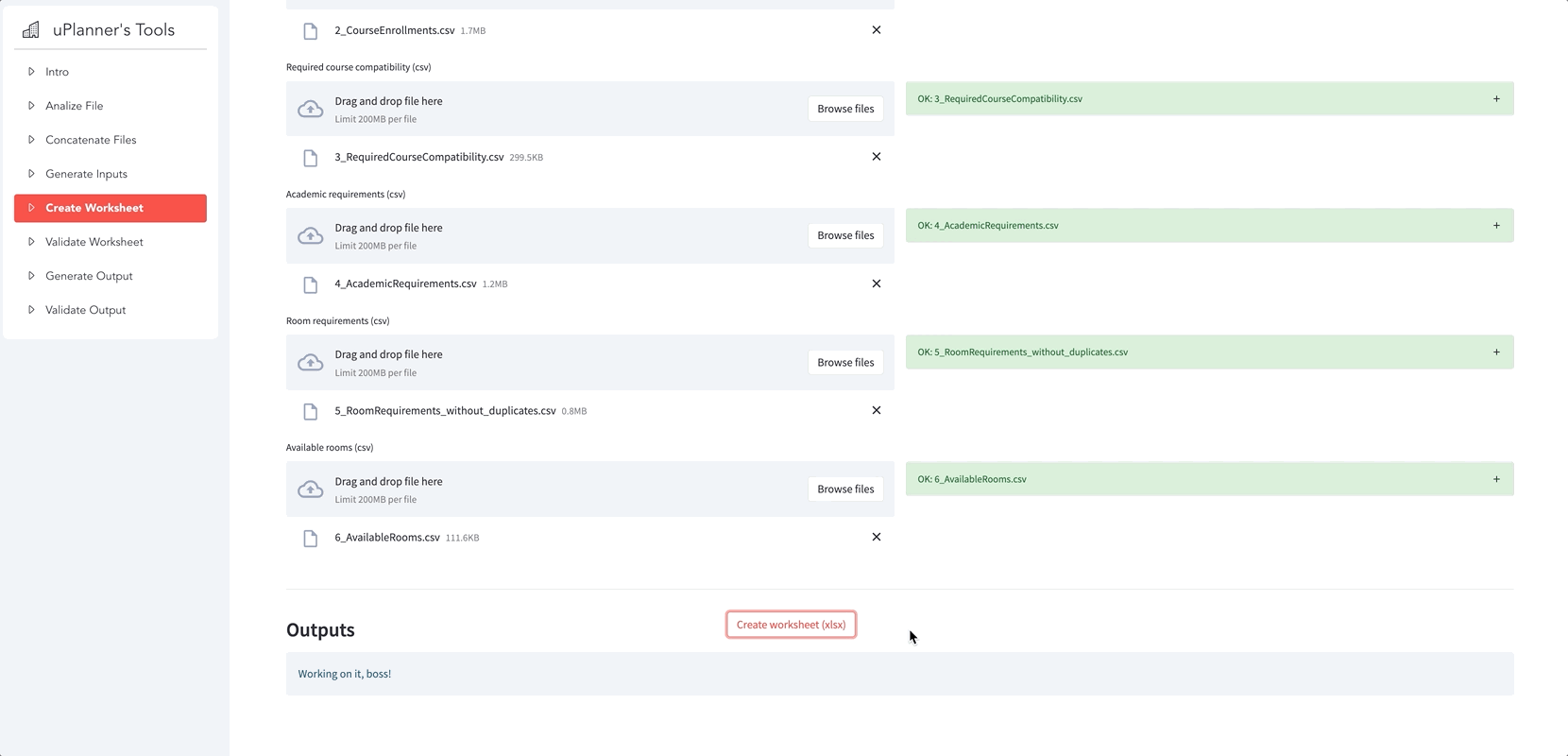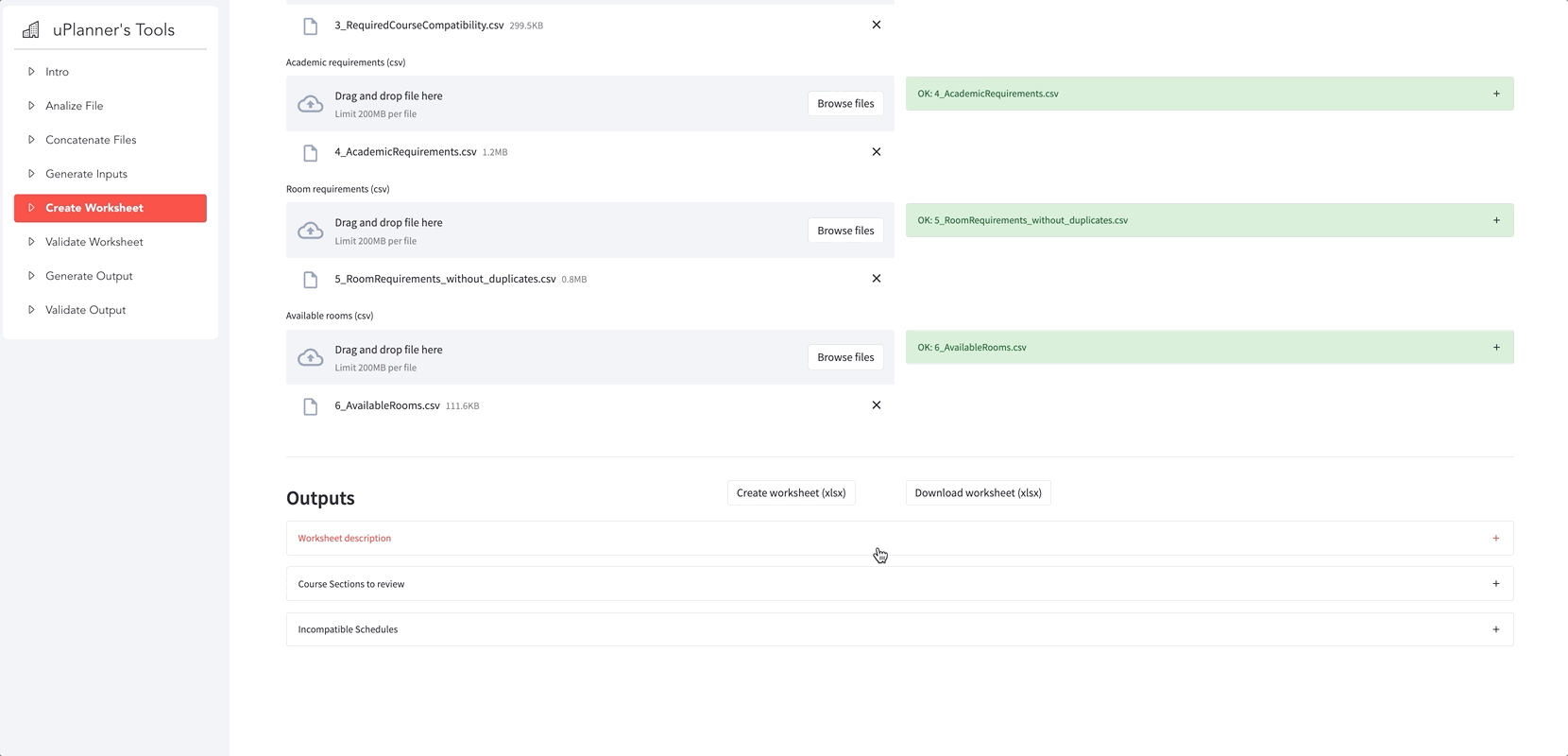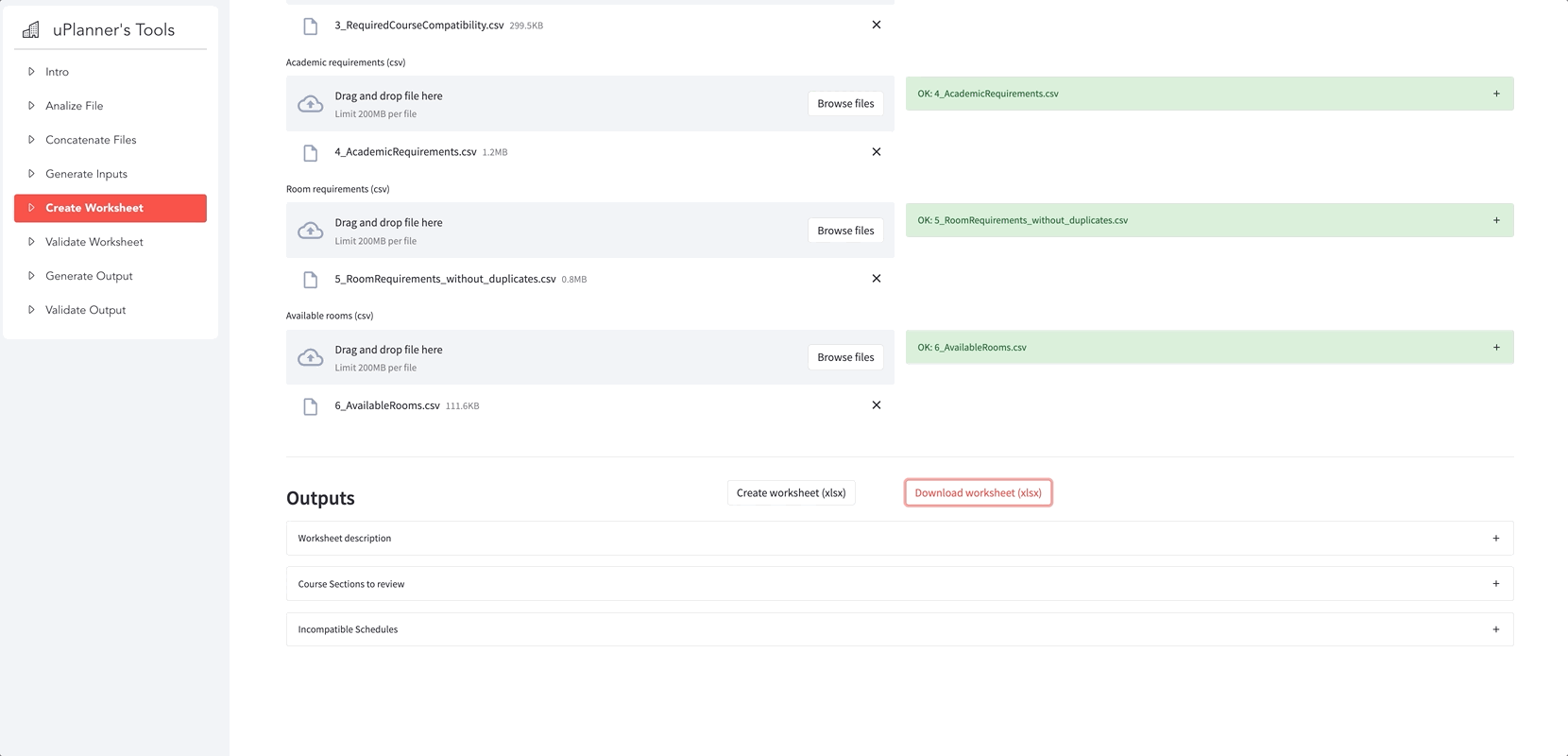
Here are some of the app’s general functionalities:
- Convert CSV files to Excel and back to CSV
- Analyze a CSV or an Excel file
- Move an uploaded file to an SFTP
- Extract and merge data from different tables and databases
- Verify file structure and content
- Generate a specific output file, to be uploaded to third-party software
Script adoption and development are much easier with the app as a single point of access. Everyone is happy with more time and autonomy!
A smaller but editable example
Due to privacy, I’m sharing a simplified version of the app that illustrates the main concepts. The app can:
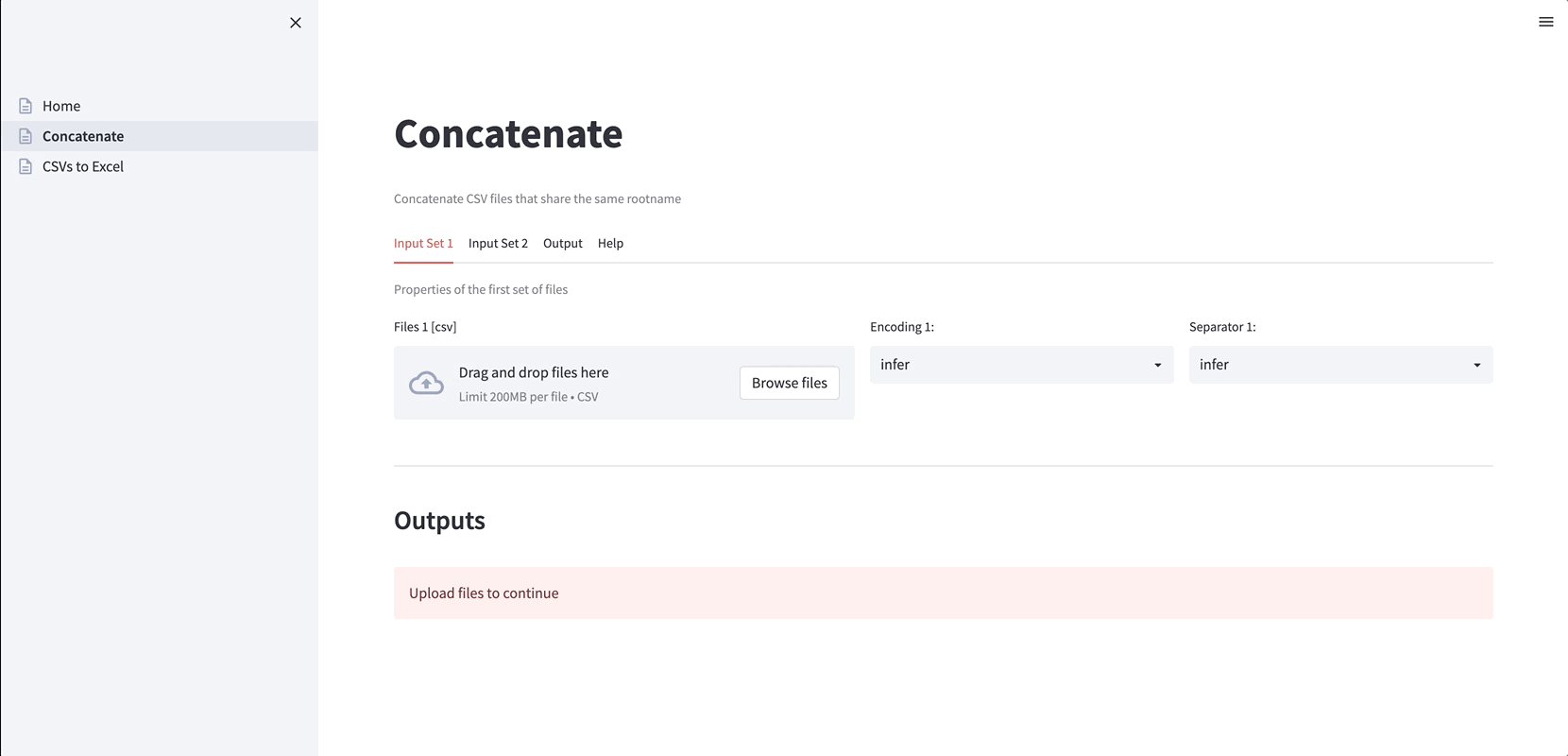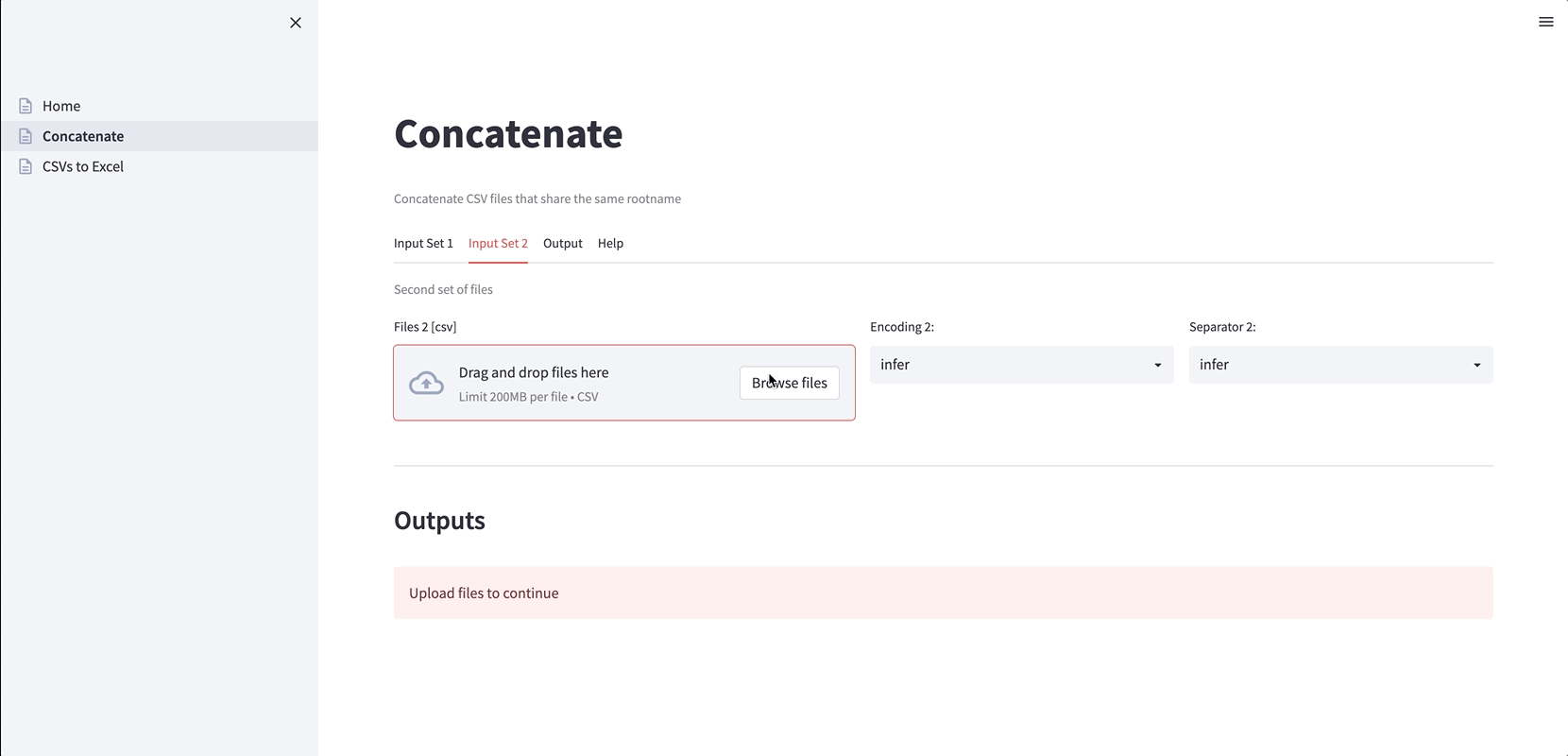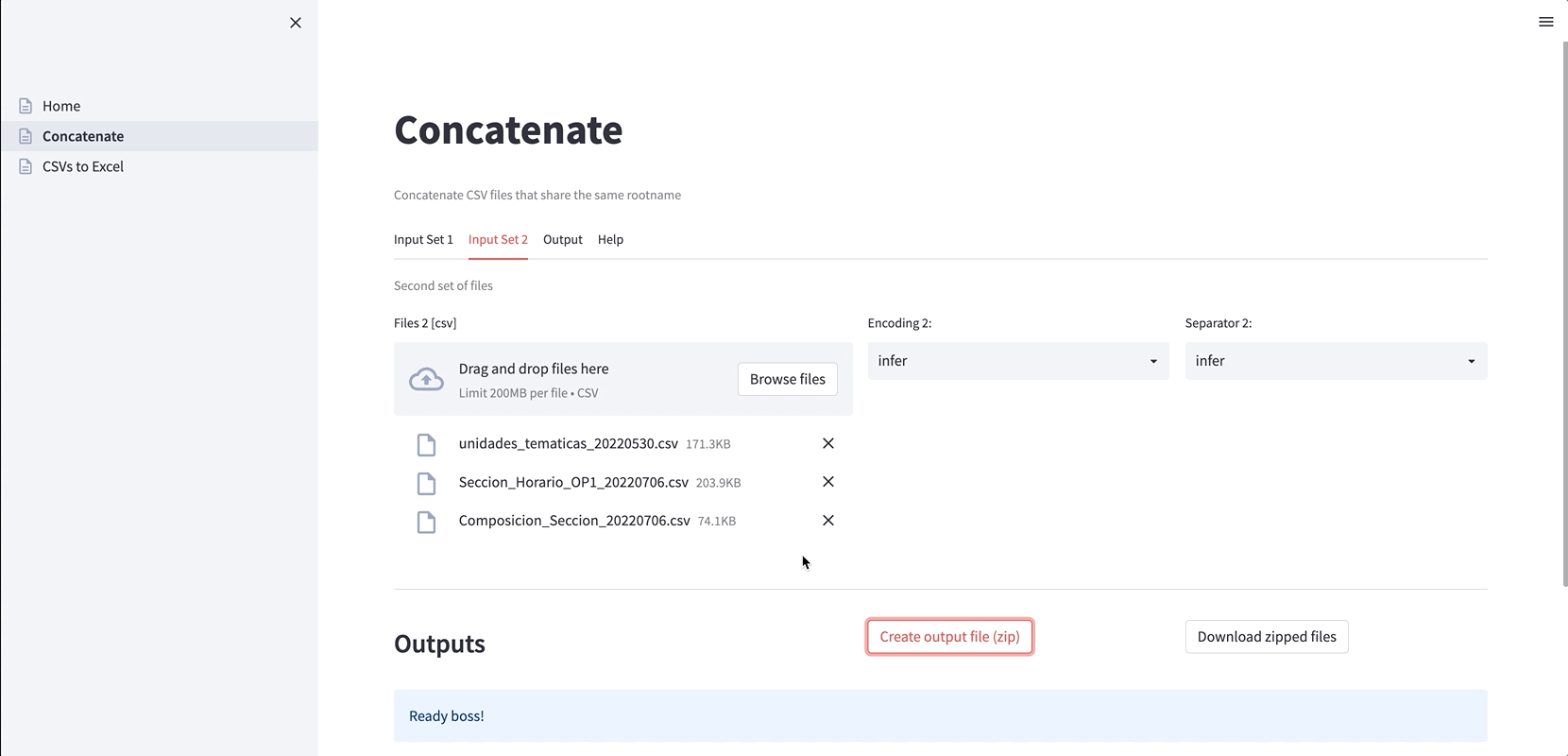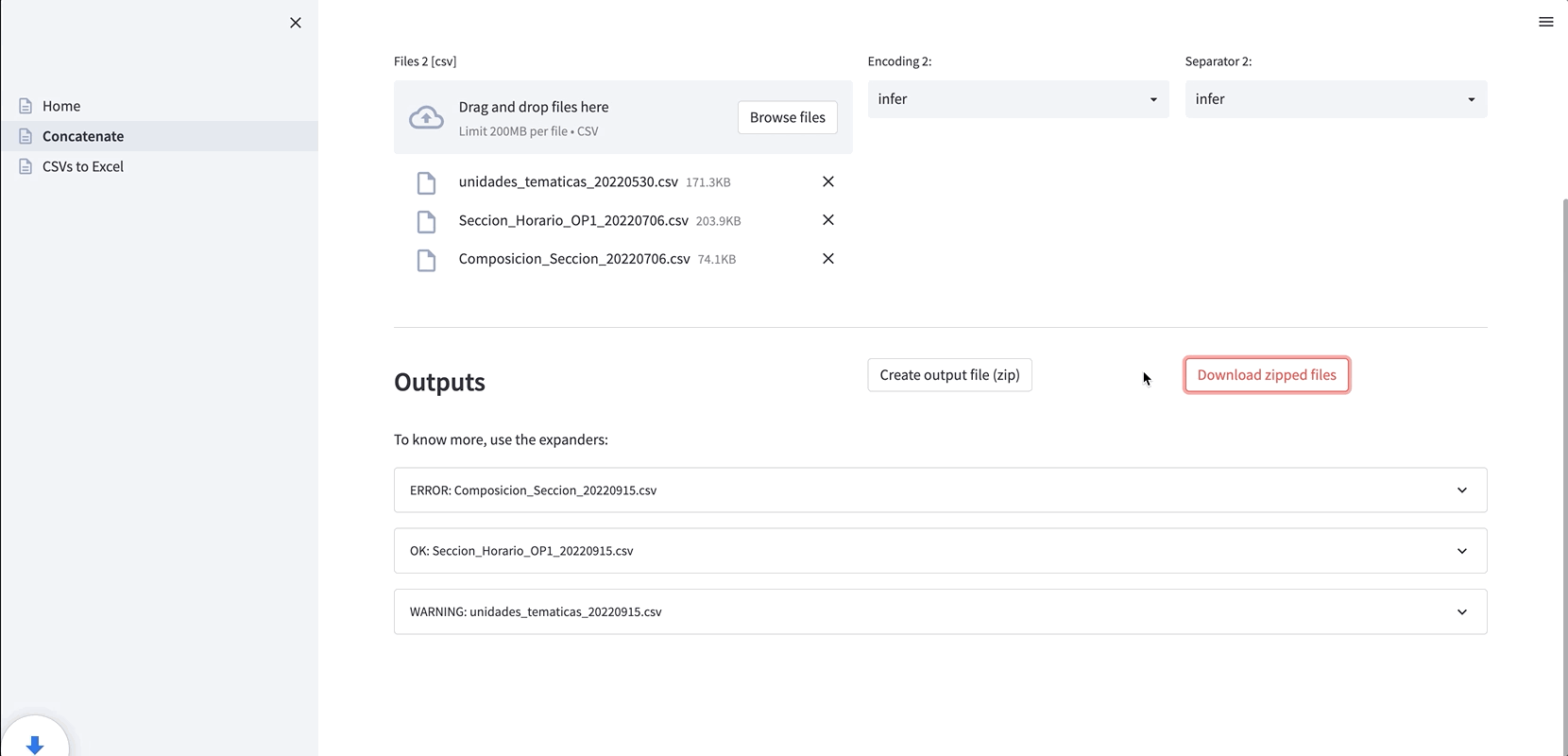
1. Concatenate files that are produced on different days (useful when new data is generated daily or from different sources). By default, the file encoding and the column separator are individually inferred, but users can choose any specific setting:
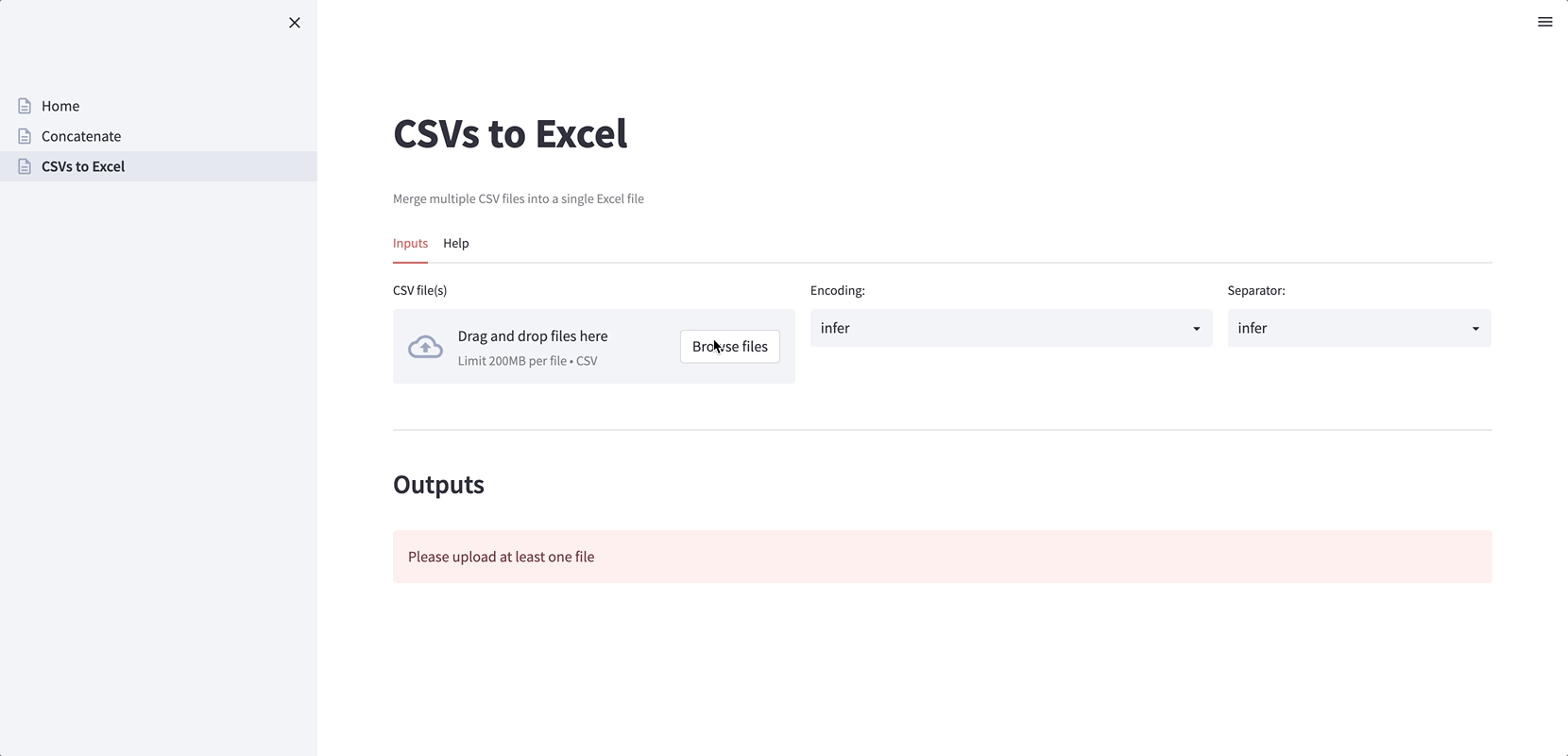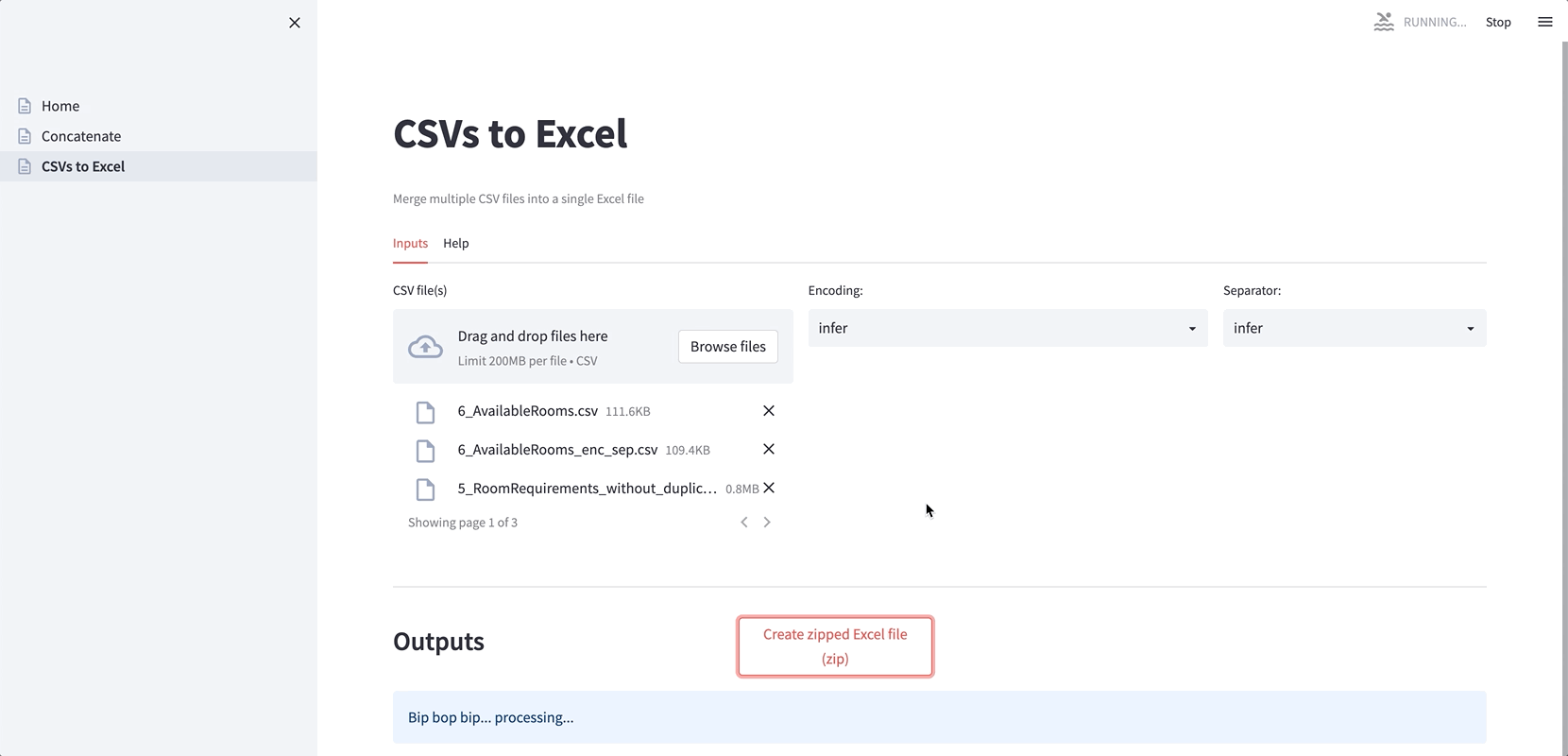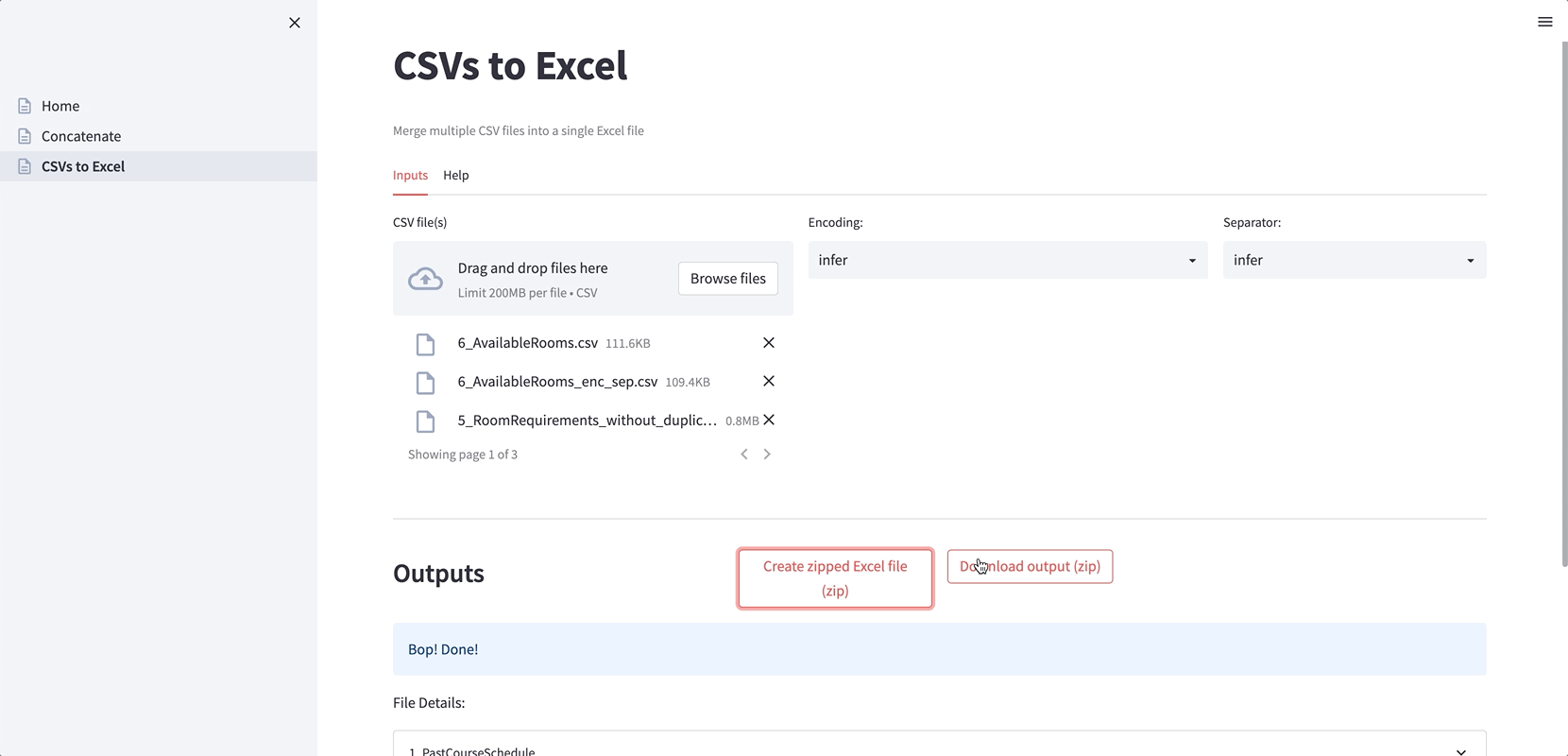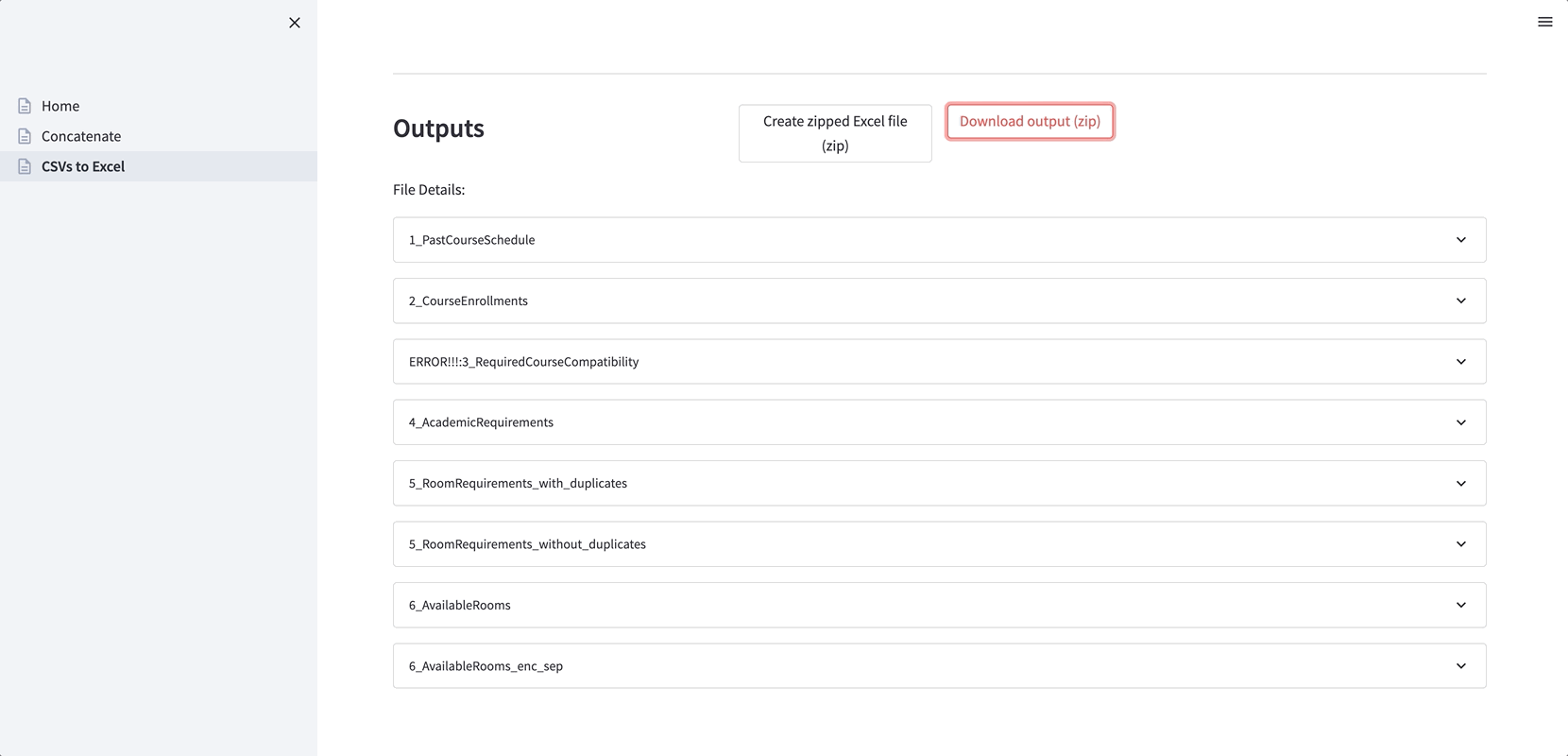
2. Convert CSV files to Excel files (handy when the CSV files have different encodings and separators). Again, the encoding and the separator can be inferred or specified:
Here is the app’s file structure:
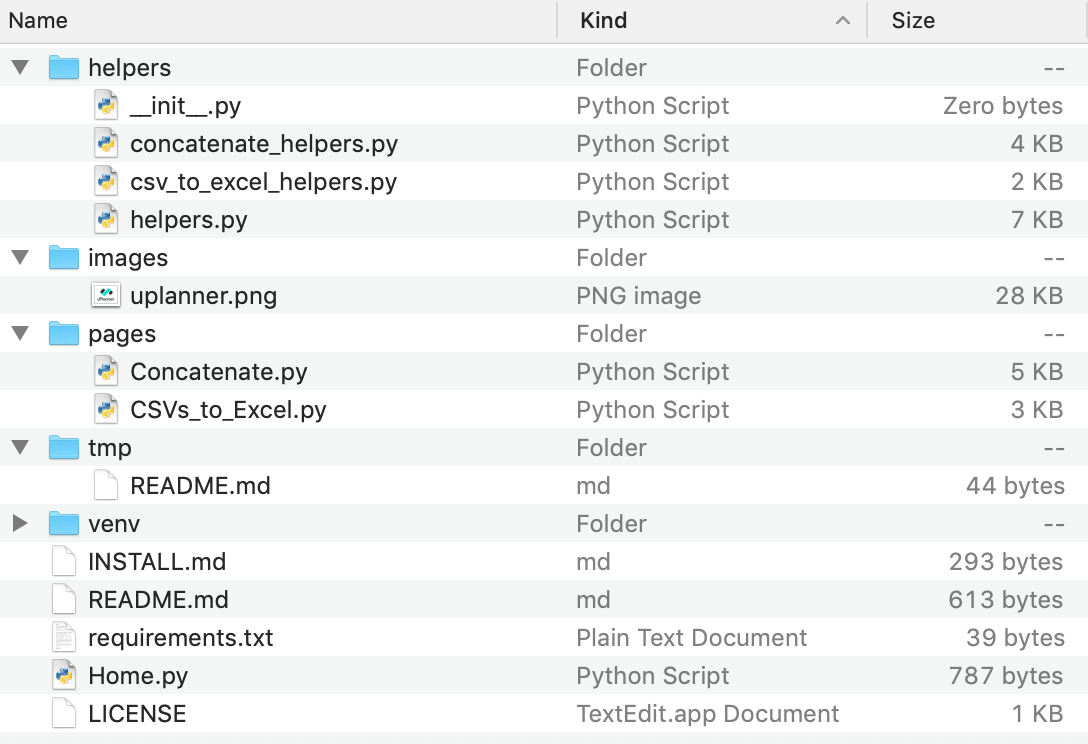
Put your regular Python scripts for transforming data into the folder “helpers.” And don’t forget to include a __init__.py to import them from the Streamlit scripts. It should be as easy as:
from helpers.concatenate_helpers import concatenate_files
The other folders and files that turn the scripts into an app are:
- The file Home.py is the app’s entry file (rename it as you see fit or add emojis!).
- The “images” folder is for any pictures you want to display.
- The “pages/” folder is for different pages so you can use multipaging. Mine are “Home” (from “Home.py”), “Concatenate,” and “CSV to Excel” (notice how Streamlit replaces the "_" with spaces when displaying the page name).
- The “tmp” folder is for temporary files (before users download them).
- INSTALL.md, README.md, and LICENCE are the standard files for installation, help, and copyright.
requirements.txtis the list of required libraries.
Learning from the building experience
The most important lesson we’ve learned from creating apps is to give direct and clear feedback to the app user as soon as possible. Most of our scripts deal with file processing by displaying warning, error, and success messages from the files’ execution. Additional information is always welcome: filetype, encoding, number of rows and columns, or data distribution.
We also check the expected content:
- Are all the required columns on file? Let the user know what columns they’re missing.
- Do we have duplicated rows? Show the user the precise rows that need revision!
- Is the data consistent across multiple files? Explain in simple terms what isn’t matching correctly.
Providing feedback as soon as you can helps users correct the information and avoid frustration. There’s nothing worse than doing 10 steps and then learning you had an error on step one!
Wrapping up
Thank you for reading my article! I hope you take away two main points:
- From a technical perspective, Streamlit lets you put a front-end to Python scripts with a great trade-off: a short development time for a nice interactive interface.
- From a management perspective, Streamlit decouples the development and execution of your Python scripts. This leads to accelerated adoption, innovation, and participation of non-technical users—a win-win for everyone!
If you want to find out more about uPlanner, check out our website and our social channels: LinkedIn, Facebook, and Twitter. And if you have any questions, leave them in the comments below or reach out to me on Twitter at @sebastiandres or on GitHub.
Happy coding! 🧑💻



Comments
Continue the conversation in our forums →